
Enmascaramiento Estático de Datos
Introducción
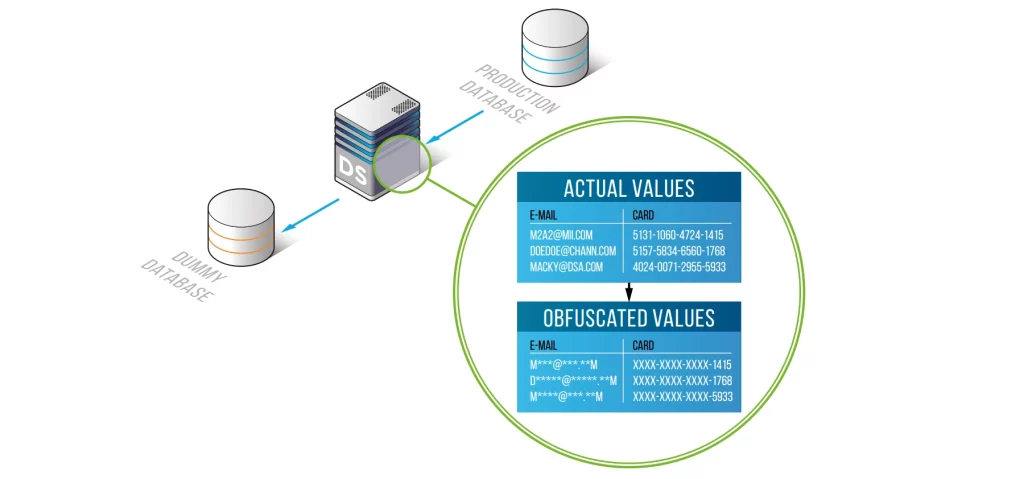
El enmascaramiento estático de datos protege la información sensible generando una copia segura y anonimizada de los datos de producción en la que los campos confidenciales son reemplazados por valores ficticios pero realistas. Debido a que el conjunto de datos resultante mantiene el esquema original, las relaciones y el formato de los datos, sigue siendo totalmente utilizable para pruebas, análisis, desarrollo de software y aprendizaje automático, sin exponer información personal identificable, registros financieros ni datos de salud a personas no autorizadas. Este enfoque permite a las organizaciones equilibrar la utilidad de los datos con estrictos requerimientos de privacidad y cumplimiento normativo. La guía de estándares como el marco de protección de datos ISO/IEC 27559 enfatiza aún más la importancia de prácticas robustas de anonimización.
Este artículo explora los principios clave del enmascaramiento estático de datos, explica cómo se diferencia del enmascaramiento dinámico, y examina su papel crítico en la gestión de cumplimiento, garantía de privacidad y reducción de riesgos. También demuestra cómo DataSunrise simplifica la implementación mediante flujos de trabajo automatizados, asegura la integridad referencial en conjuntos de datos complejos, y soporta entornos de bases de datos heterogéneos, tanto locales como en la nube. Además, el enmascaramiento estático es invaluable para compartir datos de forma segura con proveedores externos, socios de investigación o equipos de prueba, así como para habilitar procesos seguros de migración a la nube donde solo conjuntos de datos anonimizados y listos para cumplimiento salen del perímetro protegido de producción.
Enmascaramiento Estático vs Dinámico: Diferencias Clave
Ambas técnicas protegen los campos sensibles, pero sirven para diferentes necesidades operativas.
El enmascaramiento estático de datos genera una nueva copia enmascarada de la base de datos donde el contenido sensible es reemplazado por valores sintéticos, ideal para desarrollo/pruebas, entregas a proveedores y compartición segura de datos.
Por el contrario, el enmascaramiento dinámico opera en tiempo de ejecución, enmascarando resultados de consultas basándose en el contexto de acceso sin modificar los datos almacenados, siendo mejor para control de acceso en vivo dentro de aplicaciones.
| Característica | Enmascaramiento Estático | Enmascaramiento Dinámico |
|---|---|---|
| Cómo Funciona | Genera una copia enmascarada de la base de datos | Modifica la salida de consultas en tiempo real |
| Casos de Uso | Desarrollo/pruebas, acceso externo | Control de acceso en producción en vivo |
| Rendimiento | Sin impacto en tiempo de ejecución | Aplicado al vuelo |
| Seguridad de Datos | Seguro para exportación y compartición | Requiere políticas de protección en tiempo real |
Cuándo Utilizar Enmascaramiento Estático
El enmascaramiento estático de datos es especialmente valioso cuando la información sensible necesita ser trasladada fuera de su entorno original de producción. Permite a los equipos trabajar con conjuntos de datos realistas asegurando que no se exponga información personal identificable o regulada. Los casos de uso más comunes incluyen:
- Entornos de desarrollo y prueba: Permite a desarrolladores e ingenieros construir, depurar y optimizar funcionalidades usando datos que reflejan la complejidad del mundo real, sin revelar identidades reales de clientes, detalles de pago o registros confidenciales.
- Sistemas de aseguramiento de calidad y preproducción: Replica condiciones de producción para pruebas funcionales, de rendimiento o integración sin introducir riesgos de cumplimiento o privacidad.
- Capacitación y entrenamiento de empleados: Proporciona a nuevos empleados y equipos de soporte ejemplos realistas que mejoran los resultados de aprendizaje protegiendo completamente la información sensible.
- Colaboración externa: Comparte conjuntos de datos de forma segura con consultores, equipos tercerizados, investigadores o proveedores sin otorgar acceso a datos regulados.
- Migraciones a la nube, respaldos y archivado: Transfiere o almacena conjuntos de datos enmascarados para reducir riesgos de exposición durante movimientos, replicación o retención a largo plazo.
Con DataSunrise, estos flujos de trabajo pueden estandarizarse y automatizarse. El enmascaramiento que preserva el formato asegura consistencia analítica y relacional, la integridad referencial se mantiene entre tablas y esquemas, y las tareas programadas garantizan que cada conjunto de datos generado permanezca conforme con las normativas a lo largo del tiempo. Además, la auditoría integrada y los controles de políticas ayudan a las organizaciones a validar el proceso de enmascaramiento y demostrar cumplimiento ante auditores y reguladores.
Cómo Aplica DataSunrise el Enmascaramiento Estático de Datos
DataSunrise soporta el enmascaramiento estático en SQL Server, Oracle, PostgreSQL, MongoDB y bases de datos en la nube como Amazon Redshift. Opera a través del servidor DataSunrise (sin cambios en el esquema). La configuración define cuatro áreas: instancias origen/destino, tablas transferidas, frecuencia de programación y reglas opcionales de limpieza.
Funciones comunes de enmascaramiento y cuándo usarlas
| Función | Ejemplo de Entrada | Salida Enmascarada | Ideal Para |
|---|---|---|---|
| FPE (AES-FFX) | 4111 1111 1111 1111 | 4129 6034 5821 4410 | Simulaciones de tarjetas de crédito |
| Redacción de Subcadena | [email protected] | al***@***.com | Emails, nombres de usuario |
| Desordenar Fecha (+/- 365d) | 1990-05-09 | 1990-12-17 | Fechas de nacimiento |
| Intercambio de Diccionario | Chicago | Frankfurt | Campos de ciudad / país |
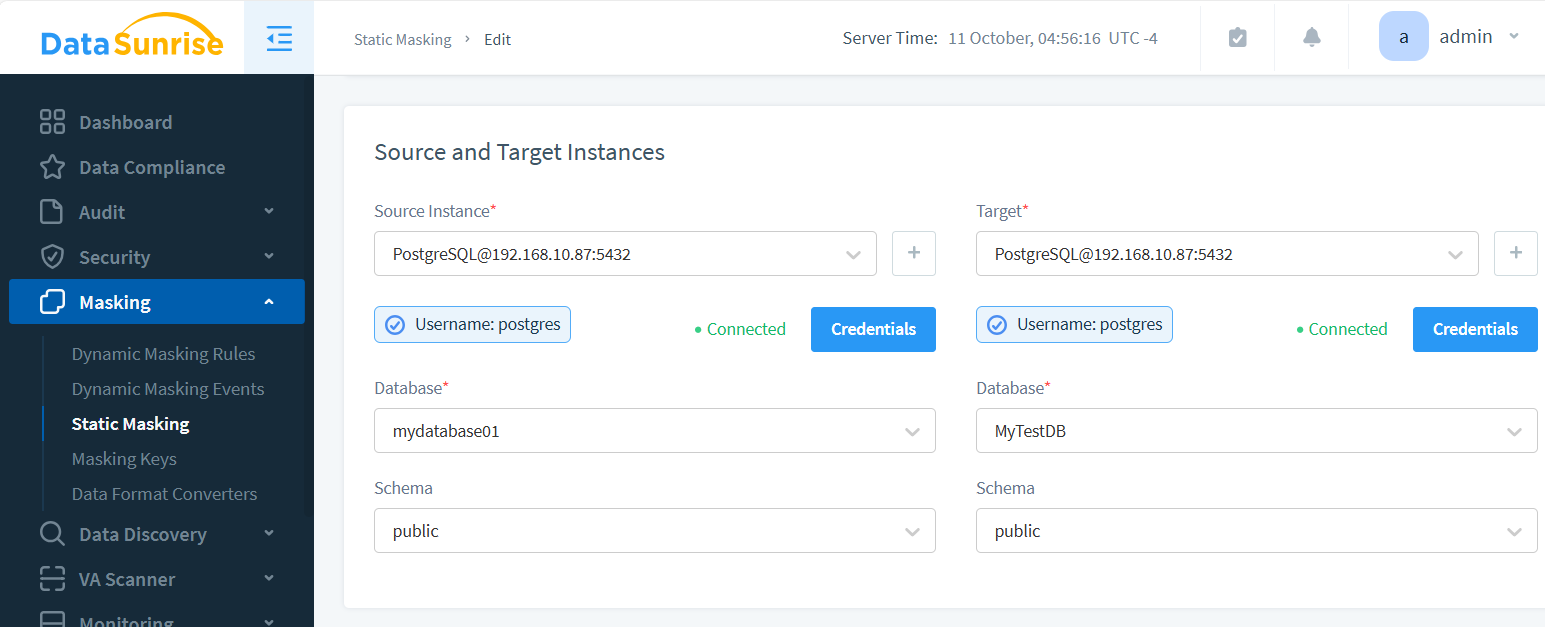
Instancias Origen y Destino
El proceso de enmascaramiento genera una nueva instancia con datos enmascarados. El origen contiene el contenido original; el destino es donde residirán los datos ofuscados.
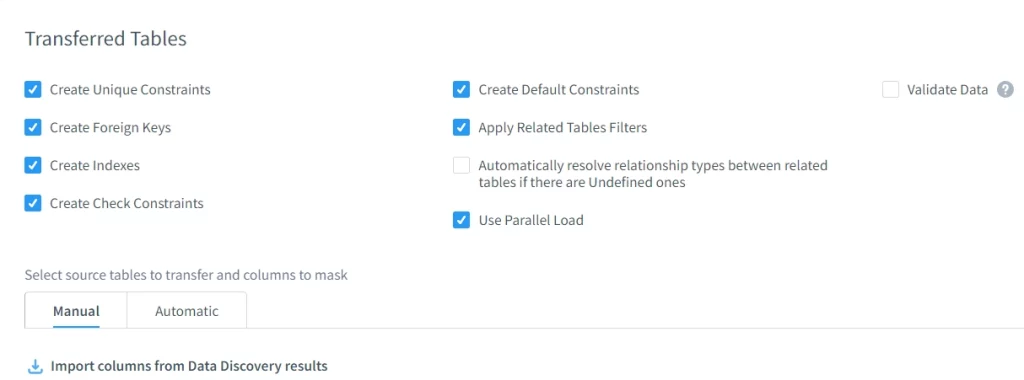
Tablas Transferidas
DataSunrise preserva la integridad referencial, restricciones, índices y relaciones entre tablas enmascaradas, manteniendo la usabilidad de los datos tras la ofuscación.
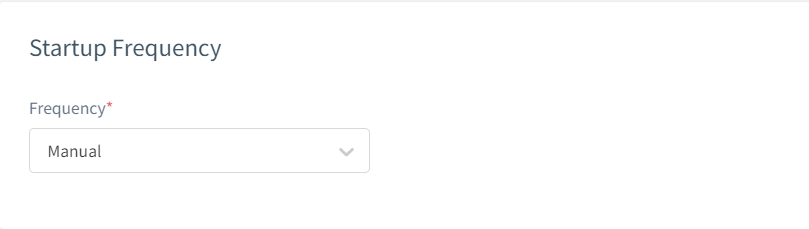
Frecuencia de Inicio
Ejecute tareas manualmente, prográmelas una sola vez o configure intervalos recurrentes. Esto automatiza los procesos de actualización de datos y mantiene los entornos de prueba al día.
Eliminar Resultados Más Antiguos Que
Aplicar retención para eliminar bases de datos enmascaradas obsoletas. Esto ahorra espacio de almacenamiento y reduce el desorden operativo.
Simulación de Enmascaramiento Estático en PostgreSQL
Aquí se muestra cómo podría simularse un enmascaramiento estático manualmente sin automatización:
-- Paso 1: Crear copia enmascarada de una tabla
CREATE TABLE customers_masked AS
SELECT
id,
name,
email,
'XXXX-XXXX-XXXX-' || RIGHT(card_number, 4) AS card_number
FROM customers;
-- Paso 2: Enmascarar formato de email
UPDATE customers_masked
SET email = CONCAT(LEFT(email, 2), '***@***.com');
Esto funciona para enmascaramientos a pequeña escala, pero carece de lógica para preservar formato, aplicación de claves foráneas y registro de auditoría. DataSunrise automatiza y escala este flujo de trabajo en múltiples plataformas.
Ejemplo Práctico: PostgreSQL + DataSunrise
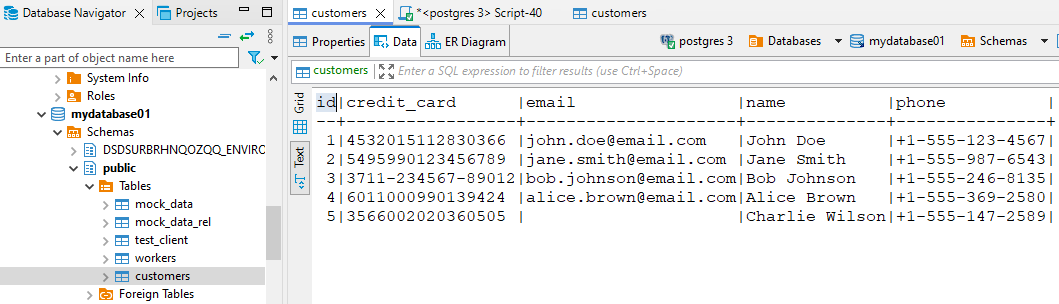
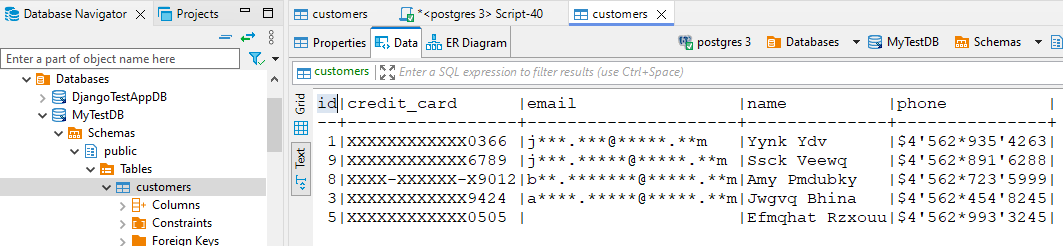
Considere una base de datos PostgreSQL con datos de clientes incluyendo nombres, emails y números de tarjeta. Vista sin enmascarar:
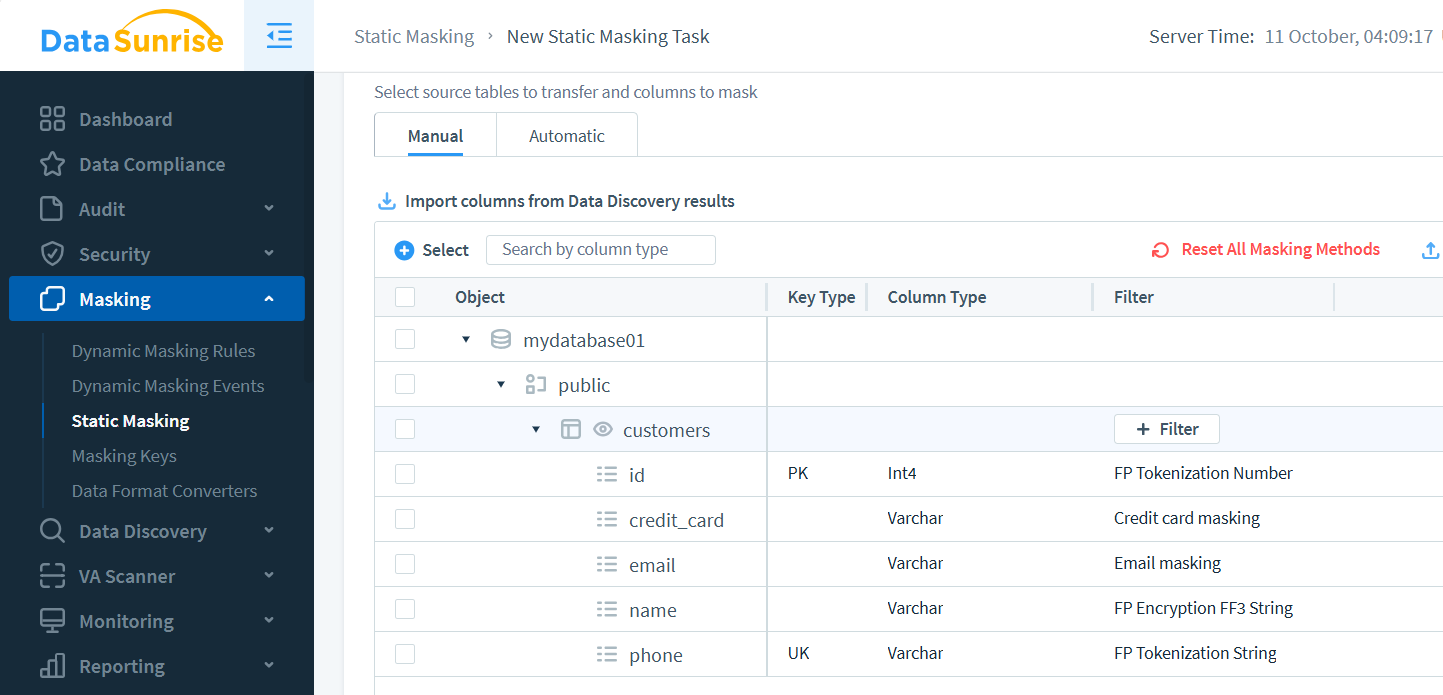
En DataSunrise, configure una tarea mediante el panel de Enmascaramiento Estático. Seleccione instancias, defina tablas y elija métodos de enmascaramiento por columna:
Una vez completada la tarea, verá la confirmación en el estado de la misma:
La instancia destino ahora contiene una versión completamente enmascarada de los datos:
Enmascaramiento Estático con DataSunrise: Ventajas Clave
- Datos realistas para desarrollo y pruebas
- Ofuscación que preserva el formato
- Integridad referencial mantenida
- Cero impacto en sistemas fuente
- Preparado para cumplimiento GDPR/PCI/HIPAA
Mejores Prácticas para el Enmascaramiento Estático de Datos
Incluso con la herramienta adecuada, la efectividad depende de una implementación precisa. Use estas prácticas para mantener el enmascaramiento seguro, escalable y listo para auditorías:
- Enmascare a nivel de columna: Diríjase solo a los campos que representan riesgo (nombres, emails, números de tarjeta) para preservar la usabilidad.
- Prefiera métodos que preserven formato para análisis: Mantenga longitud, tipo y patrones referenciales para BI, joins y exportaciones.
- Enmascare antes de descargar: Exporte copias enmascaradas a S3, almacenamiento frío o proveedores para reducir responsabilidad.
- Documente cada tarea: Rastreé origen/destino, tablas afectadas, métodos y programaciones; DataSunrise registra esto para revisión.
- Revisiones trimestrales de políticas: Actualice configuraciones conforme evolucionen esquemas y regulaciones.
Integre el enmascaramiento estático en CI/CD para que cada entorno de construcción obtenga datos saneados automáticamente. Esto elimina scripts frágiles, aplica lógica consistente y mantiene entornos de prueba alineados con producción sin exponer contenido sensible.
Hecho correctamente, el enmascaramiento estático se convierte en un control repetible e integrado en su SDLC, no en una tarea única.
Por Qué Usar el Enmascaramiento Estático con DataSunrise
- Proteja campos sensibles como PII, información financiera y credenciales antes de uso externo.
El enmascaramiento estático transforma irreversiblemente valores confidenciales, asegurando que los conjuntos de datos exportados o compartidos no pueden revelar información real de clientes, incluso si salen de su entorno seguro. - Cumpla con mandatos como GDPR, HIPAA y PCI DSS.
Anonimizando elementos sensibles en la fuente, las organizaciones satisfacen requerimientos regulatorios sobre minimización de datos, compartición segura y protección de información personal. - Comparta datos de forma segura con contratistas, analistas y terceros.
Los conjuntos de datos enmascarados facilitan la colaboración sin exponer datos en producción, reduciendo el riesgo de uso indebido interno o divulgación accidental. - Reduzca riesgos mientras soporta ambientes realistas de datos de prueba.
Desarrolladores y equipos de QA pueden usar conjuntos de datos de alta fidelidad que mantienen el valor estadístico y la lógica del negocio, sin correr el riesgo de manejar identidades o datos financieros reales. - Preserve la integridad referencial a través de esquemas complejos.
El enmascaramiento de DataSunrise mantiene relaciones consistentes entre tablas y campos, asegurando que aplicaciones, análisis y procesos de prueba continúen funcionando correctamente tras la anonimización.
Conclusión
El Enmascaramiento Estático de Datos (EED) sigue siendo un elemento fundamental de los marcos modernos de seguridad de datos, ofreciendo un método confiable y eficiente para anonimizar información sensible mientras se preserva la estructura, integridad y usabilidad de los conjuntos de datos. Al sustituir valores confidenciales por equivalentes realistas pero no identificables, las organizaciones pueden aprovechar datos similares a producción para pruebas, desarrollo, análisis y entrenamiento de modelos de IA sin arriesgar la exposición de datos personales, financieros o propietarias. Este enfoque no solo asegura el cumplimiento de regulaciones globales como GDPR, HIPAA, SOX y PCI DSS, sino que también mantiene un equilibrio óptimo entre privacidad, funcionalidad y eficiencia a lo largo de las tuberías DevOps y ecosistemas de datos empresariales.
Más allá de cumplir obligaciones regulatorias, el enmascaramiento estático juega un papel crucial en operaciones complejas como migraciones a la nube, colaboraciones con terceros e intercambio de datos interdepartamental. Sus capacidades de gestión centralizada y automatización garantizan la aplicación consistente de políticas a través de entornos híbridos y multicloud, reduciendo errores humanos y asegurando trazabilidad completa durante todo el ciclo de vida del dato. Cuando se integra con tecnologías complementarias como el enmascaramiento dinámico, el Monitoreo de Actividad de Bases de Datos (DAM) y el descubrimiento inteligente de datos, el EED se convierte en un componente vital de una estrategia unificada de gobernanza de datos.
Dentro de plataformas completas como DataSunrise, el enmascaramiento estático no solo previene exposiciones no autorizadas, sino que también mejora la flexibilidad operacional al habilitar compartición segura de datos, automatización de pruebas e innovación a gran escala. Mediante monitoreo en tiempo real, aplicación automatizada de cumplimiento y visibilidad centralizada de auditorías, transforma la privacidad de datos de una obligación reactiva en una fuerza proactiva para la confianza, resiliencia y transformación digital sostenible.
