Enmascaramiento de Datos en Vertica
El enmascaramiento de datos en Vertica consiste en permitir que los analistas trabajen con estructuras de datos reales mientras se ocultan los valores que nunca deberían mostrarse en texto claro. Vertica es una base de datos analítica de alto rendimiento que se usa frecuentemente para paneles de BI, análisis de clientes, almacenes de características para ML y exploración ad hoc en grandes conjuntos de datos columnarios. Esa flexibilidad es valiosa para el negocio, pero también significa que campos regulados como números de tarjetas, identificaciones nacionales y atributos médicos pueden filtrarse fácilmente en consultas, exportaciones o conjuntos de datos de entrenamiento si no se aplica una capa de protección.
Intentar resolver esto solo con permisos manuales, tablas copiadas o vistas SQL escritas a mano se vuelve rápidamente doloroso. Los esquemas cambian, aparecen nuevas proyecciones, los trabajos ETL crean tablas derivadas, y de repente nadie está seguro de qué columna es realmente segura para exponer. En lugar de perseguir cada consulta, los equipos necesitan una capa de enmascaramiento que funcione automáticamente para cada carga de trabajo de Vertica.
El enmascaramiento de datos con DataSunrise ofrece esa capa a los usuarios de Vertica. DataSunrise se sitúa entre Vertica y las herramientas cliente, detecta campos sensibles y reescribe los resultados de las consultas al vuelo para que los valores confidenciales queden ocultos, tokenizados o parcialmente revelados según la política. Vertica sigue haciendo lo que mejor sabe—análisis rápidos—mientras que la lógica de enmascaramiento, los registros de auditoría y las reglas de cumplimiento viven en un plano de control separado y dedicado.
Por Qué Vertica Necesita una Capa Dedicada de Enmascaramiento
La arquitectura de Vertica la hace potente y a la vez complicada. Los datos se almacenan en contenedores columnarios ROS, los cambios recientes viven en WOS, y las proyecciones ofrecen múltiples disposiciones físicas para la misma tabla lógica, como se describe en la documentación de arquitectura de Vertica. Este diseño es ideal para el rendimiento, pero complica preguntas como “¿Dónde exactamente están los números de tarjeta de cliente?” o “¿Qué cargas de trabajo manipulan PHI hoy?”
Los problemas comunes incluyen:
- Tablas analíticas muy amplias que agrupan docenas de atributos (incluyendo PII y PHI) en una sola estructura.
- Múltiples proyecciones que replican físicamente columnas sensibles a través del clúster.
- Clústers compartidos usados simultáneamente por BI, ETL, notebooks y frameworks de ML.
- SQL ad-hoc de usuarios avanzados y científicos de datos que evaden capas de informes seleccionadas.
- Registros dispersos que dificultan reconstruir quién vio qué y cuándo.
El control de acceso basado en roles (RBAC) de Vertica controla quién puede conectar y qué objetos puede consultar. Sin embargo, no entiende si una consulta determinada está exportando números de tarjetas, uniendo datos de RRHH y CRM de forma insegura o poblando un entorno no productivo con detalles reales de clientes. Para cerrar esas brechas, las organizaciones implementan un motor externo de enmascaramiento y políticas que entiende la sensibilidad de las columnas y el contexto del usuario.
Cómo DataSunrise Entrega el Enmascaramiento de Datos en Vertica
DataSunrise actúa como un proxy transparente delante de Vertica. Las herramientas BI, clientes SQL, programadores y plataformas de ciencia de datos se conectan a DataSunrise en lugar de hablar directamente con Vertica. Para cada consulta, DataSunrise analiza el SQL, verifica qué columnas son sensibles, evalúa políticas de enmascaramiento y luego pasa la consulta sin cambios o reescribe el conjunto de resultados para que los valores confidenciales nunca salgan de la base de datos en forma clara.
En su núcleo, este motor de enmascaramiento combina varias capacidades:
- Descubrimiento de datos sensibles para identificar columnas que contienen PII, PHI o identificadores financieros.
- Enmascaramiento dinámico de datos que altera en tiempo real los conjuntos de resultados basándose en el usuario, la aplicación o el contexto de red.
- Enmascaramiento estático de datos para generar conjuntos de datos seguros para entornos no productivos.
- Registro de auditoría que documenta cada consulta enmascarada como evidencia de cumplimiento.
Las capturas de pantalla que siguen muestran un conjunto típico de configuración de enmascaramiento en Vertica: definir una regla de enmascaramiento, elegir columnas para proteger y verificar que las consultas se enmascaren y auditen correctamente.
Definiendo una Regla de Enmascaramiento en Vertica
El primer paso es crear una regla de enmascaramiento y vincularla a la instancia adecuada de Vertica. En el ejemplo siguiente, la regla llamada Vertica_Masking apunta a una base de datos Vertica accesible en el puerto 5433. La regla también especifica qué ocurre cuando se activa el enmascaramiento: aquí, cada evento de enmascaramiento se escribe tanto en el almacén de auditoría de DataSunrise como en syslog externo, lo que facilita la integración con plataformas SIEM.
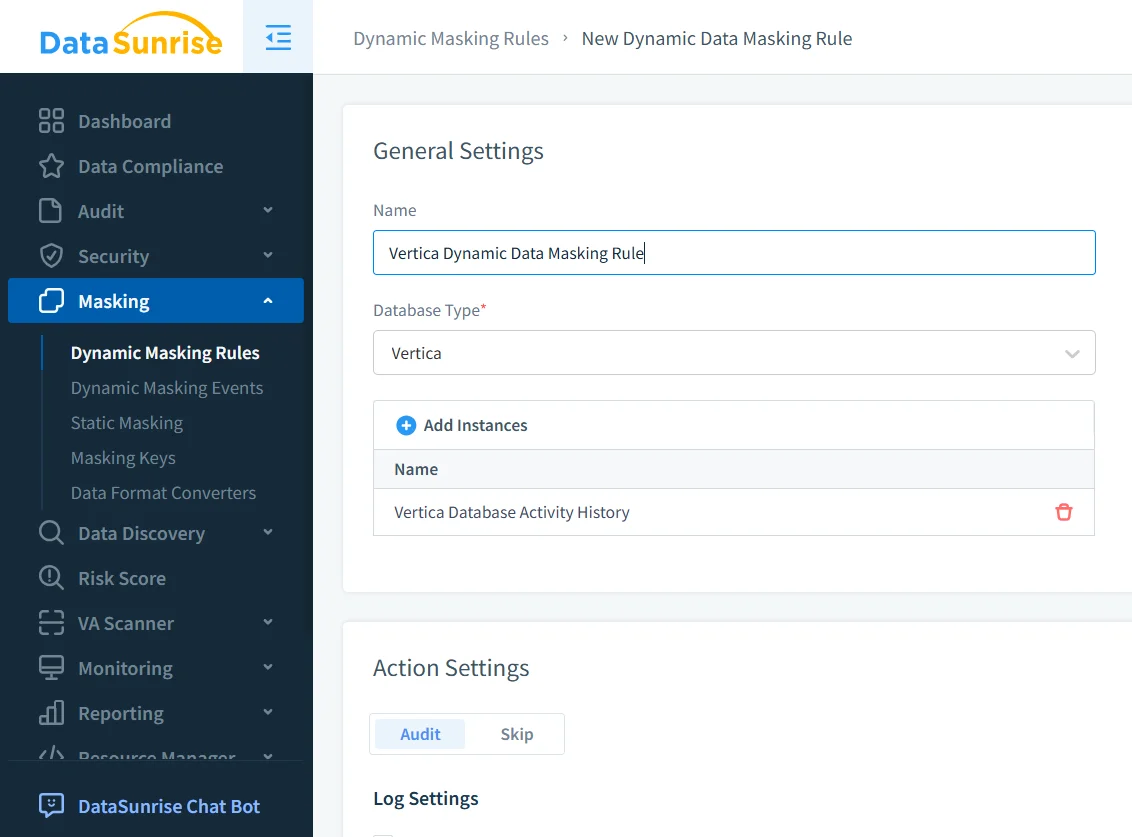
En esta etapa defines el comportamiento a alto nivel:
- A qué instancias de Vertica aplica la regla.
- Si los eventos de enmascaramiento deben auditarse, omitirse o enviarse a sistemas externos.
- Cualquier filtro global, como limitar la regla a entornos productivos.
Esta separación te permite mantener una sola política lógica “Vertica_Masking” aunque luego agregues más nodos o clústers. La lógica de enmascaramiento vive en DataSunrise, no en los esquemas de Vertica.
Seleccionando Columnas y Condiciones para el Enmascaramiento
Una vez creada la regla, eliges qué columnas de Vertica enmascarar y bajo qué condiciones. DataSunrise puede importar listas de columnas directamente desde los resultados del descubrimiento para que los administradores no tengan que mantenerlas manualmente.
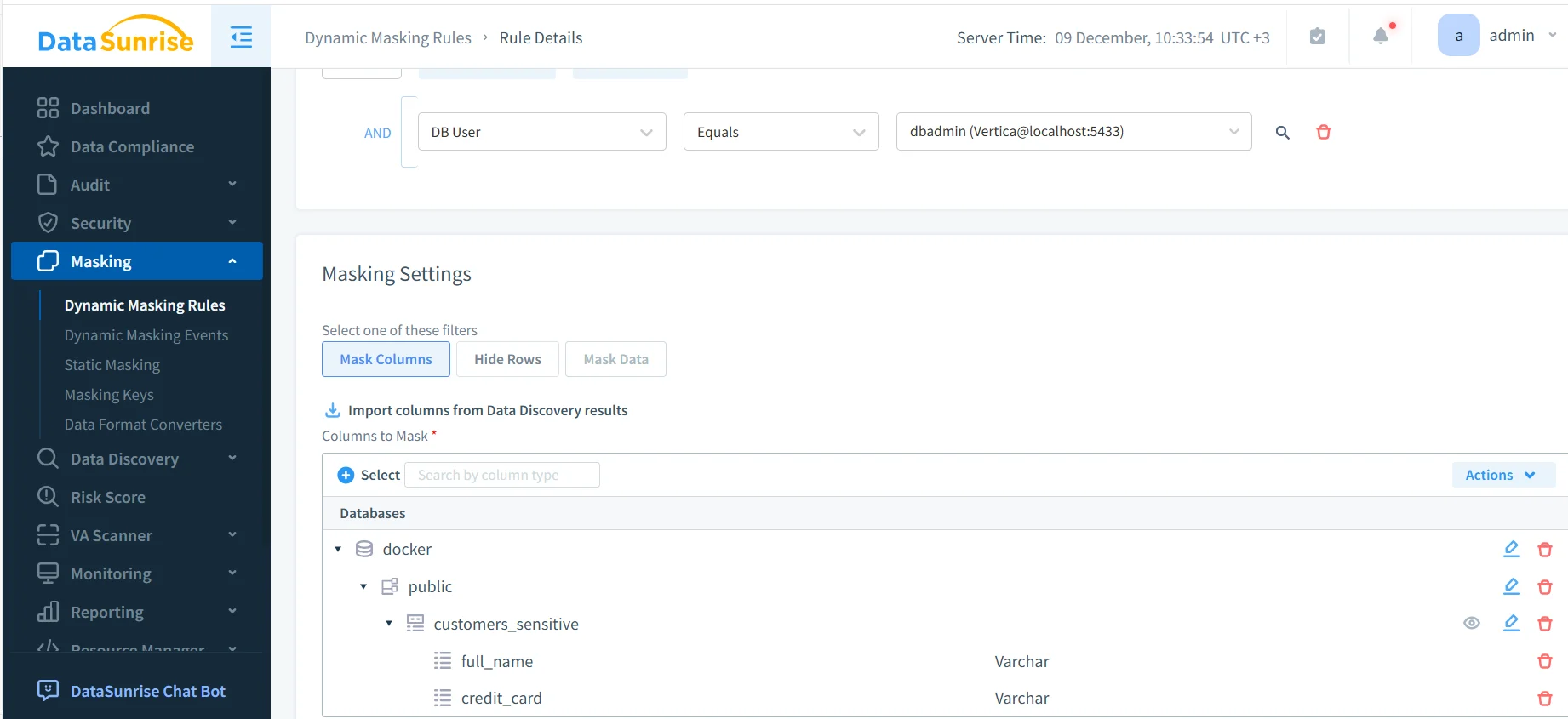
Las funciones de enmascaramiento pueden personalizarse por columna. Los números de tarjeta pueden mostrar solo los últimos cuatro dígitos, los teléfonos pueden omitir el código de país, y los nombres pueden reemplazarse totalmente o abreviarse a iniciales. El comportamiento exacto depende de las políticas internas de seguridad y de los perfiles de enmascaramiento definidos en DataSunrise.
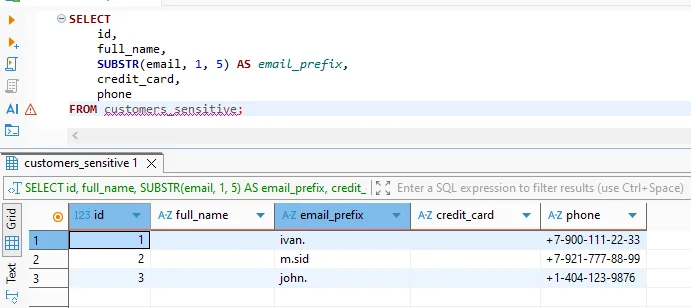
Una consulta típica emitida desde un cliente SQL o notebook podría verse así:
SELECT
id,
full_name,
SUBSTR(email, 1, 5) AS email_prefix,
credit_card,
phone
FROM customers_sensitive;
Sin enmascaramiento, esta consulta devolvería nombres reales de clientes, números de tarjetas y detalles telefónicos. Con la regla activada, los usuarios no privilegiados ven valores seudonimizados mientras el resto del conjunto de resultados permanece intacto.
Auditoría de Consultas Enmascaradas en Vertica
El enmascaramiento por sí solo no es suficiente para el cumplimiento normativo. Las organizaciones también deben demostrar que el enmascaramiento se aplicó de manera consistente. DataSunrise registra cada consulta que activó el enmascaramiento, junto con información sobre el usuario, la aplicación, el nombre de la regla y el tiempo de ejecución. Estos registros respaldan auditorías bajo regulaciones como GDPR, HIPAA y SOX.
Desde la consola de auditoría puedes:
- Filtrar por regla Vertica, usuario o aplicación para investigar incidentes.
- Exportar registros a plataformas SIEM o GRC.
- Correlacionar eventos de enmascaramiento con alertas de Monitoreo de Actividad de Base de Datos.
Puesto que todas las consultas pasan por la misma puerta de enlace, los equipos de cumplimiento obtienen una sola pista de auditoría normalizada en lugar de tener que unir múltiples tablas del sistema Vertica.
Escenarios Comunes de Enmascaramiento en Vertica
El enmascaramiento de datos en Vertica aparece en múltiples escenarios operativos y analíticos. La tabla a continuación resume casos comunes y cómo las organizaciones aplican típicamente los controles de enmascaramiento de DataSunrise.
| Escenario | Riesgo | Enfoque de Enmascaramiento |
|---|---|---|
| Paneles de BI y análisis ad hoc | Exposición de PII en informes y exportaciones | Enmascaramiento dinámico basado en roles de usuarios y cuentas de servicios BI |
| Ciencia de datos y notebooks | Uso de datos reales de clientes durante la exploración | Enmascaramiento parcial o total para entornos no productivos y roles de analistas |
| ETL y canalizaciones de datos | Propagación de datos sensibles a sistemas descendentes | Enmascaramiento aplicado en tiempo de consulta antes de que los datos salgan de Vertica |
| Almacenes de características de ML y entrenamiento de modelos | Filtración de identificadores en conjuntos de datos de entrenamiento | Seudonimización y tokenización mediante reglas de enmascaramiento dinámico |
| Auditorías regulatorias e investigaciones | Incapacidad para demostrar que se aplicó protección de datos | Resultados de consultas enmascarados combinados con pistas de auditoría centralizadas |
Conclusión
Hecho correctamente, el enmascaramiento de datos en Vertica permite a las organizaciones seguir utilizando la plataforma como un motor de análisis de alta velocidad mientras reduce drásticamente el riesgo de exponer información sensible. Al descargar la lógica de enmascaramiento, el descubrimiento y la auditoría a DataSunrise, los equipos reemplazan soluciones manuales frágiles con una protección consistente y automatizada.
Ya sea para soportar BI de autoservicio, impulsar cargas de trabajo de ML o prepararse para auditorías regulatorias, un gateway dedicado de enmascaramiento le brinda a Vertica las barreras de protección que necesita—sin ralentizar el acceso a los datos.
Protege tus datos con DataSunrise
Protege tus datos en cada capa con DataSunrise. Detecta amenazas en tiempo real con Monitoreo de Actividad, Enmascaramiento de Datos y Firewall para Bases de Datos. Garantiza el Cumplimiento de Datos, descubre información sensible y protege cargas de trabajo en más de 50 integraciones de fuentes de datos compatibles en la nube, en instalaciones y sistemas de IA.
Empieza a proteger tus datos críticos hoy
Solicita una Demostración Descargar Ahora