
What is Partitioning?
Partitioning is dividing of stored database objects (tables, indexes, views) to separate parts. Partitioning is used to increase controllability, performance and availability of large database objects.
- In some cases, partitioning improves performance when accessing the partitioned tables.
- Partitioning can play a role of leading columns in indexes, which decreases index’s size and increases the possibility of finding the most sought indexes in the memory. When a big part of one section is used in the resultset, scanning of this section can be performed much faster than an occasional access to the data spread across all the table by index.
- Massive uploading and deleting of data can be done by adding and deleting sections, which helps to increase the performance.
- Rarely used data can be uploaded to more cheap data storage devices.
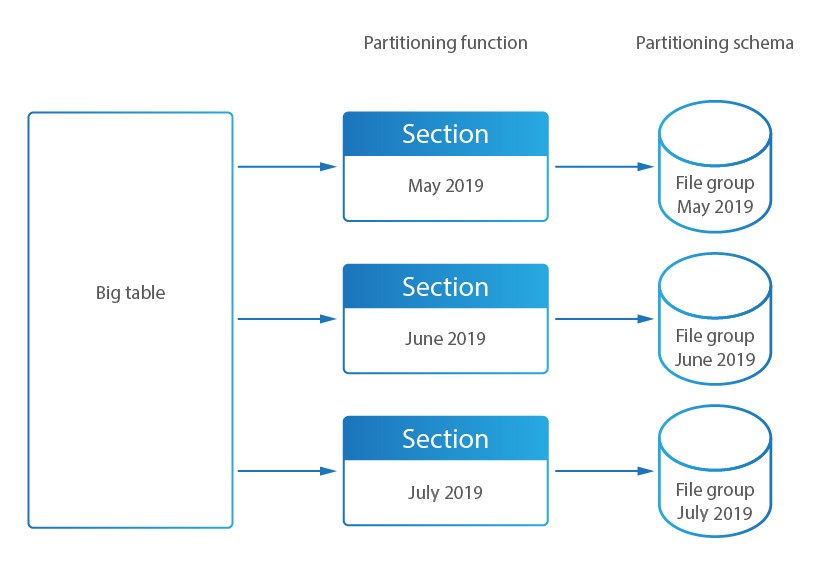
In DataSunrise, partitioning is used for splitting Audit Storage database’s tables to sections (smaller tables). The Audit Storage is a database which is used to store results of the DataSunrise’s Database Activity Monitoring.
- Makes administering of the Audit Storage more simple, because partitioned data is distributed by partitions according to the time of partitioning. The database administrator can disable partition querying, archive them etc.
- Increases performance when accessing, retrieving data, writing data to the partitioned tables;
- Increases performance when deleting obsolete audit data from the Audit Storage;
DataSunrise supports partitioning for the following types of Audit Storage databases:
- PostgreSQL
- MySQL
- MS SQL Server
Partitioning Parameters
Can be found in System Settings -> Additional parameters.
- Partitions Length (days) – partition length, days (if AuditPartitionShort == 1, then minutes). Can be found in System Settings -> Audit Storage. If Partitions Length is changed, all the partitions created in advance would be deleted and new partitions would be created with new Partition Length parameters.
- AuditPartitionCountCreatedInAdvance – number of partitions created in advance. Thus, empty partitions created to be filled in the future. This enables DataSunrise to write data to existing partitions without delays;
- AuditPartitionFirstEndDateTime – date/time of the first partition end. This time is required for adjustment of partition boundaries around “round” value. For example: monday 00:00:00 (for partition length is 7 days).
Partition Management in DataSunrise
DataSunrise includes partition management mechanisms: DataSunrise creates additional tables required for operation (for PostgreSQL), creates and maintains updated partitioning functions, partitioned schemes, file groups and indexes (for MS SQL), modifies keys and indexes to be compliant with partitioning requirements (MySQL), enables partitioning, creates and deletes partitions.
SELECTs are performed through master table. INSERT/UPDATEs are performed directly to partition (except MS SQL Server). This helps to increase writing speed.
Partitions’ and Tables’ Names
Partitions for PostgreSQL are organized as children tables named <table_name>_p<datetime>, where <table_name> is master table, <datetime> is the upper boundary partition time in the following format: YYYYMMDDhhmm.
For MySQL, partitioning is implemented using native mechanisms. Partition names are formed according to the following scheme: p<datetime>, where <datetime> is the upper boundary partition time in the following format: YYYYMMDDhhmm.
For MS SQL Server, partitioning is implemented through scheme.
