Anonimización de Datos en Vertica
La anonimización de datos en Vertica es una capacidad crítica para las organizaciones que dependen de análisis a gran escala mientras procesan información personal, financiera o regulada. Vertica está diseñado para cargas de trabajo analíticas de alto rendimiento, lo que lo hace ideal para informes de BI, análisis de clientes y ciencia de datos. Al mismo tiempo, esta flexibilidad analítica incrementa el riesgo de que valores sensibles puedan aparecer en resultados de consultas, exportaciones o sistemas posteriores si no están debidamente protegidos.
En entornos modernos de Vertica, múltiples equipos y herramientas suelen acceder a los mismos conjuntos de datos. Los analistas exploran datos de manera interactiva, los paneles de BI ejecutan consultas programadas y los pipelines de aprendizaje automático extraen grandes conjuntos de datos para entrenamiento. Debido a que estas cargas de trabajo operan sobre tablas compartidas, las organizaciones deben garantizar que los atributos sensibles permanezcan protegidos sin interrumpir los flujos analíticos ni duplicar datos.
Este artículo explica cómo se puede implementar la anonimización de datos en Vertica mediante la aplicación centralizada, técnicas de anonimización dinámica y auditoría continua, con DataSunrise Data Compliance actuando como capa de protección.
Por Qué Es Necesaria la Anonimización de Datos en Vertica
La arquitectura de Vertica prioriza el rendimiento analítico. Los datos se almacenan en contenedores columnarios ROS, las actualizaciones recientes residen en WOS y las proyecciones crean múltiples diseños físicos optimizados de las mismas tablas lógicas. Aunque este diseño acelera las consultas, también complica la protección detallada de datos.
En la práctica, varios factores aumentan la necesidad de anonimización:
- Las tablas analíticas amplias combinan con frecuencia métricas con datos PII o de pago.
- Las proyecciones replican columnas sensibles a través de múltiples nodos.
- Los clústeres compartidos soportan herramientas de BI, trabajos ETL, notebooks y pipelines de ML.
- Las consultas SQL ad-hoc evaden las capas de informes curados.
- El RBAC nativo controla el acceso pero no la visibilidad a nivel de valores.
Tan pronto un usuario tiene permisos SELECT, Vertica devuelve todos los valores seleccionados en forma clara. Por lo tanto, las organizaciones requieren mecanismos de anonimización que operen en tiempo de consulta y no dependan únicamente de permisos estáticos.
Para contexto adicional, consulte la documentación oficial de la arquitectura de Vertica.
Arquitectura Centralizada de Anonimización para Vertica
Un enfoque comprobado para la anonimización de datos en Vertica es separar la aplicación de las políticas del almacenamiento. En este modelo, las aplicaciones cliente se conectan a través de una puerta de enlace centralizada en lugar de conectarse directamente a Vertica. Cada consulta SQL es inspeccionada, las reglas de anonimización se evalúan y los valores sensibles se transforman antes de devolver los resultados.
Muchas organizaciones implementan esta arquitectura utilizando DataSunrise como proxy transparente. Debido a que la aplicación de políticas ocurre fuera de Vertica, los esquemas, proyecciones y lógica de la aplicación permanecen sin cambios.
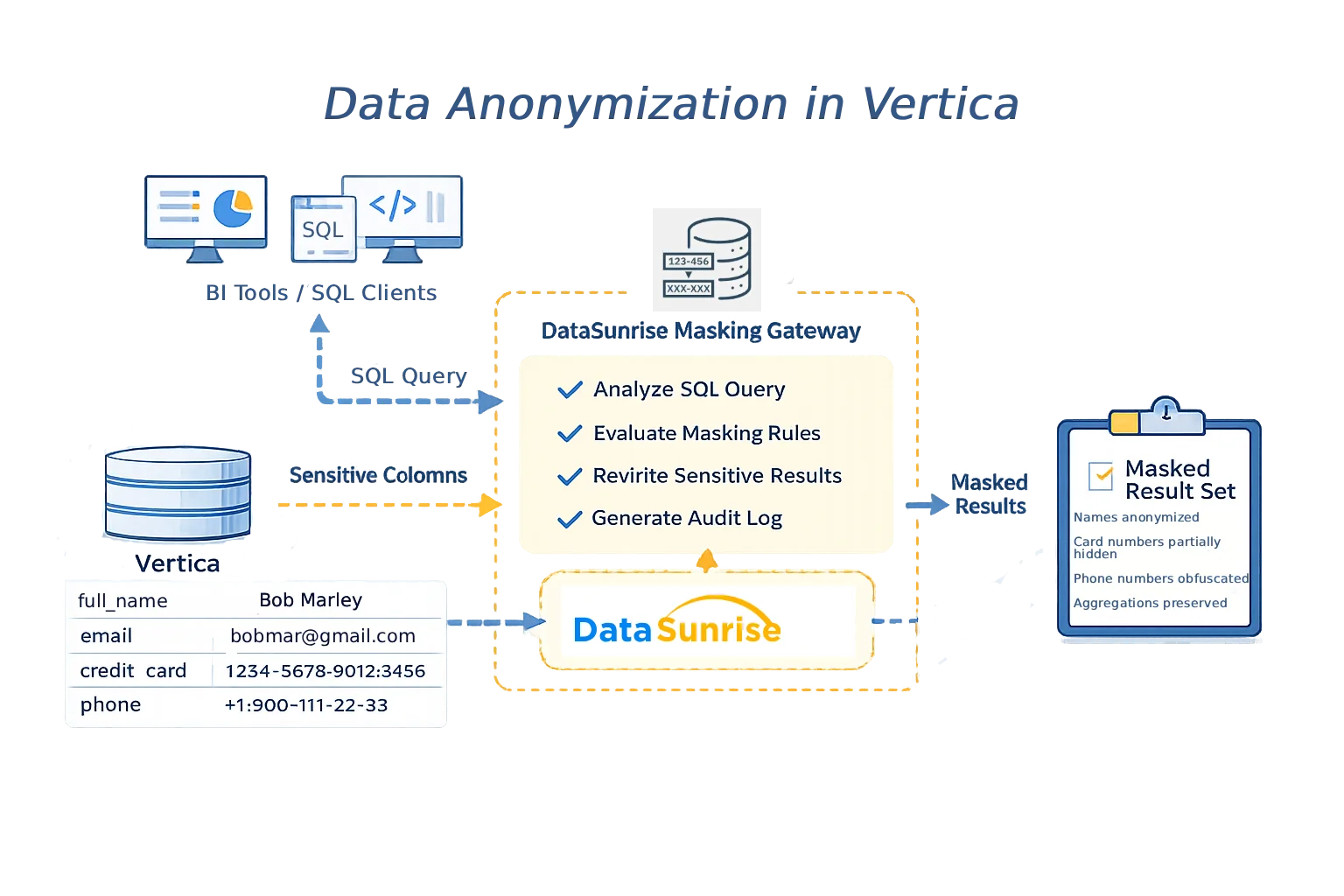
Arquitectura centralizada de anonimización de datos para Vertica con DataSunrise como capa de aplicación de políticas.
Esta arquitectura garantiza que las políticas de anonimización se apliquen uniformemente a través de todos los caminos de acceso, incluyendo clientes SQL, herramientas de BI y pipelines automatizados.
Anonimización Dinámica como Técnica Central
La anonimización dinámica es la técnica más efectiva para proteger datos sensibles en análisis con Vertica. En lugar de modificar permanentemente los valores almacenados, la anonimización ocurre en tiempo de consulta. Cuando una consulta hace referencia a columnas sensibles, los valores devueltos se reemplazan por representaciones anonimizadas.
DataSunrise provee mecanismos incorporados de enmascaramiento dinámico de datos y anonimización que evalúan cada consulta contra reglas de política. Estas reglas pueden considerar:
- Usuario o rol de la base de datos
- Tipo de aplicación cliente
- Entorno (producción, staging, análisis)
- Clasificación de sensibilidad de cada columna
Dado que la anonimización ocurre solo en el conjunto de resultados, Vertica continúa procesando valores reales internamente. Por ende, agregaciones, joins, filtros y cálculos permanecen precisos.
Configuración de Reglas de Anonimización en Vertica
Para aplicar la anonimización, los administradores definen una regla que apunta a una instancia de Vertica y especifica qué columnas requieren protección. Las reglas típicamente hacen referencia a esquemas o tablas identificadas mediante descubrimiento automatizado.
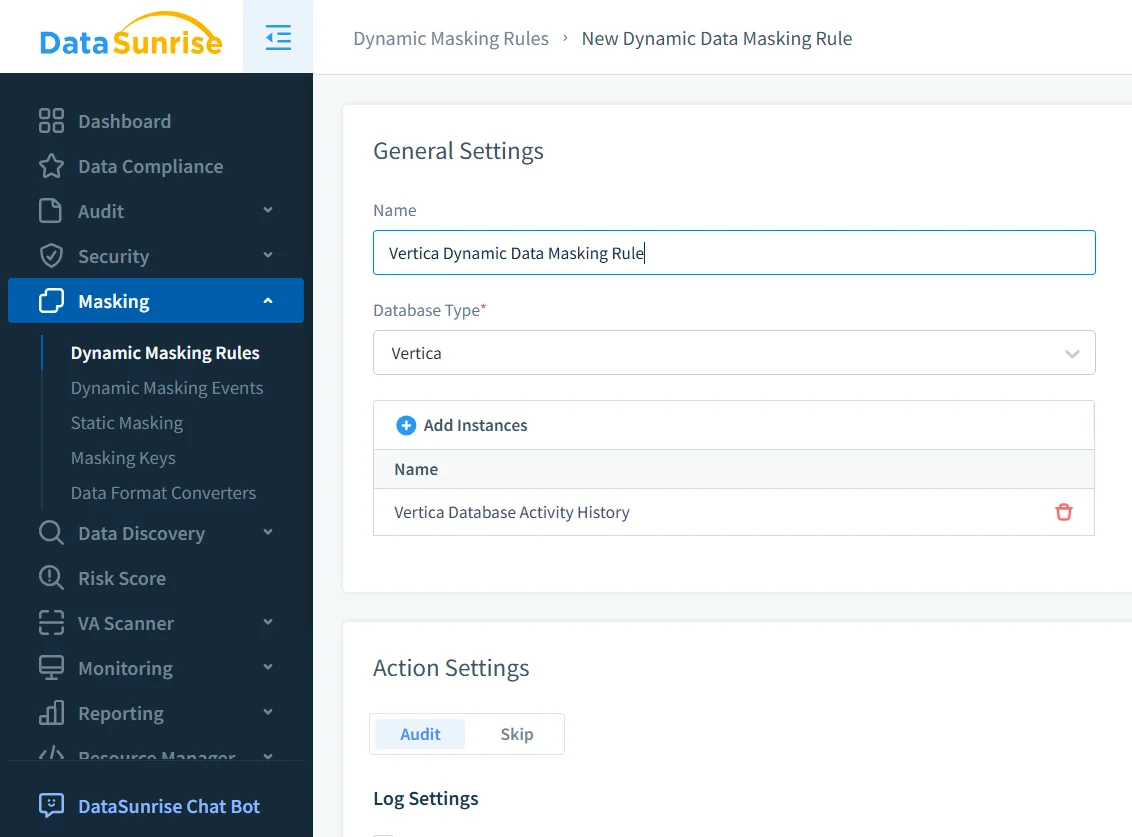
Configuración de reglas de anonimización para una instancia de base de datos Vertica.
En esta etapa, los administradores activan la auditoría para eventos de anonimización y definen cómo deben transformarse los valores sensibles. Los formatos pueden incluir anonimización total, enmascaramiento parcial o tokenización, dependiendo de los requisitos de la política.
Resultados Anonimizados en Consultas Analíticas
Desde la perspectiva del usuario, la anonimización es transparente. Las consultas usan SQL estándar y Vertica las ejecuta normalmente. Sin embargo, los valores sensibles aparecen anonimizados en los resultados devueltos.
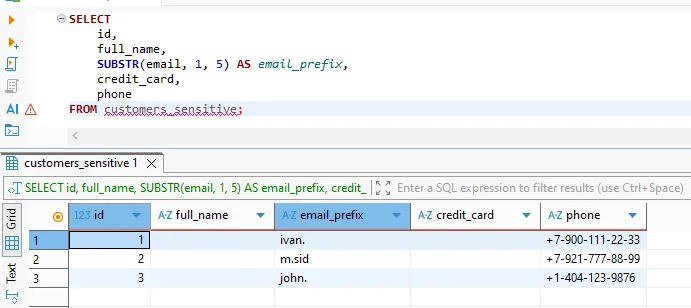
Conjunto de resultados anonimizados devueltos al cliente mientras se preserva la estructura analítica.
Este comportamiento permite a los analistas trabajar con conjuntos de datos realistas mientras se previene la exposición de identidades reales. Al mismo tiempo, los pipelines de aprendizaje automático pueden consumir datos de entrenamiento anonimizados sin filtrar información personal.
Auditoría y Visibilidad para el Acceso Anonimizado
La anonimización debe ser auditable para apoyar el cumplimiento normativo. Las organizaciones necesitan demostrar cuándo ocurrió la anonimización, qué reglas se aplicaron y quién accedió a los datos.
DataSunrise registra automáticamente eventos de auditoría para cada consulta anonimizada. Estos registros se integran con el Monitoreo de Actividad de Bases de Datos y pueden ser exportados a sistemas SIEM.
La auditoría centralizada simplifica el cumplimiento con regulaciones como el GDPR, HIPAA y SOX, además de apoyar investigaciones internas.
Comparación de Enfoques de Anonimización en Vertica
| Enfoque | Descripción | Idoneidad para Vertica |
|---|---|---|
| Anonimización estática | Crear conjuntos de datos permanentemente anonimizados | Mantenimiento elevado, flexibilidad limitada |
| Vistas SQL | Anonimizar datos usando vistas predefinidas | Fácilmente evadido por consultas directas |
| Lógica en capa de aplicación | Anonimización dentro de BI o aplicaciones | Cobertura inconsistente |
| Anonimización dinámica | Anonimizar resultados en tiempo de consulta | Centralizado y escalable |
Mejores Prácticas para la Anonimización de Datos en Vertica
- Comience con descubrimiento automatizado para identificar campos sensibles.
- Implemente la anonimización en la capa de consulta en lugar de copiar datos.
- Pruebe políticas usando cargas de trabajo reales de BI y análisis.
- Revise regularmente los registros de auditoría para detectar patrones de acceso inesperados.
- Alinee la anonimización con estrategias más amplias de seguridad de datos.
Conclusión
La anonimización de datos en Vertica proporciona una manera escalable y amigable para análisis para proteger información sensible. Al anonimizar valores dinámicamente en tiempo de consulta, las organizaciones reducen riesgos de exposición mientras preservan el poder y la flexibilidad de Vertica.
Con DataSunrise actuando como capa centralizada de aplicación, los equipos obtienen protección consistente, visibilidad total de auditoría y alineación regulatoria a través de paneles, scripts y pipelines de aprendizaje automático—sin sacrificar rendimiento.
