
Enmascaramiento Estático de Datos para Apache Impala

Introducción
Apache Impala, un motor de consultas SQL de procesamiento en paralelo masivo (MPP) de código abierto, ofrece consultas SQL de alto rendimiento y baja latencia sobre datos almacenados en Apache Hadoop y otros sistemas de almacenamiento distribuidos. Al trabajar con datos sensibles en entornos de Impala, las organizaciones a menudo necesitan medidas de seguridad robustas como el enmascaramiento de datos y diversas técnicas de enmascaramiento de datos.
Un enfoque particularmente efectivo es el enmascaramiento estático de datos, que implica crear copias anonimizadas de los datos de producción para desarrollo y pruebas, manteniendo el cumplimiento de las normativas de protección de datos. Este artículo explorará las diversas opciones de enmascaramiento estático disponibles en Impala.
¿Qué es el Enmascaramiento Estático de Datos?
El enmascaramiento estático de datos crea una copia saneada de su data warehouse. Reemplaza la información sensible con datos ficticios pero realistas, permitiendo a las organizaciones utilizar datos enmascarados en entornos no productivos sin arriesgar la exposición de información confidencial.
Capacidades Nativas de Enmascaramiento de Apache Impala
Apache Impala ofrece varias funciones integradas para la protección básica de datos que pueden ser bastante efectivas para casos de uso sencillos. Estas capacidades nativas permiten a las organizaciones crear copias enmascaradas de sus data warehouses para pruebas y desarrollo.
Uso de las Funciones Integradas de Impala
Impala ofrece varias funciones integradas que se pueden combinar para crear estrategias efectivas de enmascaramiento. A continuación se muestra un ejemplo práctico que demuestra patrones comunes de enmascaramiento:
CREATE TABLE masked_customer_data AS
SELECT
customer_id,
CONCAT(SUBSTR(name, 1, 1), '***') AS masked_name,
REGEXP_REPLACE(email, '(.*)@(.*)', '[email protected]') AS masked_email,
CONCAT('XXXX-XXXX-XXXX-', SUBSTR(credit_card, -4)) AS masked_card
FROM customer_data;
La tabla enmascarada contendrá datos anonimizados pero con apariencia realista que mantienen la integridad referencial al tiempo que protegen la información sensible.
Creación de Vistas Protegidas
Para requisitos de enmascaramiento más complejos, se pueden crear copias estáticas protegidas utilizando vistas. Este enfoque es particularmente útil cuando se necesitan diferentes niveles de enmascaramiento para distintos tipos de información sensible:
CREATE TABLE masked_data AS
SELECT
id,
-- Reemplaza el campo completo con un valor estático
'MASKED' AS sensitive_field,
-- Conserva datos parciales donde sea necesario
SUBSTR(account_number, -4) AS last_four_digits,
-- Enmascara fechas conservando el año
CONCAT(YEAR(birth_date), '-XX-XX') AS masked_birth_date
FROM source_table;
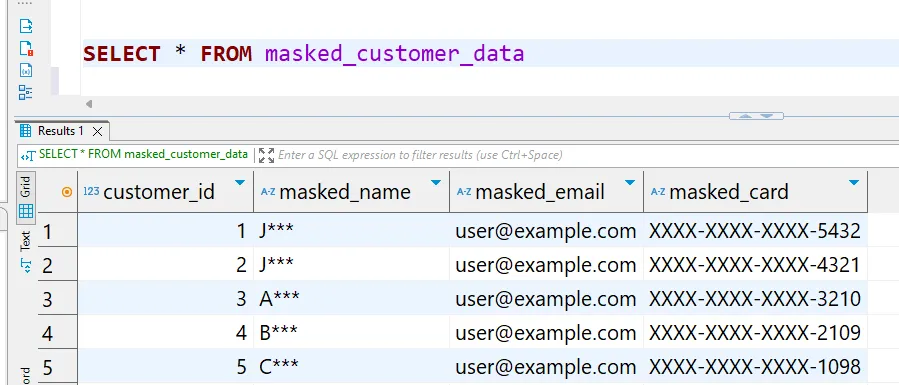
Ejemplo de salida en una consulta SELECT *:

Estas técnicas de enmascaramiento proporcionan una base sólida para proteger datos sensibles en entornos de desarrollo y pruebas, manteniendo al mismo tiempo la utilidad de los datos en casos de uso no productivos. Las copias enmascaradas retienen la estructura y relaciones originales de los datos, lo que las hace adecuadas para pruebas de aplicaciones y trabajos de desarrollo.
Consejos Prácticos para el Enmascaramiento en Impala
1. Enmascaramiento Consistente: Para campos como las direcciones de correo electrónico que aparecen en múltiples tablas, utilice la misma función de enmascaramiento en todas partes para mantener la consistencia.
2. Consideración de Rendimiento: Cree tablas enmascaradas en lugar de vistas cuando los datos no cambien con frecuencia. Este enfoque:
- Reduce la sobrecarga de procesamiento
- Mejora el rendimiento de las consultas
- Hace que los datos enmascarados estén disponibles de inmediato
3. Preservación del Formato de los Datos: Note cómo nuestro enmascaramiento mantiene el formato original de los datos:
- Las tarjetas de crédito conservan el formato XXXX-XXXX-XXXX-1234
- Los correos electrónicos siguen teniendo un aspecto válido con “@dominio.com”
- Los nombres conservan una estructura legible
Recuerde que, si bien estas capacidades nativas son útiles para necesidades básicas de enmascaramiento, los entornos empresariales a menudo requieren soluciones más sofisticadas que ofrezcan funciones adicionales como descubrimiento de datos, enmascaramiento consistente a través de bases de datos y opciones avanzadas de encriptación.
Enmascaramiento Avanzado de Datos para Apache Impala con DataSunrise
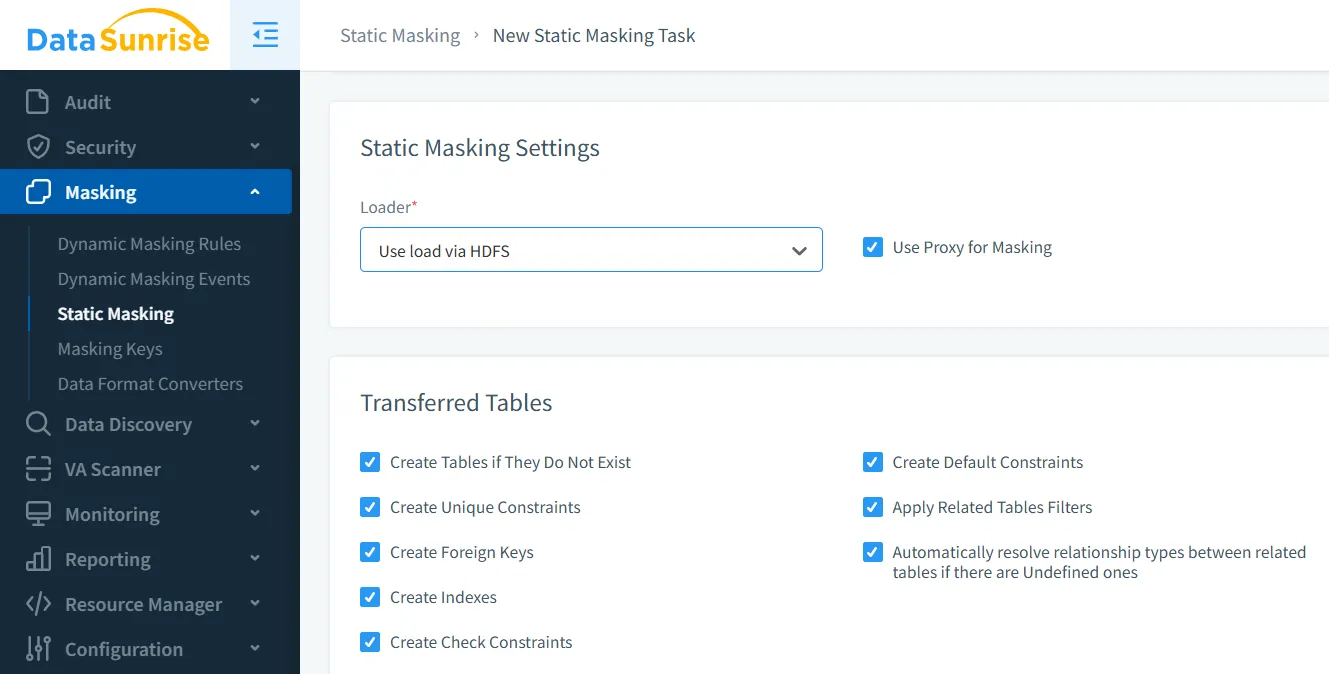
A diferencia de las funciones SQL personalizadas tradicionales para enmascaramiento estático, DataSunrise automatiza todo el proceso, reduciendo el esfuerzo y la complejidad implicados. DataSunrise sobresale en el enmascaramiento estático de datos al ofrecer una solución más amplia y conveniente.
Con varios tipos de enmascaramiento disponibles, incluyendo opciones tanto de enmascaramiento dinámico como estático, puede crear una copia de los datos en la que la información sensible se enmascara, pero se conserva el valor de los datos y la estructura original, lo que la hace ideal para casos de uso como pruebas, desarrollo y cumplimiento normativo.
Características del Enmascaramiento Estático de Datos en DataSunrise:
- Integridad y Consistencia de los Datos: Retiene la estructura de datos original para pruebas y análisis mientras preserva las relaciones entre tablas relacionadas mediante el enmascaramiento consistente de la información sensible.
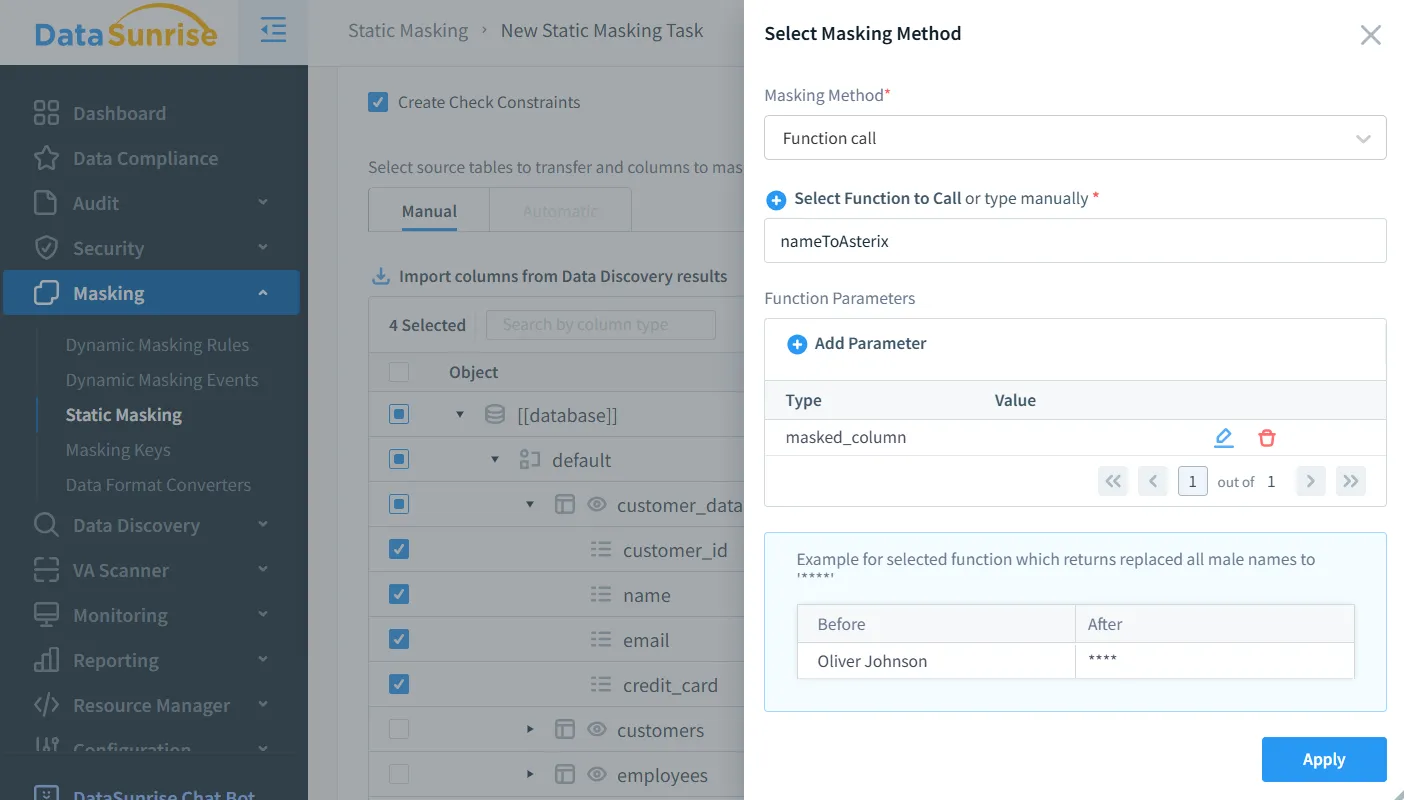
- Algoritmos Personalizables: Cuenta con una extensa biblioteca de plantillas de enmascaramiento preconstruidas, además de la capacidad de crear lógica de enmascaramiento personalizada mediante funciones definidas por el usuario y scripts Lua, lo que permite a las organizaciones implementar reglas de anonimización de datos tanto estandarizadas como altamente especializadas.
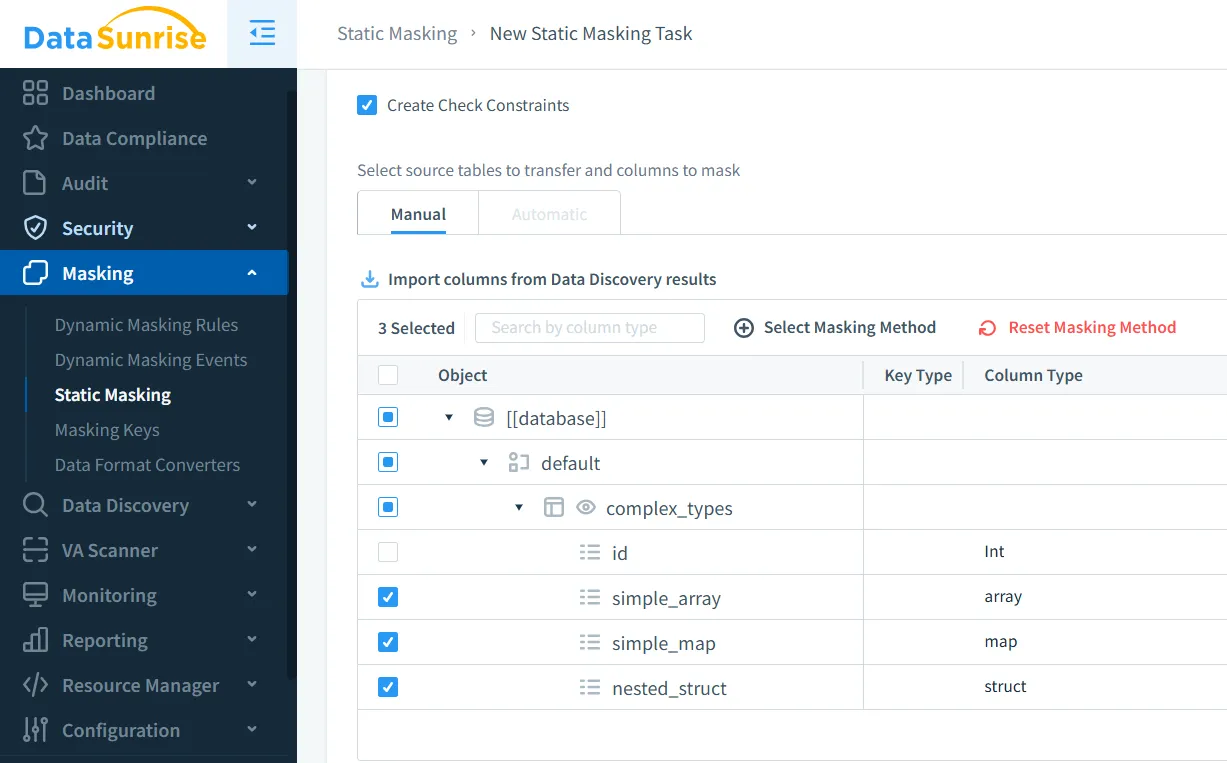
Soporte para Tipos de Datos Complejos y Formatos de Tablas: Maneja de forma integral las estructuras de datos específicas de Hive, desde simples ARRAYs y MAPs hasta combinaciones profundamente anidadas de tipos complejos (como ARRAY<STRUCT> o MAP<STRING, ARRAY>), manteniendo las relaciones y la integridad de la estructura de los datos durante las operaciones de enmascaramiento. Soporta varios formatos de almacenamiento de tablas de Hive incluyendo ORC, PARQUET, TEXTFILE, manteniendo un comportamiento de enmascaramiento consistente a través de diferentes implementaciones de almacenamiento subyacentes.
Conclusión
El enmascaramiento estático de datos para Apache Impala es una herramienta crucial para proteger la información sensible y garantizar el cumplimiento normativo en entornos de big data. Ya sea utilizando las funciones integradas de Impala o soluciones integrales como DataSunrise, las organizaciones pueden salvaguardar eficazmente la información confidencial al tiempo que mantienen la utilidad de los datos para desarrollo y pruebas.
DataSunrise ofrece herramientas flexibles y fáciles de usar para una seguridad completa de bases de datos, incluyendo funciones de auditoría, enmascaramiento y descubrimiento de datos. Para obtener más información sobre cómo DataSunrise puede mejorar la protección de sus datos en Impala, visite nuestro sitio web para una demostración en línea y explore nuestra gama completa de soluciones de seguridad.
