Anonimización de Datos en Percona Server para MySQL
La anonimización de datos en Percona Server para MySQL no es una característica de seguridad cosmética. Es un control estructural utilizado cuando los datos reales de producción deben compartirse fuera de su límite de confianza original sin exponer identidades, credenciales o atributos regulados. En la práctica, la anonimización reduce los riesgos de exposición a largo plazo y apoya directamente estrategias más amplias de seguridad de datos.
A diferencia de la auditoría o el seguimiento de actividades, la anonimización cambia los datos en sí mismos. El objetivo es eliminar permanentemente la capacidad de identificar individuos mientras se preserva suficiente estructura para pruebas, análisis y flujos de trabajo de desarrollo. Este enfoque es especialmente importante cuando se manejan información personal identificable (PII) y otras categorías de datos regulados.
Este artículo explica cómo funciona la anonimización en Percona Server para MySQL utilizando técnicas nativas de SQL, dónde fallan esos enfoques y cómo las plataformas centralizadas extienden la anonimización hacia un proceso gobernado, repetible y alineado con las normativas de cumplimiento de datos y requisitos de seguridad.
Qué significa la anonimización de datos en el contexto de MySQL
La anonimización de datos es la transformación irreversible de valores sensibles para que los sujetos de datos no puedan ser reidentificados, ni siquiera por los administradores. Una vez aplicada, la información anonimizada típicamente queda fuera del alcance de las normativas de cumplimiento de datos y reduce significativamente los riesgos de seguridad de datos a largo plazo.
En sistemas basados en MySQL, se utiliza la anonimización cuando los datos de producción se reutilizan para pruebas, análisis o almacenamiento fuera de entornos controlados. Se aplica comúnmente a identificadores personales, atributos financieros y datos relacionados con comportamiento o ubicación, especialmente en flujos de trabajo no productivos y escenarios de gestión de datos de prueba.
A diferencia del monitoreo de actividad de base de datos o controles de acceso basados en el principio de menor privilegio, la anonimización protege los datos en reposo reemplazando completamente los valores sensibles. Una vez anonimizado, el dato puede ser exportado, replicado o archivado sin controles adicionales en tiempo de ejecución.
Técnicas nativas de anonimización de datos en Percona Server para MySQL
Percona Server para MySQL no proporciona un motor nativo de anonimización, modelo de políticas ni controles de ciclo de vida para datos anonimizados. No existen mecanismos integrados para identificar columnas sensibles, hacer cumplir el alcance de la anonimización ni validar resultados. Por lo tanto, la anonimización se implementa combinando primitivas estándar de SQL como UPDATE, funciones, uniones y tablas auxiliares.
Estos enfoques pueden lograr transformaciones irreversibles, pero dependen completamente de la lógica manual y la disciplina operativa.
Reemplazo determinista con sentencias UPDATE
La técnica de anonimización más directa es sobrescribir columnas sensibles con valores generados o sintéticos. Este método se utiliza comúnmente al preparar copias de bases de datos de producción para pruebas o desarrollo.
UPDATE customers
SET
email = CONCAT('user_', id, '@example.com'),
phone = NULL,
full_name = CONCAT('Customer_', id),
address = 'REDACTED',
birth_date = NULL;
Este enfoque preserva claves primarias y conteo de filas, lo que ayuda a mantener una estabilidad referencial básica. Los sistemas posteriores que dependen de identificadores como id continúan funcionando, mientras que los datos personales reales son eliminados.
Sin embargo, este método no escala bien. Cada tabla requiere su propia lógica de anonimización y cada columna sensible debe ser manejada explícitamente. Si se añade una columna nueva posteriormente, permanecerá no anonimizadala a menos que se actualice el script. La consistencia referencial entre tablas relacionadas debe mantenerse manualmente y el orden de ejecución se vuelve crítico en esquemas con identificadores compartidos. No existe una validación integrada para confirmar que la anonimización esté completa y, una vez ejecutada, no se puede revertir sin restaurar desde copias de seguridad. Los datos originales se destruyen permanentemente.
Anonimización basada en hash
El hashing reemplaza valores sensibles con resúmenes de longitud fija, eliminando la legibilidad mientras preserva la unicidad. Esto se usa a veces cuando se requiere correlación o deduplicación sin exponer los valores originales.
UPDATE users
SET
national_id = SHA2(CONCAT(national_id, 'static_salt_123'), 256),
email = SHA2(CONCAT(email, 'static_salt_123'), 256);
La anonimización basada en hash es irreversible, pero introduce riesgos sutiles. Las sales previsibles o reutilizadas debilitan la protección y hacen que los hashes sean vulnerables a inferencias. Como entradas idénticas siempre producen hashes idénticos, las relaciones a través de tablas y conjuntos de datos siguen siendo visibles.
UPDATE payments
SET
payer_id = SHA2(CONCAT(payer_id, 'static_salt_123'), 256);
Mantener la consistencia entre tablas ahora depende de usar la misma lógica exacta de hash y salting en todas partes. Cualquier desviación rompe uniones y correlaciones. Además, los valores hasheados pueden seguir considerándose datos personales bajo ciertas regulaciones, dependiendo del contexto y el riesgo de reidentificación. A medida que los conjuntos de datos crecen, gestionar sales y hacer cumplir el hashing consistente en entornos se vuelve frágil y propenso a errores.
Tablas de sustitución de tokens
Una técnica más controlada usa tablas de consulta que asignan valores originales a tokens sintéticos. Esto permite que los datos anonimizados sigan siendo realistas mientras evita la identificación directa.
CREATE TABLE token_emails (
original_email VARCHAR(255),
token_email VARCHAR(255)
);
INSERT INTO token_emails VALUES
('[email protected]', '[email protected]'),
('[email protected]', '[email protected]');
La anonimización se aplica entonces mediante reemplazo basado en joins:
UPDATE orders o
JOIN token_emails t
ON o.email = t.original_email
SET
o.email = t.token_email;
Este enfoque mejora la calidad de los datos para pruebas y análisis, pero incrementa significativamente la carga operativa. La generación de tokens debe evitar colisiones, los tokens deben mantenerse consistentes en todas las tablas relacionadas y el reuso debe controlarse cuidadosamente para prevenir inferencias. Con el tiempo, las propias tablas de tokens se vuelven activos sensibles que requieren protección, rotación y control de acceso. Sin gobernanza centralizada, la gestión del ciclo de vida de tokens rápidamente se vuelve difícil de mantener y auditar.
Anonimización de datos centralizada con DataSunrise
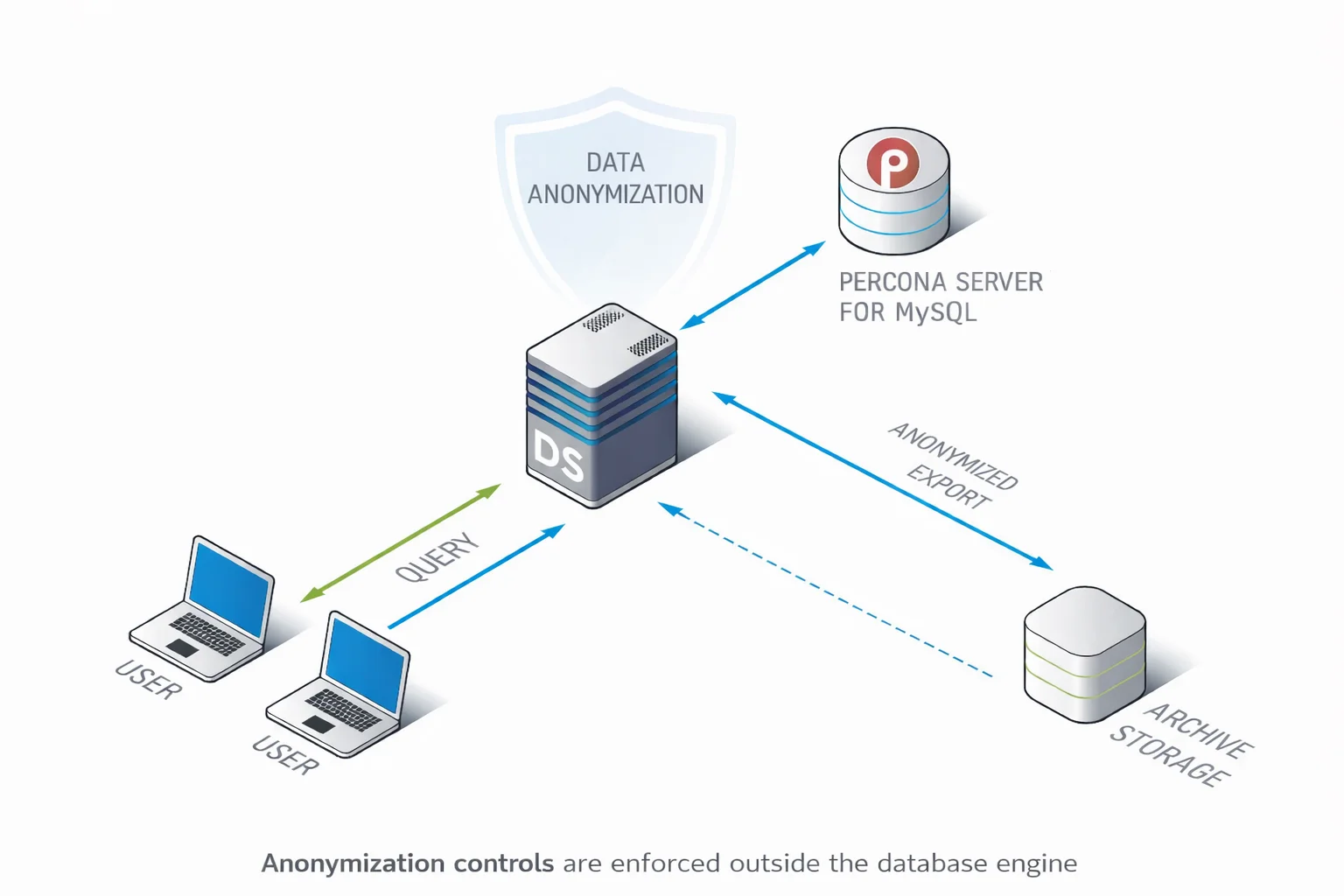
DataSunrise considera la anonimización de datos como un proceso de seguridad gobernado, no como una operación destructiva de SQL única. En lugar de incorporar lógica irreversible en esquemas de bases de datos o mantener scripts de anonimización frágiles, las reglas de anonimización se definen de forma centralizada y se aplican de manera consistente en los entornos de Percona Server para MySQL.
Este enfoque separa la lógica de anonimización de la estructura de la base de datos. Las bases de datos permanecen intactas mientras la anonimización se aplica como una capa de transformación controlada. Como resultado, las mismas políticas pueden reutilizarse en réplicas de producción, entornos de prueba, exportaciones y archivos sin reescribir SQL o correr el riesgo de resultados inconsistentes.
La anonimización centralizada también introduce visibilidad y control que los enfoques nativos no tienen. Los administradores pueden ver qué datos fueron anonimizados, cómo fueron transformados y dónde se aplicaron esas transformaciones.
Descubrimiento de datos sensibles
El proceso comienza con un descubrimiento automatizado de datos sensibles. En lugar de depender de revisiones manuales del esquema, DataSunrise escanea bases de datos para identificar datos personales, atributos financieros, credenciales y otros campos regulados. El descubrimiento opera a nivel de columna y considera tanto patrones de nombres como contenido de datos, reduciendo el riesgo de pasar por alto identificadores ocultos.
Este paso establece un alcance verificado para la anonimización, asegurando que la protección se aplique a todos los datos relevantes en lugar de a un subconjunto aproximado.
Definición de políticas
Una vez identificados los datos sensibles, las políticas de anonimización se definen de forma centralizada. Las políticas especifican cómo deben transformarse las diferentes categorías de datos, como el reemplazo con valores sintéticos, tokenización o anonimización irreversible.
Las políticas son reutilizables y versionadas. La misma lógica de anonimización puede aplicarse de forma consistente en múltiples bases de datos y entornos, eliminando la divergencia causada por scripts SQL copiados y pegados. Los cambios en las políticas se propagan automáticamente sin modificar esquemas de bases de datos ni código de aplicaciones.
Selección del modo de ejecución
La anonimización se aplica entonces según el contexto de ejecución en lugar de un SQL codificado rígidamente. Esto permite a las organizaciones controlar dónde y cuándo ocurre la anonimización sin duplicar lógica.
Los objetivos típicos de ejecución incluyen entornos de prueba y desarrollo, exportaciones de datos compartidas con terceros, réplicas de bases de datos usadas para análisis y conjuntos de datos archivados retenidos para almacenamiento a largo plazo. Cada contexto puede reutilizar las mismas políticas mientras permanece operacionalmente aislado.
Este modelo asegura que los sistemas productivos permanezcan intactos mientras los consumidores de datos posteriores reciben conjuntos de datos anónimos y seguros.
Verificación e informes
Después de la ejecución, DataSunrise ofrece capacidades de verificación e informes que los enfoques nativos no poseen. Los administradores pueden confirmar qué conjuntos de datos fueron anonimizados, qué políticas se aplicaron y si la cobertura fue completa.
Estos informes sirven como evidencia para revisiones internas de seguridad y auditorías externas de cumplimiento. En lugar de confiar en scripts, las organizaciones obtienen pruebas documentadas de que la anonimización se aplicó de manera consistente y correcta.
Al convertir la anonimización en un flujo de trabajo gestionado en vez de una tarea destructiva en SQL, la anonimización centralizada elimina suposiciones, reduce el riesgo operativo y escala entre ambientes sin aumentar la complejidad.
Impacto empresarial de una anonimización de datos adecuada
| Área de negocio | Impacto |
|---|---|
| Riesgo de seguridad | Reducción del impacto de brechas al eliminar datos sensibles utilizables de sistemas no productivos y conjuntos de datos compartidos |
| Eficiencia operativa | Aprovisionamiento más rápido de entornos de prueba, aseguramiento de calidad y análisis sin esperar limpieza manual de datos |
| Cumplimiento | Reducción del alcance de auditorías de cumplimiento al excluir conjuntos de datos anonimizados de supervisión regulatoria |
| Confiabilidad de ingeniería | Eliminación del error humano asociado a scripts manuales de anonimización SQL |
| Gobernanza de datos | Separación clara y aplicable entre datos de producción y no productivos |
Una anonimización adecuada desplaza la seguridad hacia la izquierda. Los datos sensibles se eliminan antes de que puedan difundirse en entornos donde los controles de acceso, la monitorización y la disciplina operativa son más débiles. En lugar de intentar proteger datos en todas partes, las organizaciones previenen la exposición en la fuente.
Conclusión
Percona Server para MySQL proporciona suficiente flexibilidad para implementar una anonimización básica de datos usando técnicas nativas de SQL. Para conjuntos de datos pequeños y operaciones puntuales, este enfoque puede ser suficiente, especialmente cuando la anonimización está estrictamente delimitada y controlada manualmente. Sin embargo, incluso en estos casos, la anonimización debe tratarse como parte de prácticas más amplias de seguridad de datos y no como una tarea aislada de mantenimiento.
A medida que los entornos crecen y se endurecen las normativas de cumplimiento de datos, la anonimización manual se vuelve rápidamente frágil, opaca y difícil de validar. Los scripts se desactualizan, columnas sensibles se pasan por alto y no existe una forma confiable de probar que la anonimización se aplicó consistentemente en conjuntos de datos de prueba, análisis y archivo. Esto es especialmente problemático en flujos de trabajo a gran escala de gestión de datos de prueba donde los datos se copian y reutilizan frecuentemente.
Las plataformas centralizadas como DataSunrise transforman la anonimización en un proceso controlado, auditable y repetible. Al combinar el descubrimiento automatizado de datos sensibles, transformaciones basadas en políticas e informes listos para cumplimiento, la anonimización se convierte en parte de la arquitectura de seguridad y no en una consideración destructiva posterior. Este modelo centralizado también se alinea naturalmente con otros mecanismos de protección, incluyendo enmascaramiento dinámico de datos, sin duplicar lógica ni incrementar la carga operativa.
Cuando se hace correctamente, la anonimización no es solo ocultar datos. Es eliminar el riesgo en la fuente, antes de que la información sensible se propague a entornos donde ya no pertenece.
