Cómo Enmascarar Datos Sensibles en Vertica
Cómo enmascarar datos sensibles en Vertica es una pregunta crítica para las organizaciones que dependen de Vertica como una plataforma de análisis de alto rendimiento mientras manejan información regulada o confidencial. Vertica se utiliza ampliamente para reportes de BI, análisis de clientes, pipelines de aprendizaje automático y procesamiento de datos a gran escala. Como resultado, estos casos de uso a menudo requieren un acceso amplio a los datos, lo que aumenta el riesgo de que la información personal identificable (PII), datos de pago o detalles de contacto puedan exponerse a través de consultas, exportaciones o sistemas posteriores.
En entornos orientados al análisis, las técnicas tradicionales de protección de datos se vuelven rápidamente insuficientes. Por ejemplo, los permisos estáticos, las tablas copiadas o las vistas creadas manualmente luchan por mantenerse al día con los esquemas cambiantes, las proyecciones en evolución y el creciente número de usuarios. Por lo tanto, las organizaciones necesitan un enfoque de enmascaramiento que funcione de manera dinámica y consistente a través de todas las cargas de trabajo de Vertica, sin ralentizar las consultas ni obligar a cambios en las aplicaciones.
Cómo enmascarar datos sensibles en Vertica de manera efectiva requiere aplicar la protección en tiempo de consulta. En lugar de modificar los datos almacenados, el enmascaramiento dinámico de datos intercepta los resultados de las consultas y reemplaza los campos sensibles con valores anonimados o parcialmente ocultos según la política. En consecuencia, este enfoque preserva la utilidad analítica mientras previene la divulgación no autorizada.
Por Qué Es Difícil Enmascarar Datos Sensibles en Vertica
La arquitectura de Vertica prioriza la velocidad y escalabilidad. Almacena datos en contenedores columnar ROS, mantiene cambios recientes en WOS y utiliza proyecciones para crear múltiples representaciones físicas de la misma tabla lógica. Al mismo tiempo, este diseño complica los esfuerzos de protección de datos.
Diversos factores hacen que el enmascaramiento sea especialmente importante en entornos Vertica:
- Las tablas analíticas amplias a menudo combinan métricas empresariales con atributos sensibles.
- Múltiples proyecciones pueden replicar columnas sensibles en todo el clúster.
- Clústeres compartidos atienden simultáneamente herramientas BI, pipelines ETL, notebooks y trabajos ML.
- Consultas SQL ad-hoc frecuentemente evaden las capas de reporte curadas.
- El control de acceso nativo basado en roles no proporciona redacción a nivel de columna.
Los controles de acceso de Vertica deciden quién puede consultar una tabla; sin embargo, no controlan qué valores aparecen en los resultados. Una vez que se ejecuta una consulta, Vertica retorna todas las columnas seleccionadas en forma clara. Para cerrar esta brecha, las organizaciones introducen una capa externa de enmascaramiento que comprende la sensibilidad de columnas y el contexto de usuario.
Para información adicional sobre cómo Vertica procesa cargas analíticas, consulte la documentación oficial de arquitectura de Vertica.
Cómo Funciona el Enmascaramiento Dinámico de Datos con Vertica
Las organizaciones comúnmente implementan el enmascaramiento dinámico en Vertica usando un modelo basado en proxy. En esta configuración, las aplicaciones cliente se conectan a una puerta de enlace de enmascaramiento en lugar de conectar directamente a la base de datos. Como resultado, cada solicitud SQL pasa por esta puerta de enlace, donde se evalúan las políticas de enmascaramiento antes de la ejecución.
El flujo de trabajo del enmascaramiento sigue una secuencia consistente:
- El motor de enmascaramiento analiza y procesa la sentencia SQL.
- El motor verifica las columnas referenciadas con un catálogo de sensibilidad.
- Se evalúan las reglas de enmascaramiento basadas en el usuario, aplicación o entorno.
- La puerta de enlace reescribe los resultados de la consulta para que los valores sensibles aparezcan enmascarados.
El sistema deja las tablas y proyecciones subyacentes de Vertica sin cambios. Debido a que el enmascaramiento ocurre solo en el conjunto de resultados devuelto, este enfoque evita la duplicación de datos y preserva el rendimiento de las consultas.
Muchas organizaciones implementan este modelo usando DataSunrise Data Compliance, que provee una capa centralizada de enmascaramiento y gobernanza frente a Vertica.
Arquitectura: Cómo Enmascarar Datos Sensibles en Vertica Antes de Que Salgan de la Base de Datos
El diagrama a continuación ilustra cómo las organizaciones enmascaran datos sensibles antes de que lleguen a herramientas BI, clientes SQL o aplicaciones analíticas. En la práctica, todas las solicitudes pasan por una puerta de enlace de enmascaramiento dedicada que aplica políticas de manera consistente.
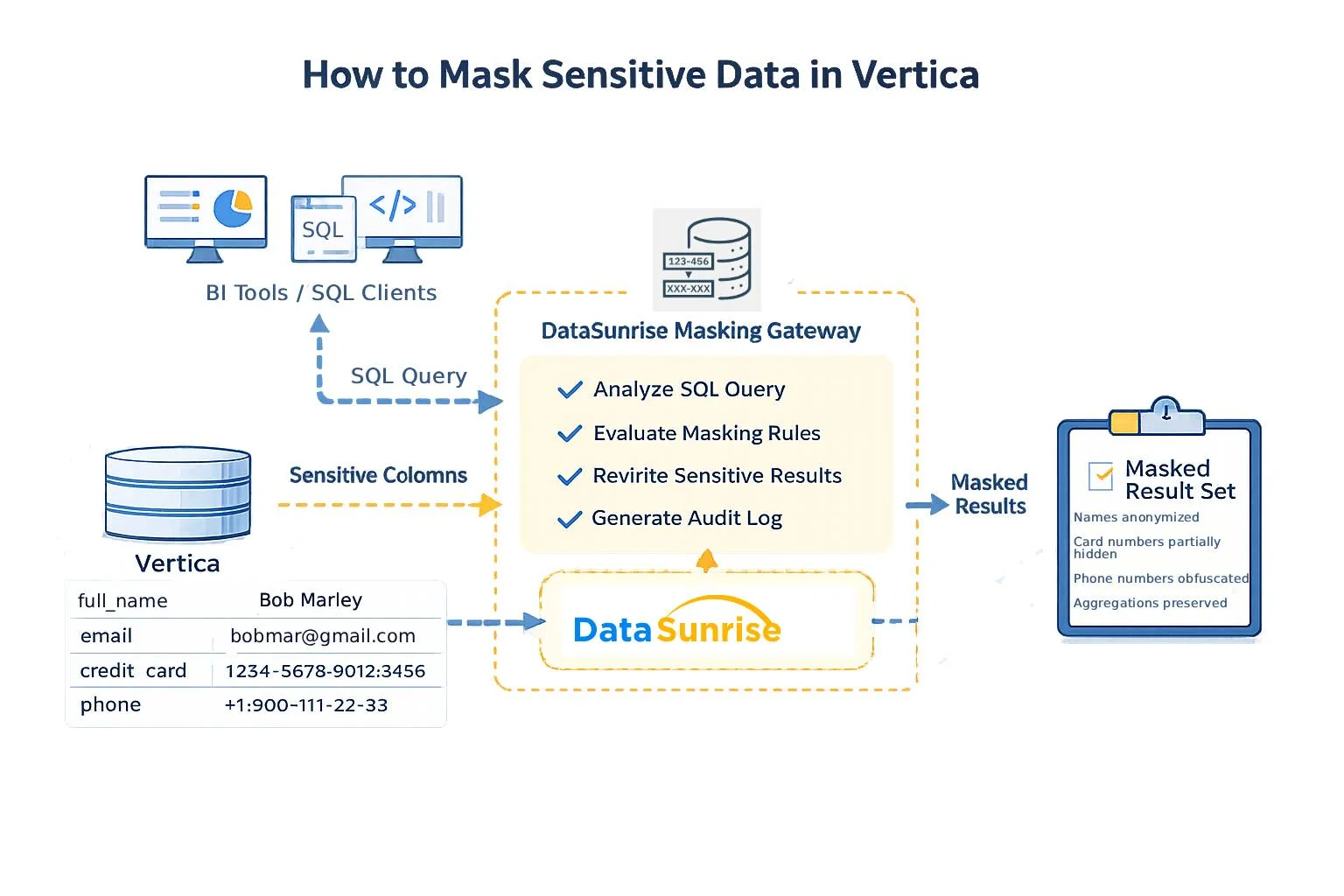
Esta arquitectura asegura que:
- Las aplicaciones continúan usando SQL estándar sin modificaciones.
- Los valores sensibles nunca salen de Vertica en forma clara.
- Las reglas de enmascaramiento se aplican uniformemente en todas las herramientas y usuarios.
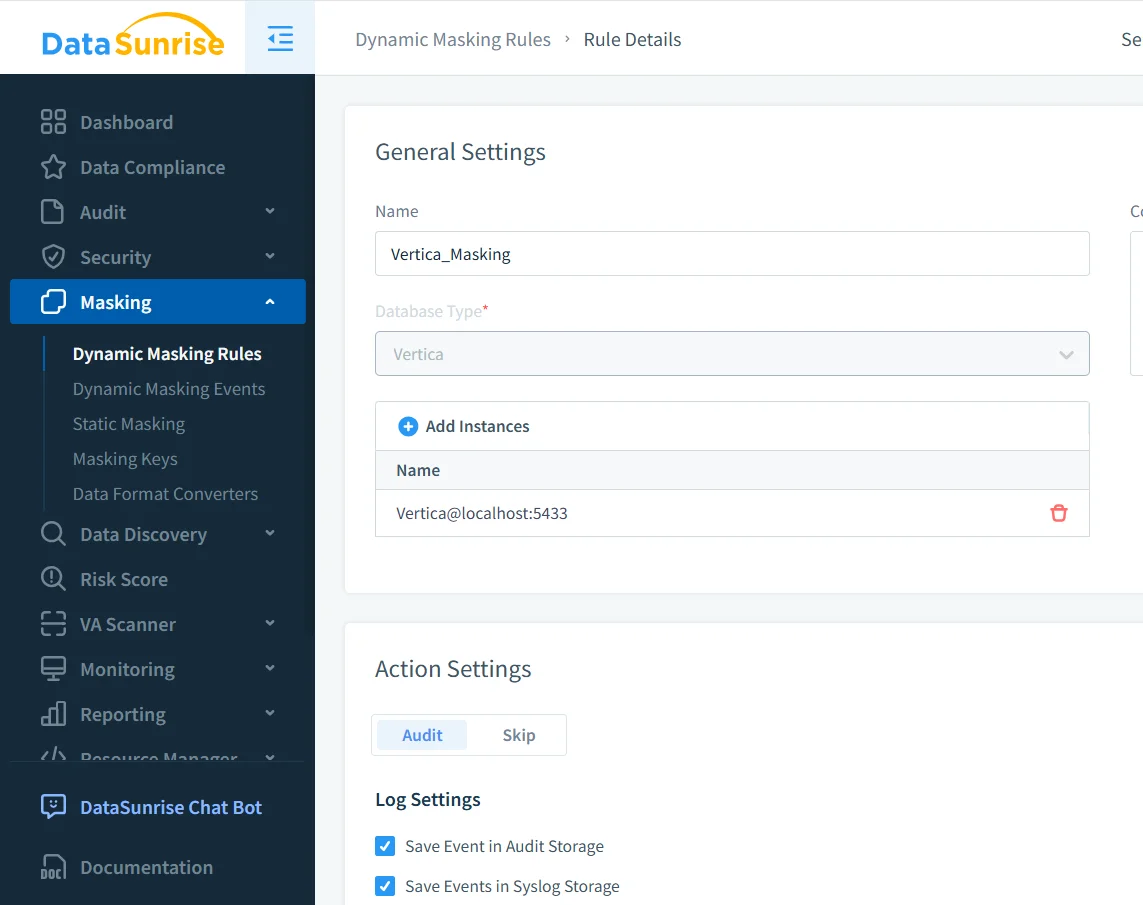
Configurando una Regla de Enmascaramiento Dinámico en Vertica
El primer paso práctico para entender cómo enmascarar datos sensibles en Vertica implica definir una regla de enmascaramiento dinámico. Esta regla especifica qué instancia de Vertica proteger, qué columnas son sensibles y cómo debe comportarse el enmascaramiento.
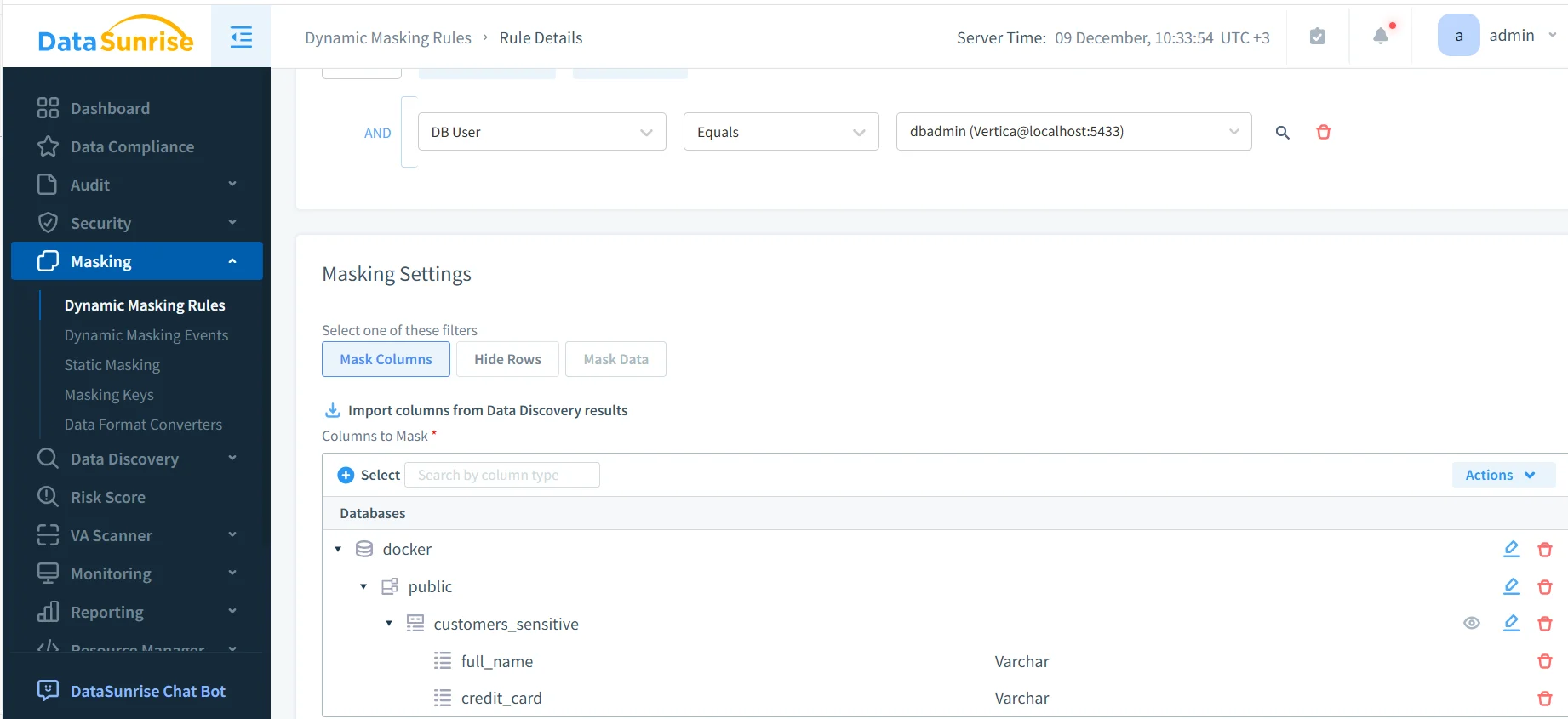
En este ejemplo, el administrador configura una regla de enmascaramiento para una instancia de base de datos Vertica y la aplica a un esquema y tabla específicos. Columnas sensibles como full_name y credit_card se seleccionan explícitamente. Una vez activada, la regla se aplica automáticamente a cada consulta que coincida.
Los administradores pueden refinar aún más las reglas de enmascaramiento usando condiciones como:
- Usuario o rol de base de datos
- Tipo de aplicación cliente
- Ubicación de red o entorno
Dado que la regla opera fuera de Vertica, permanece efectiva incluso cuando los esquemas evolucionan o cambian las proyecciones.
Resultados de Consultas Enmascaradas en la Práctica
Desde la perspectiva del usuario, el enmascaramiento dinámico no cambia la forma en que se escriben las consultas. Los analistas emiten las mismas sentencias SQL de siempre. Sin embargo, la diferencia se vuelve visible en los valores retornados.
Sin enmascaramiento, los resultados incluirían nombres reales, números de tarjeta o detalles de teléfono. Con el enmascaramiento habilitado, los usuarios sin privilegios reciben valores anonimizados o parcialmente ocultos. Al mismo tiempo, las agregaciones, uniones y filtros continúan funcionando correctamente, por lo que los flujos analíticos permanecen intactos.
Este enfoque se alinea con los principios de minimización y seudonimización de datos definidos en el RGPD y apoya análisis seguros bajo regulaciones como HIPAA.
Auditoría del Acceso Enmascarado en Vertica
El enmascaramiento por sí solo no satisface los requisitos de cumplimiento. Las organizaciones también deben demostrar que el enmascaramiento se aplicó consistentemente. Por lo tanto, el enmascaramiento dinámico trabaja en conjunto con la auditoría.
Cada consulta enmascarada genera un registro de auditoría que captura:
- El usuario de base de datos y la aplicación cliente
- La sentencia SQL ejecutada
- La regla de enmascaramiento que se aplicó
- La marca temporal y el contexto de ejecución
En lugar de analizar múltiples tablas del sistema Vertica, los equipos de cumplimiento revisan una pista de auditoría centralizada. En consecuencia, las investigaciones se vuelven más rápidas y las auditorías regulatorias más sencillas. Para conceptos relacionados, consulte Monitoreo de Actividad de Bases de Datos.
Enmascaramiento Dinámico Comparado con Otros Enfoques
| Enfoque | Descripción | Limitaciones |
|---|---|---|
| Tablas enmascaradas estáticas | Copias pre-enmascaradas de datos de producción | Mantenimiento alto, duplicación de datos |
| Vistas SQL | Columnas enmascaradas expuestas a través de vistas | Eludidas por consultas ad-hoc |
| Solo RBAC | Permisos a nivel de tabla o esquema | Sin protección a nivel de columna |
| Enmascaramiento dinámico de datos | Oculta valores en tiempo de consulta | Requiere capa de aplicación externa |
Mejores Prácticas para Enmascarar Datos Sensibles en Vertica
- Comience con el descubrimiento. La clasificación automatizada provee la base para un enmascaramiento efectivo.
- Centralice las políticas. Mantenga la lógica de enmascaramiento en DataSunrise en lugar de dispersarla en vistas SQL.
- Pruebe cargas reales. Valide el enmascaramiento usando consultas reales de BI y notebooks.
- Revise auditorías regularmente. La monitorización continua ayuda a detectar patrones de acceso inesperados tempranamente.
- Alinee con la estrategia de seguridad. Coordine el enmascaramiento con controles más amplios de seguridad de datos.
Conclusión
Cómo enmascarar datos sensibles en Vertica se resume en aplicar la protección en la capa correcta. Al enmascarar datos dinámicamente en tiempo de consulta, las organizaciones preservan el poder analítico de Vertica mientras reducen el riesgo de exponer información confidencial.
Con una puerta de enlace dedicada al enmascaramiento, los valores sensibles permanecen protegidos en dashboards, scripts y pipelines. Como resultado, los analistas continúan trabajando productivamente, mientras que los equipos de cumplimiento ganan visibilidad y control. Este equilibrio convierte al enmascaramiento dinámico en una capacidad fundamental para análisis seguros en Vertica.
