Cómo Aplicar Enmascaramiento Estático en Vertica
El enmascaramiento estático en Vertica es la técnica central descrita en esta guía sobre cómo aplicar enmascaramiento estático en Vertica para proteger datos analíticos sensibles fuera de los entornos de producción. Vertica comúnmente soporta análisis a gran escala, generación de informes y cargas de trabajo de ciencia de datos. Como resultado, los conjuntos de datos de producción a menudo incluyen información personal, financiera o información regulada de otra manera.
Sin embargo, una vez que los equipos copian datos de producción en entornos de desarrollo, pruebas o análisis compartidos, los controles de acceso tradicionales pierden gran parte de su efectividad. En ese momento, la transformación irreversible de los datos se convierte en el único método confiable para prevenir exposiciones al tiempo que se preserva la integridad del esquema y el valor analítico.
Este artículo explica cómo aplicar enmascaramiento estático en Vertica utilizando DataSunrise. Se guía a través de la configuración, ejecución y validación usando capturas de pantalla reales de la interfaz, resaltando también consideraciones operativas y de cumplimiento.
Cuándo es Necesario el Enmascaramiento Estático en Vertica
En la práctica, los entornos Vertica sirven a muchos consumidores al mismo tiempo. Analistas, desarrolladores, ingenieros de aseguramiento de calidad (QA) y contratistas externos requieren acceso a conjuntos de datos realistas que reflejen las estructuras de producción.
No obstante, compartir datos de producción sin procesar introduce serios riesgos de seguridad y cumplimiento. Por esa razón, el enmascaramiento estático en Vertica se vuelve obligatorio cuando los datos son:
- Copiados en entornos de desarrollo o QA
- Compartidos con equipos externos o proveedores de servicios
- Utilizados para análisis fuera de zonas de producción reguladas
- Sujetos a regulaciones de privacidad como GDPR o HIPAA
A diferencia de los controles en tiempo de ejecución, el enmascaramiento estático elimina por completo los valores originales. Como resultado, la información sensible ya no existe en ninguna parte del conjunto de datos.
Limitaciones de las Técnicas Nativas de Enmascaramiento en Vertica
Vertica no incluye funcionalidad incorporada de enmascaramiento estático. Debido a esta limitación, los equipos suelen recurrir a actualizaciones manuales en SQL, pipelines de exportación o scripts personalizados.
Inicialmente, estos enfoques pueden parecer suficientes. Sin embargo, con el tiempo introducen varios problemas estructurales:
- Selección manual de columnas que se rompe conforme evolucionan los esquemas
- Lógica de enmascaramiento inconsistente entre entornos
- Ausencia de un registro de auditoría que demuestre que el enmascaramiento realmente ocurrió
- Alto costo operativo durante ciclos recurrentes de actualización
A medida que los conjuntos de datos crecen y la frecuencia de actualización aumenta, estas soluciones se vuelven frágiles. Eventualmente, la gobernanza se degrada y la preparación para auditorías decae.
Configurando el Enmascaramiento Estático en Vertica con DataSunrise
DataSunrise aborda estas limitaciones introduciendo una interfaz centralizada para definir y gestionar tareas de enmascaramiento estático para Vertica. En lugar de incrustar la lógica de enmascaramiento en scripts SQL, DataSunrise aplica el enmascaramiento estático en Vertica externamente, sin cambiar los esquemas de base de datos o el código de las aplicaciones.
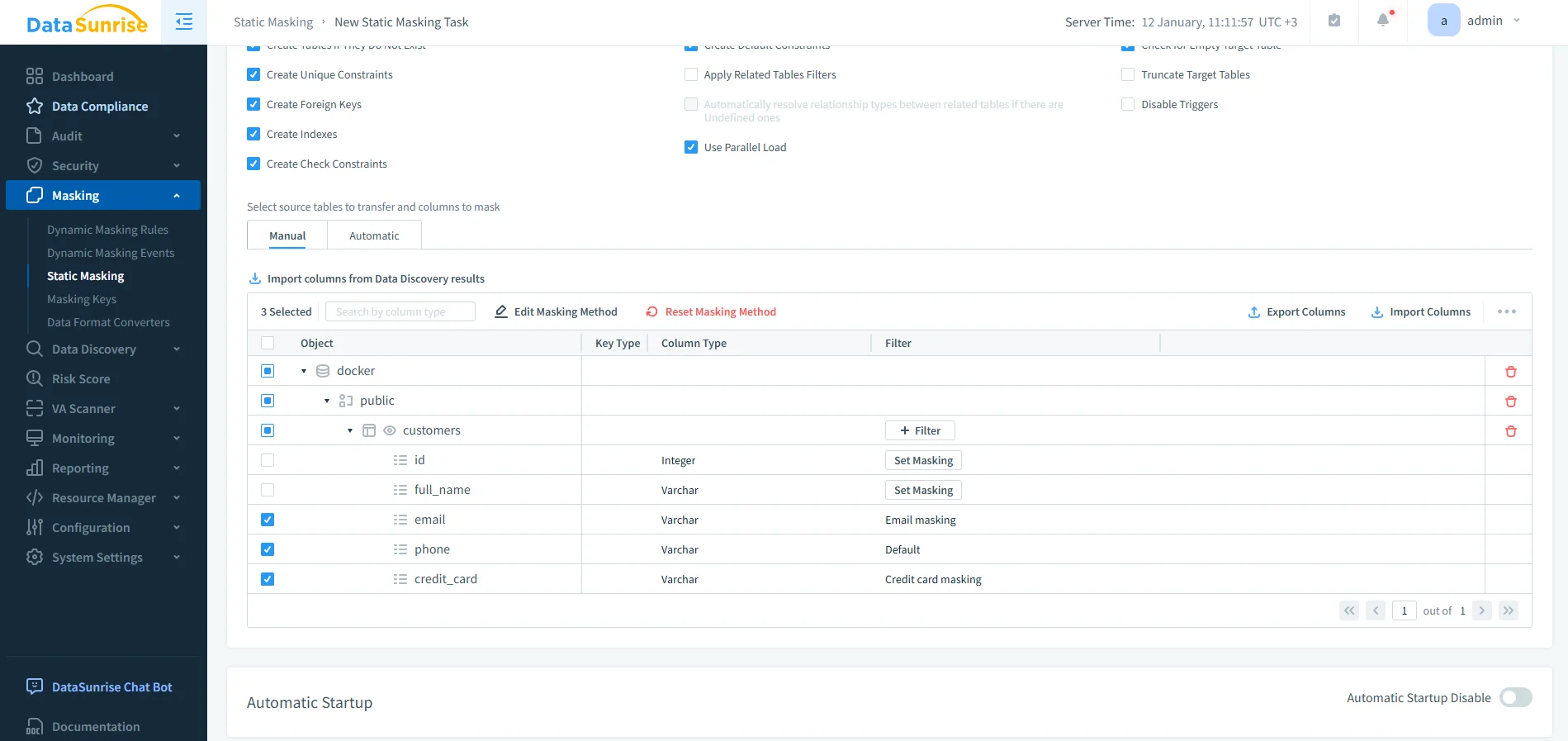
En esta etapa, los administradores definen las instancias de origen y destino de Vertica, seleccionan la base de datos y el esquema, y eligen qué tablas y columnas requieren enmascaramiento. DataSunrise muestra campos sensibles como direcciones de correo electrónico, números telefónicos y datos de tarjetas de crédito junto con métodos de enmascaramiento predefinidos.
Selección de Columnas y Métodos de Enmascaramiento en Vertica
En lugar de depender de la identificación manual, DataSunrise se integra con el descubrimiento de datos para detectar automáticamente datos sensibles.
Después de completar el descubrimiento, los equipos pueden aplicar métodos de enmascaramiento de manera consistente en todos los esquemas. Las transformaciones irreversibles comunes incluyen:
- Sustitución sintética de correos electrónicos
- Tokenización de números telefónicos
- Enmascaramiento de tarjetas de crédito con formato preservado
- Hash irreversible para identificadores
Es importante destacar que estas transformaciones preservan la estructura analítica mientras eliminan completamente los valores reales.
Definiendo las Instancias de Vertica de Origen y Destino para Enmascaramiento Estático
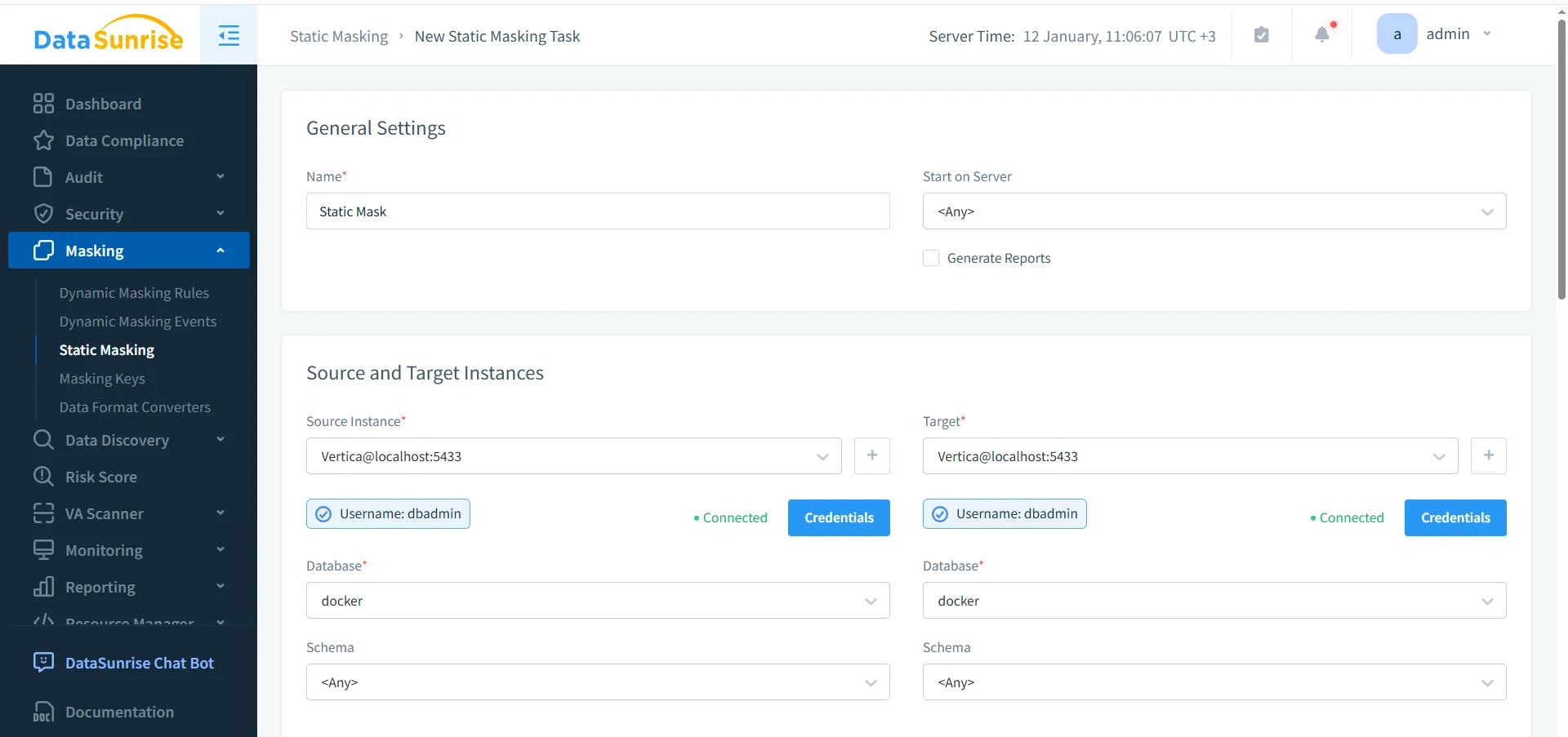
Las tareas de enmascaramiento estático requieren siempre una instancia de origen y una de destino. En la mayoría de las implementaciones, ambas apuntan a la misma base de datos Vertica. Sin embargo, el enmascaramiento se aplica a una copia actualizada o snapshot en lugar de a los datos en producción en vivo.
Mientras tanto, DataSunrise almacena las credenciales de forma segura y las reutiliza en los flujos de trabajo. Como resultado, las ejecuciones repetidas se mantienen predecibles y operativamente eficientes.
Ejecutando la Tarea de Enmascaramiento Estático en Vertica

Después de la configuración, los administradores ejecutan la tarea de enmascaramiento estático como una operación controlada. Cuando el rendimiento es importante, pueden habilitar la ejecución paralela para acelerar el procesamiento en grandes conjuntos de datos Vertica.
Cada ejecución produce un indicador claro de estado, duración y marca de tiempo. Por consiguiente, los equipos pueden confirmar inmediatamente que el enmascaramiento estático en Vertica se completó con éxito.
Validando los Resultados del Enmascaramiento Estático en Vertica
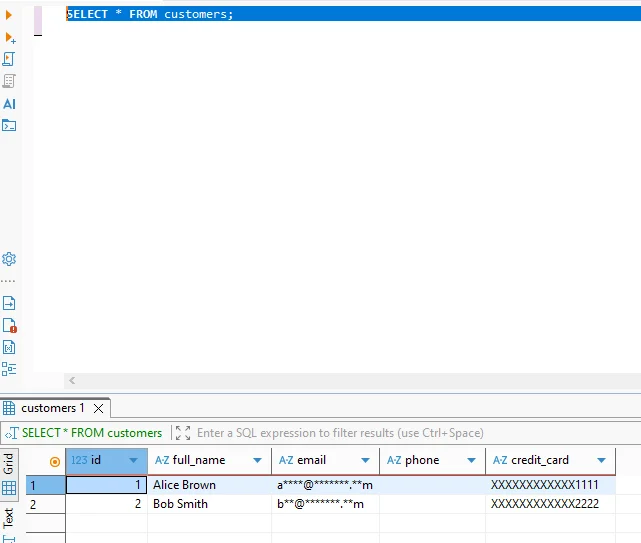
Una vez completada la tarea, el sistema transforma permanentemente los valores sensibles. Por lo tanto, las consultas devuelven datos enmascarados incluso para los usuarios privilegiados.
La siguiente consulta ilustra cómo aparecen los datos enmascarados en Vertica:
SELECT * FROM customers;
Dado que la transformación es irreversible, los equipos pueden reutilizar de manera segura el conjunto de datos para análisis, QA y compartición externa.
Impacto Operativo y de Cumplimiento del Enmascaramiento Estático en Vertica
| Área | Sin Enmascaramiento Estático | Con Enmascaramiento Estático |
|---|---|---|
| Riesgo de exposición de datos | Alto cuando se copian datos | Eliminado mediante transformación irreversible |
| Preparación para auditorías | Recolección manual de evidencias | Registros automáticos de tareas y ejecuciones |
| Esfuerzo operativo | Basado en scripts y frágil | Centralizado y repetible |
| Alineación con cumplimiento | Difícil de demostrar | Trazabilidad integrada |
Enmascaramiento Estático vs Enmascaramiento Dinámico en Vertica
El enmascaramiento estático y el dinámico abordan diferentes escenarios de exposición.
El enmascaramiento estático de datos altera permanentemente los valores almacenados. En cambio, el enmascaramiento dinámico de datos aplica transformaciones en tiempo de consulta.
Por lo tanto, el enmascaramiento estático en Vertica es más adecuado cuando los datos salen de los entornos de producción o deben cumplir con requisitos de anonimización irreversible.
Conclusión: Convertir el Enmascaramiento Estático en un Control Estándar
Aplicar el enmascaramiento estático en Vertica no es una medida de seguridad cosmética. En cambio, sirve como un control fundamental para proteger datos analíticos una vez que estos salen de los límites de producción.
Al utilizar DataSunrise, las organizaciones centralizan la lógica de enmascaramiento, reducen riesgos operativos y alinean las prácticas de manejo de datos con las regulaciones modernas de cumplimiento de datos.
Si su entorno Vertica soporta análisis más allá de un único equipo de confianza, el enmascaramiento estático ya debería formar parte de su flujo de trabajo. Cualquier otra cosa genera exposición no gestionada.
