Cómo aplicar el enmascaramiento estático en Percona Server
El enmascaramiento estático en Percona Server para MySQL es un enfoque práctico para proteger información sensible antes de que los datos salgan de los entornos de producción. Percona Server se utiliza ampliamente para cargas de trabajo transaccionales, canales de análisis y aplicaciones orientadas al cliente, que a menudo almacenan datos regulados como identificadores personales, detalles de contacto y atributos financieros. En este contexto, el enmascaramiento estático actúa como un control fundamental dentro de estrategias más amplias de seguridad de datos.
Una vez que los conjuntos de datos de producción se copian en entornos de desarrollo, pruebas, análisis o soporte, los controles tradicionales de acceso pierden su efectividad. En ese punto, la transformación permanente de datos se convierte en la forma más confiable de prevenir exposiciones, mientras se preserva la integridad del esquema y la consistencia relacional. Este enfoque apoya directamente las prácticas modernas de seguridad de bases de datos, donde la protección debe mantenerse incluso fuera de los límites de producción. El propio Percona Server para MySQL es comúnmente elegido en estos escenarios debido a su rendimiento y funciones empresariales, como se describe en la documentación oficial de Percona Server.
Este artículo explica cómo puede aplicarse el enmascaramiento estático en Percona Server para MySQL utilizando técnicas nativas de SQL, y cómo plataformas centralizadas como DataSunrise extienden estas capacidades con flujos de trabajo de enmascaramiento repetibles y basados en políticas, alineados con los modernos requerimientos de cumplimiento de datos.
Cuándo se requiere el enmascaramiento estático en Percona Server para MySQL
Los entornos Percona suelen cumplir varios propósitos operativos al mismo tiempo. Una sola instancia de base de datos puede soportar depuración de aplicaciones, aseguramiento de calidad y pruebas de regresión, análisis de negocio, experimentación en ciencia de datos y tareas rutinarias de soporte. Aunque estas actividades dependen de esquemas realistas y relaciones de datos, no requieren acceso a valores reales personales ni financieros. En la práctica, el enmascaramiento estático se convierte en un control clave dentro de estrategias más amplias de seguridad de datos que buscan reducir exposiciones innecesarias.
Cuando los datos de producción se reutilizan fuera de su entorno original, conservar los valores originales introduce riesgos significativos. Incluso cuando se aplican permisos basados en roles, los conjuntos de datos copiados suelen ser accedidos por un rango más amplio de usuarios y almacenados en sistemas con menores controles. En esta etapa, los controles de acceso tradicionales ya no son suficientes, razón por la cual el enmascaramiento estático es comúnmente aplicado como parte de prácticas completas de seguridad de base de datos.
El enmascaramiento estático se vuelve obligatorio cuando los datos de producción se replican en entornos no productivos, se comparten con proveedores o contratistas externos, o se usan para pruebas y cargas de trabajo analíticas sin una necesidad comercial clara para los valores reales. Además, marcos regulatorios como GDPR, HIPAA y PCI DSS exigen explícitamente minimizar el uso de datos sensibles reales fuera de los sistemas de producción, alineando el enmascaramiento estático con los principios establecidos de cumplimiento de datos.
A diferencia del enmascaramiento dinámico, el enmascaramiento estático reemplaza permanentemente los valores sensibles en el conjunto de datos. Esta transformación irreversible asegura que, incluso si fallan los controles de acceso o si los datos son copiados nuevamente, la información original no pueda ser recuperada. Como resultado, el enmascaramiento estático complementa otros mecanismos de protección, incluyendo el enmascaramiento dinámico de datos, eliminando los riesgos de exposición directamente a nivel de los datos.
Técnicas nativas de enmascaramiento estático en Percona Server para MySQL
Percona Server para MySQL no incluye un motor de enmascaramiento estático incorporado. Por ello, el enmascaramiento estático se suele implementar mediante transformaciones SQL explícitas ejecutadas contra los conjuntos de datos copiados en entornos no productivos. Estas operaciones modifican permanentemente los datos y típicamente se realizan justo después de la replicación o exportación.
Enmascaramiento estático a nivel de columna con sentencias UPDATE
La técnica más común de enmascaramiento estático consiste en sobrescribir columnas sensibles con valores determinísticos o parcialmente ofuscados. Este enfoque preserva la estructura del esquema y los tipos de datos, mientras elimina el contenido real.
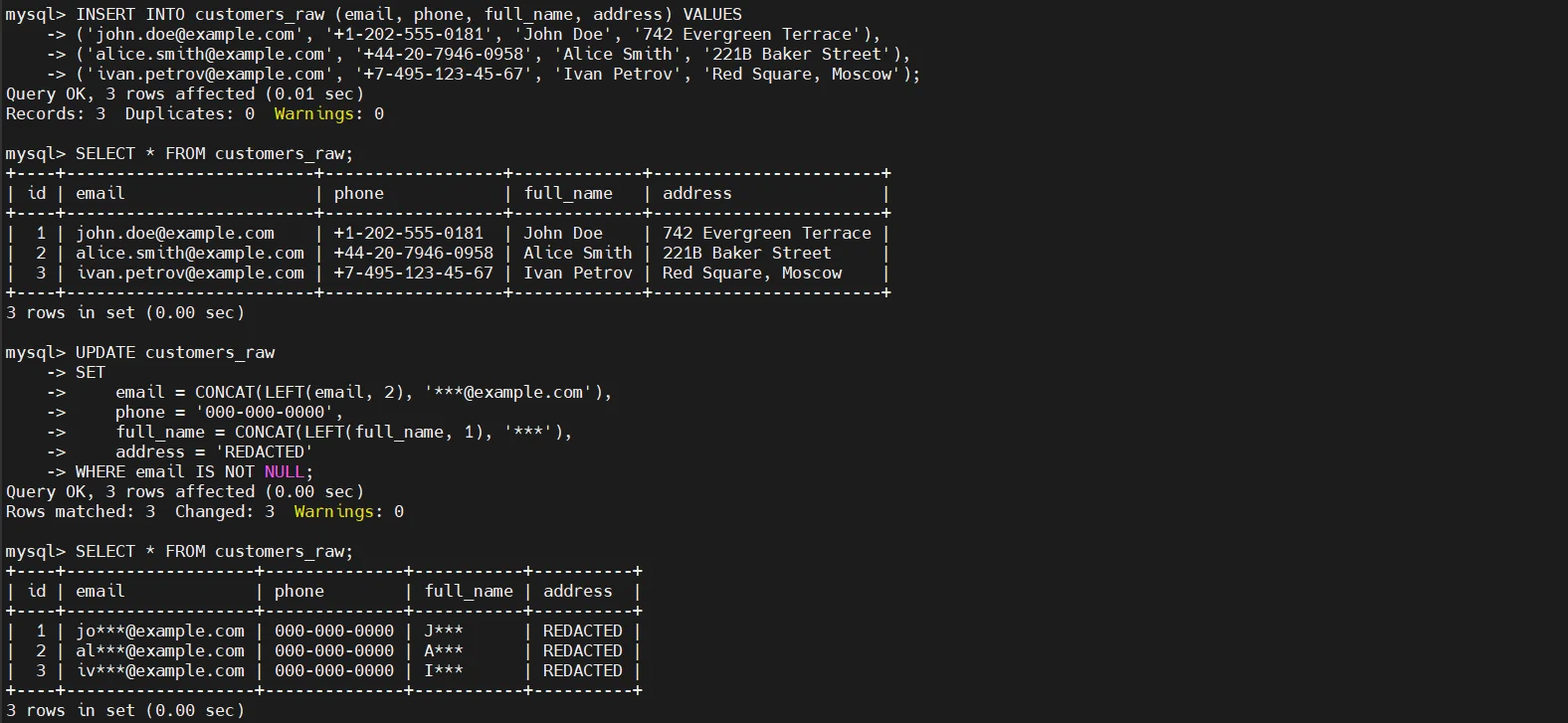
Este método es simple y efectivo, pero altera permanentemente el conjunto de datos. Una vez ejecutado, los valores originales no pueden restaurarse, lo que hace que este enfoque sea adecuado solo para copias no productivas.
Enmascaramiento basado en hash para identificadores
Cuando se debe preservar la unicidad y la integridad referencial, el hashing proporciona una técnica confiable de enmascaramiento estático. Los valores hasheados permanecen consistentes entre tablas, permitiendo que las uniones y comparaciones sigan funcionando.
UPDATE users
SET
national_id = SHA2(national_id, 256),
passport_number = SHA2(passport_number, 256)
WHERE national_id IS NOT NULL;
Debido a que el hashing es unidireccional, los identificadores originales no pueden reconstruirse, mientras que la lógica relacional permanece intacta entre tablas dependientes.
Enmascaramiento aleatorio para campos numéricos y de fecha
Para montos financieros, métricas o marcas de tiempo, la aleatorización dentro de rangos controlados ayuda a mantener distribuciones de datos realistas sin exponer valores reales.
UPDATE payments
SET
amount = FLOOR(RAND() * 1000) + 10,
tax_amount = FLOOR(RAND() * 200),
payment_date = DATE_SUB(
CURDATE(),
INTERVAL FLOOR(RAND() * 365) DAY
),
settlement_date = DATE_ADD(
payment_date,
INTERVAL FLOOR(RAND() * 5) DAY
);
Este enfoque se usa comúnmente en entornos de pruebas y análisis, donde las tendencias y distribuciones son importantes, pero no los datos transaccionales reales.
Consideraciones prácticas
Aunque el enmascaramiento estático basado en SQL nativo ofrece flexibilidad, requiere coordinación cuidadosa. Las dependencias entre tablas deben manejarse manualmente, la lógica de enmascaramiento debe mantenerse coherente entre ambientes, y errores de ejecución pueden ocasionar conjuntos de datos incompletos o dañados. A medida que crece el alcance del enmascaramiento, estos scripts se vuelven más difíciles de mantener y gobernar.
Enmascaramiento estático centralizado para Percona Server para MySQL con DataSunrise
DataSunrise introduce una capa de seguridad externa y basada en políticas que automatiza el enmascaramiento estático sin incrustar lógica de transformación en scripts SQL u objetos de base de datos. En lugar de mantener sentencias UPDATE personalizadas o procedimientos almacenados, las reglas de enmascaramiento se definen de manera central y se ejecutan consistentemente a través de los entornos. Esto asegura que la misma lógica de transformación se aplique cada vez que los datos de producción se preparan para su uso en entornos no productivos.
Al externalizar la lógica de enmascaramiento, este enfoque alinea el enmascaramiento estático con estrategias más amplias de seguridad de datos y seguridad de bases de datos, donde la protección se aplica independientemente del código de aplicación y del diseño del esquema de base de datos.
Descubrimiento y clasificación de datos sensibles
Antes de que cualquier operación de enmascaramiento comience, DataSunrise escanea automáticamente los esquemas de Percona Server para MySQL para identificar datos sensibles. El proceso de descubrimiento detecta información personal identificable, atributos financieros, credenciales y otros elementos regulados basándose en patrones reales de contenido y no solo en nombres de columnas o metadatos. Esta capacidad se basa en modernas técnicas de descubrimiento de datos que se enfocan en el contenido de los datos reales en lugar de suposiciones del esquema.
Dado que el descubrimiento se fundamenta en el análisis de contenido, permanece efectivo incluso en esquemas mal documentados o con nombres inconsistentes. Como resultado, los campos sensibles se identifican de forma confiable antes de aplicar las reglas de enmascaramiento, reduciendo el riesgo de exposición accidental de datos y fortaleciendo los controles generales de seguridad de datos.
- Identificación automática de PII, datos financieros y credenciales basada en el contenido de datos, alineada con prácticas de protección de PII
- Independencia de convenciones de nombres de columnas o calidad de documentación del esquema
- Descubrimiento continuo conforme los esquemas evolucionan con el tiempo
- Riesgo reducido de pasar por alto campos sensibles antes del enmascaramiento
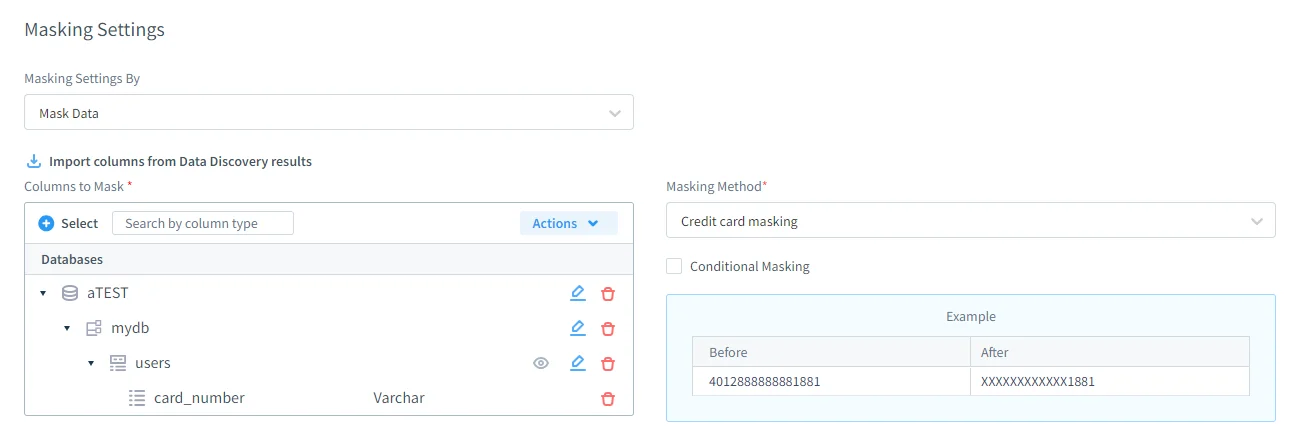
Definición de reglas de enmascaramiento estático
Las reglas de enmascaramiento estático en DataSunrise proporcionan un control detallado sobre cómo se transforman los datos. Los administradores pueden definir con precisión qué bases de datos, esquemas, tablas y columnas están sujetas al enmascaramiento, así como el método de enmascaramiento aplicado a cada campo. Las técnicas soportadas incluyen sustitución, hashing, aleatorización y nulificación, siguiendo los principios establecidos de enmascaramiento estático de datos.
Es importante que las reglas de enmascaramiento puedan preservar la integridad referencial entre tablas relacionadas, asegurando que las relaciones de claves foráneas permanezcan válidas después de la transformación. Las reglas son reutilizables y controladas por versiones, lo que elimina la necesidad de scripts SQL puntuales y ayuda a mantener la coherencia entre múltiples entornos, a la vez que soporta políticas centralizadas de seguridad de bases de datos.
- Definición centralizada de reglas a través de bases de datos y esquemas
- Soporte para múltiples técnicas de enmascaramiento por tipo de dato
- Preservación de la integridad referencial entre tablas relacionadas
- Reglas controladas por versión y reutilizables entre entornos
Ejecución de trabajos de enmascaramiento estático
Una vez configuradas las reglas de enmascaramiento, la ejecución se convierte en un proceso operativo controlado en lugar de una tarea manual. Los trabajos de enmascaramiento estático pueden ejecutarse bajo demanda, programarse para ejecución automática o integrarse en canalizaciones de CI/CD y provisión de datos. Este modelo operativo se alinea con las prácticas más amplias de gestión de datos de prueba utilizadas en workflows modernos de DevOps.
Como resultado, los entornos no productivos reciben conjuntos de datos permanentemente enmascarados sin depender de la ejecución manual de SQL o scripting ad-hoc, reduciendo el riesgo operativo y errores humanos, al tiempo que mejora la eficiencia de la gestión de datos.
- Ejecución bajo demanda para preparación puntual de conjuntos de datos
- Enmascaramiento programado para ciclos de actualización periódicos
- Integración con workflows de CI/CD y provisión de datos
- Eliminación de pasos manuales basados en SQL para el enmascaramiento
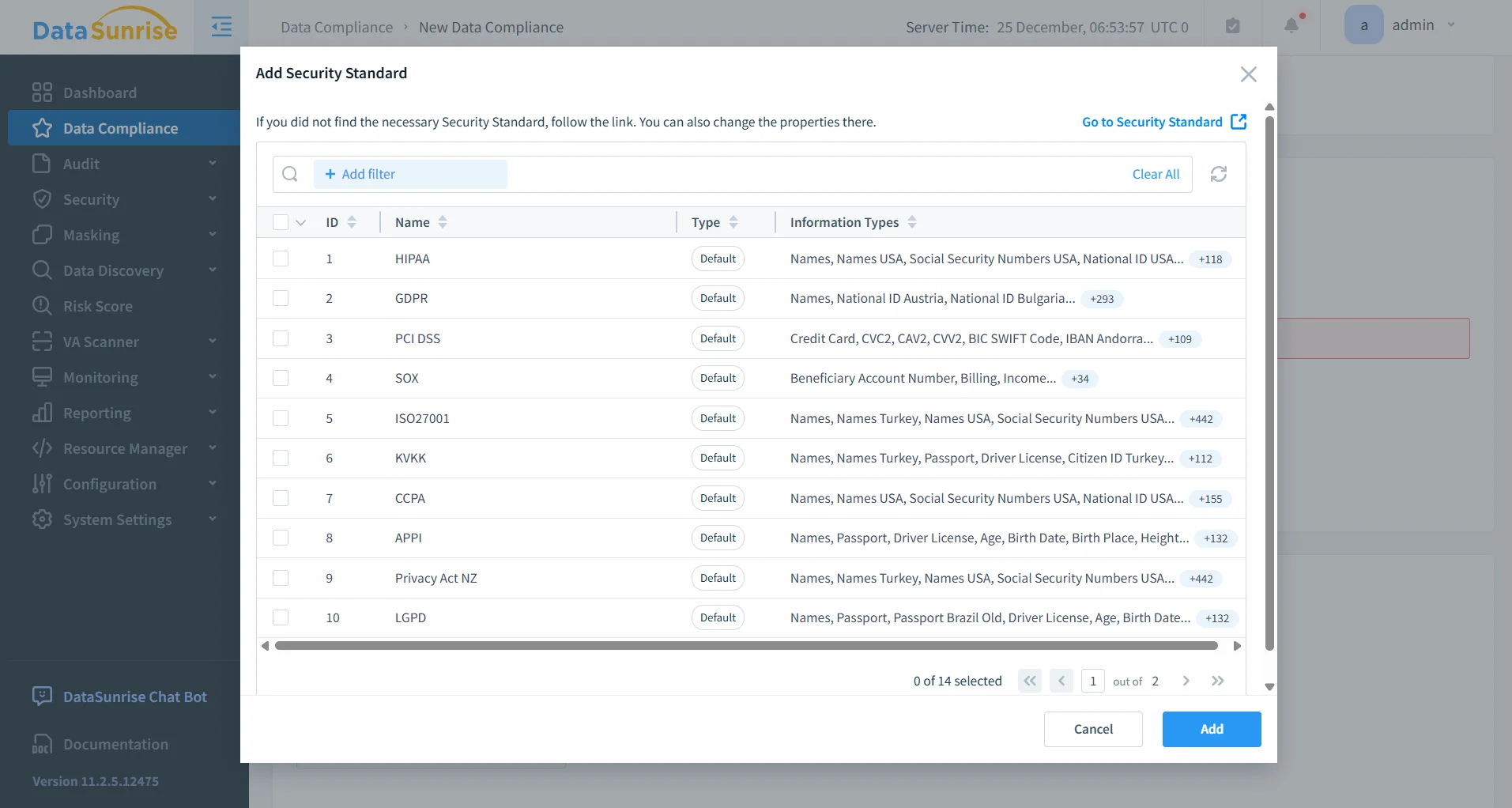
Auditabilidad y alineación con cumplimiento
Cada operación de enmascaramiento estático realizada por DataSunrise queda registrada y es rastreable. Estos registros crean un historial claro de cuándo se ejecutó el enmascaramiento, qué reglas se aplicaron y qué activos de datos fueron afectados. Este nivel de visibilidad apoya directamente los programas estructurados de cumplimiento de datos.
Al convertir el enmascaramiento estático en un proceso documentado y repetible, las organizaciones dejan de manejar datos de forma ad-hoc y avanzan hacia un flujo de trabajo de cumplimiento gobernado que resiste auditorías internas y externas, complementando iniciativas centralizadas de gestión del cumplimiento.
- Trazabilidad completa de operaciones de enmascaramiento y uso de reglas
- Alineación con requisitos de GDPR, HIPAA, PCI DSS y SOX
- Registros listos para evidencias en auditorías y revisiones de cumplimiento
- Transición de enmascaramientos ad-hoc a procesos gobernados de cumplimiento
Impacto comercial del enmascaramiento estático en Percona Server para MySQL
| Área de negocio | Impacto operativo |
|---|---|
| Riesgo de exposición de datos | Menor probabilidad de filtración de datos sensibles fuera de entornos de producción |
| Provisionamiento de datos de prueba | Creación más rápida de conjuntos de datos cumplidores para desarrollo, QA y análisis |
| Preparación para auditorías | Menor esfuerzo requerido para preparar evidencias para auditorías de seguridad y cumplimiento |
| Consistencia operativa | Aplicación uniforme de reglas de enmascaramiento entre equipos y entornos |
| Confianza en el intercambio de datos | Colaboración más segura con equipos internos y socios externos |
El enmascaramiento estático desplaza el foco de restringir el acceso a permitir la reutilización segura y controlada de datos, haciendo los flujos de trabajo no productivos tanto más seguros como más eficientes.
Conclusión
Percona Server para MySQL brinda la flexibilidad de implementar enmascaramiento estático utilizando técnicas nativas de SQL. Estos enfoques son adecuados para escenarios pequeños y controlados donde la aplicación manual es aceptable y los requerimientos básicos de enmascaramiento estático de datos pueden satisfacerse con scripts personalizados.
Sin embargo, las organizaciones que requieren gobernanza escalable, consistencia entre entornos y flujos de trabajo de enmascaramiento preparados para auditorías se benefician de plataformas centralizadas como DataSunrise. Al formalizar el enmascaramiento estático en políticas estructuradas en lugar de scripts frágiles, la protección de datos sensibles se vuelve predecible, repetible y conforme por diseño, fortaleciendo la postura general de seguridad de datos.
El enmascaramiento estático deja de ser una solución temporal y se convierte en un control operativo.
