Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica
Las Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica se están volviendo esenciales a medida que las empresas aceleran su adopción de IA generativa, generación aumentada por recuperación (RAG), ingeniería de características y análisis predictivo. Vertica frecuentemente funciona como un backend analítico de alto rendimiento para canalizaciones de aprendizaje automático, preparación masiva de datos y aplicaciones impulsadas por IA. Sin embargo, estos mismos flujos de trabajo aumentan el riesgo de exponer involuntariamente información regulada o confidencial a modelos, indicaciones y consumidores posteriores. Como resultado, las organizaciones deben adoptar herramientas automatizadas de cumplimiento capaces de monitorear, enmascarar y controlar el acceso asistido por IA a los datos de Vertica.
Los sistemas modernos de IA introducen nuevos patrones de exposición. Los modelos de lenguaje grande, agentes autónomos y cargas de trabajo de aprendizaje automático a menudo generan SQL impredecible, extraen conjuntos de datos excesivamente amplios o procesan campos sensibles como material de entrenamiento. Cuando no están protegidos, un motor LLM o ML puede revelar información privada dentro de respuestas, incrustaciones o artefactos derivados del modelo, lo que conduce a posibles incumplimientos bajo GDPR, HIPAA, PCI DSS o NIST 800-53. Debido a que Vertica no incluye de forma nativa controles de acceso conscientes de LLM, enmascaramiento dinámico, aplicación contextual o auditoría entre canalizaciones, las organizaciones deben integrar una capa especializada de cumplimiento que opere de manera proactiva antes de que los datos lleguen al modelo o capa de canalización.
DataSunrise ofrece estas capacidades. La plataforma actúa como una puerta de enlace centralizada de cumplimiento para Vertica proporcionando descubrimiento de datos sensibles, enmascaramiento dinámico, aplicación de SQL y auditoría automatizada. Juntas, estas características forman la base de las Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica.
Por qué Vertica Requiere Automatización de Cumplimiento Consciente de LLM
Las cargas de trabajo impulsadas por IA introducen desafíos de cumplimiento que los sistemas tradicionales de gobernanza no logran abordar. Por ejemplo, el SQL generado por LLM puede solicitar involuntariamente cantidades excesivas de datos sensibles. Además, las canalizaciones ETL pueden extraer corpus de entrenamiento desde Vertica sin validar si los campos subyacentes contienen PII o PHI. Mientras tanto, las arquitecturas RAG frecuentemente vectorizan columnas de texto —incluyendo aquellas que contienen identificadores personales— en incrustaciones, dificultando enormemente la gestión del linaje.
Además, la arquitectura de Vertica agrava estos riesgos. Características como proyecciones, almacenamiento ROS/WOS y esquemas analíticos amplios pueden distribuir valores sensibles a través de múltiples estructuras físicas. Debido a que Vertica opera como una plataforma analítica de alto rendimiento para una variedad de cargas de trabajo —que van desde paneles BI hasta frameworks de ML como VerticaPy— cualquier brecha de cumplimiento puede propagarse rápidamente a través de múltiples equipos y sistemas.
Para evitar fallas de cumplimiento, las organizaciones requieren Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica que automaticen:
- el descubrimiento de columnas sensibles en Vertica antes del entrenamiento de ML o ingestión RAG,
- el enmascaramiento dinámico de atributos de alto riesgo para cargas de trabajo NLP y LLM,
- la aplicación contextual de SQL para prevenir consultas inseguras o excesivas generadas por IA,
- la auditoría automatizada de todo acceso generado por IA a Vertica,
- el monitoreo para reducir el riesgo de alucinaciones en LLM que expongan valores privados.
Por consiguiente, sin controles automatizados, las canalizaciones de IA pueden ingerir involuntariamente datos sin enmascarar o revelar campos sensibles durante la inferencia.
Arquitectura de Cumplimiento de Datos NLP, LLM y ML para Vertica
El diagrama a continuación ilustra cómo las Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica funcionan como una capa de seguridad y transformación entre Vertica y las cargas de trabajo de IA. Cada solicitud LLM, ML, NLP y ETL fluye a través de esta capa de aplicación, asegurando enmascaramiento consistente, auditoría e inspección SQL.

Esta arquitectura soporta:
- asistentes LLM que generan SQL dinámicamente,
- canalizaciones RAG que consultan tablas Vertica para recuperación,
- procesos de ingeniería de características que leen columnas sensibles,
- entrenamiento ML batch que extrae conjuntos de datos directamente de Vertica.
Dado que toda la aplicación ocurre antes de que los datos de Vertica lleguen a los sistemas de IA, las organizaciones mantienen visibilidad completa, consistencia y gobernanza a través de cada flujo de trabajo NLP, LLM y ML.
Descubrimiento de Datos Sensibles en las Canalizaciones de IA con Vertica
La automatización efectiva comienza con el descubrimiento. Las Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica deben identificar todos los campos sensibles que podrían afectar los datos de entrenamiento, incrustaciones vectoriales, indicaciones o salidas de inferencia. El Descubrimiento de Datos Sensibles de DataSunrise escanea las tablas de Vertica e identifica automáticamente PII, PHI, valores financieros, tokens de autenticación y columnas de texto libre que contienen contenido regulado.
Este mecanismo de descubrimiento proactivo previene que los conjuntos de datos de entrenamiento se contaminen con información sensible. Adicionalmente, los resultados del descubrimiento se integran directamente con los módulos de enmascaramiento y aplicación SQL, asegurando que los campos recién detectados hereden automáticamente las protecciones de cumplimiento requeridas.
Enmascaramiento Dinámico para Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica
El enmascaramiento dinámico es una de las herramientas centrales de Cumplimiento de Datos NLP, LLM y ML para Vertica. Cuando los sistemas de IA generan SQL, raramente especifican qué columnas deben permanecer protegidas. Debido a esta imprevisibilidad, el enmascaramiento debe ocurrir automáticamente — basado en políticas — y no en la lógica de la aplicación.
La captura de pantalla a continuación muestra cómo los administradores configuran el enmascaramiento dinámico para los campos de Vertica que se usan frecuentemente en canalizaciones ML y NLP:
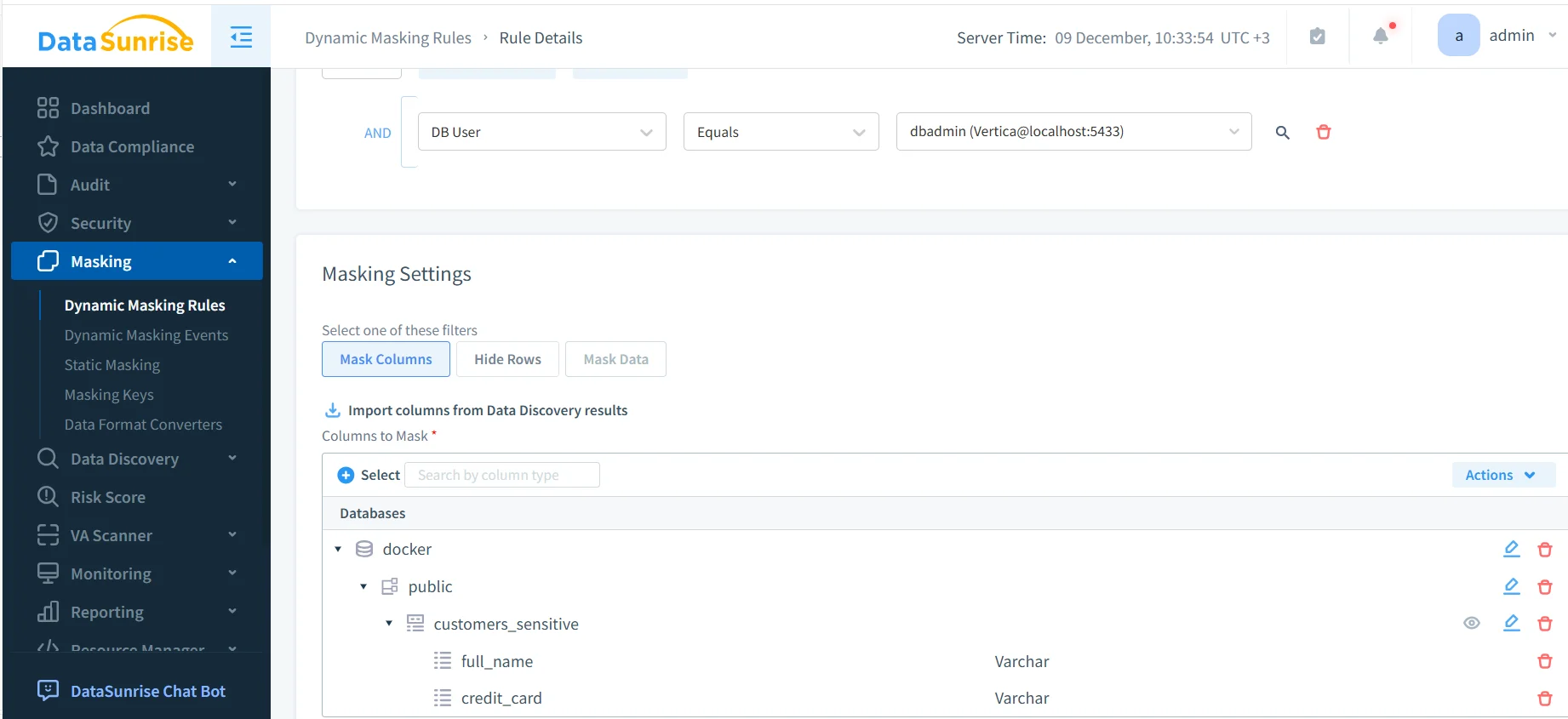
Este enmascaramiento automatizado protege atributos sensibles durante:
- la generación de indicaciones para aplicaciones LLM,
- flujos de trabajo de recuperación basados en RAG que alimentan almacenes vectoriales,
- extracciones ETL para almacenes de características ML,
- la construcción de conjuntos de datos para entrenamiento de modelos,
- exploración por científicos de datos dentro de notebooks.
Además, el enmascaramiento evita que los modelos de IA filtren valores originales dentro de respuestas, incrustaciones o artefactos de entrenamiento — alineándose con las reglas de seudonimización del GDPR y los requisitos PCI DSS.
Aplicación de SQL para Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica
El SQL generado por IA puede introducir riesgos significativos. Los LLM frecuentemente producen consultas que incluyen JOINs sin restricciones, escaneos SELECT * o extracciones de esquema completo. Además, los agentes de IA pueden generar accidentalmente sentencias de modificación como DROP TABLE o ALTER TABLE. Para abordar estos desafíos, las Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica aplican reglas contextuales de SQL antes de que la consulta llegue a Vertica.
Esta aplicación previene:
- ataques de inyección de indicaciones intentando extraer tablas sensibles o restringidas,
- escaneos de alto volumen que exponen conjuntos de datos completos a un LLM,
- alteraciones del esquema provocadas por agentes autónomos,
- recuperación excesiva de datos durante la ingeniería de características ML.
Con la automatización de la aplicación en marcha, las organizaciones obtienen confianza de que el SQL generado por LLM no puede exceder los límites de políticas.
Auditoría Automatizada para Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica
La auditoría integral es esencial para una gobernanza responsable de IA. Las Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica deben proporcionar una visión completa sobre cómo interactúan los agentes de IA, canalizaciones y aplicaciones con datos sensibles de Vertica. El registro manual es insuficiente porque las cargas de trabajo IA generan miles de consultas de manera autónoma.
DataSunrise captura automáticamente la actividad SQL, transiciones de sesión, resultados de enmascaramiento y acciones de activación de reglas. La captura de pantalla a continuación muestra un historial de auditoría unificado adecuado tanto para revisiones operacionales como para verificaciones regulatorias.
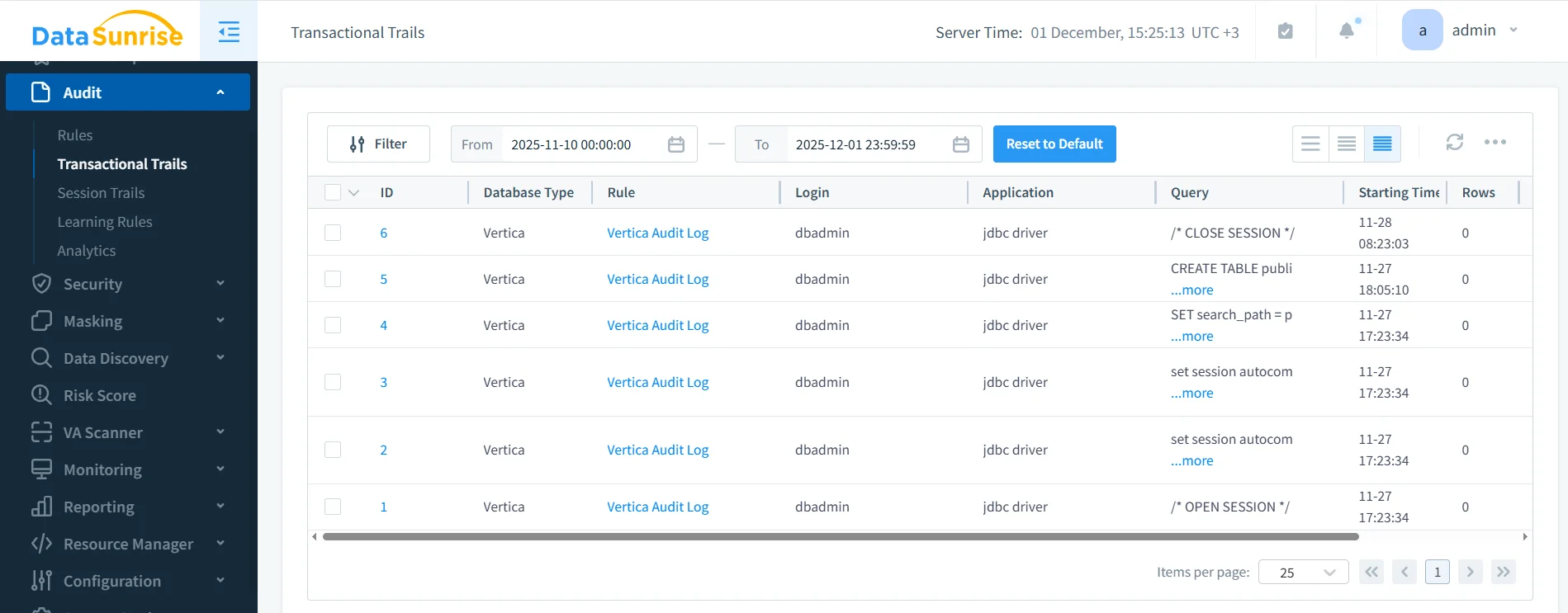
Estos registros permiten a los equipos de cumplimiento:
- rastrear cómo se generó un conjunto de datos construido por LLM,
- validar que los campos sensibles fueron enmascarados durante la ingestión,
- investigar comportamientos anómalos o de alto riesgo del modelo,
- producir evidencias de explicabilidad para implementaciones reguladas de IA.
Dado que los datos de auditoría están centralizados, las organizaciones mantienen supervisión consistente a través de todas las interacciones LLM, NLP, ETL y ML.
Comparación: Vertica vs. Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica
| Requisito de Cumplimiento AI | Capacidad Nativa de Vertica | Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica |
|---|---|---|
| Detección de PII/PHI antes del entrenamiento | Revisión manual | Descubrimiento automático de datos sensibles |
| Enmascaramiento dinámico para consultas AI | No disponible | Enmascaramiento en tiempo real |
| Aplicación SQL para LLM | Solo RBAC | Filtrado SQL basado en reglas |
| Registros de auditoría centralizados | Registros distribuidos | Historial de auditoría unificado |
| Linaje de datos de entrenamiento | Seguimiento manual | Correlación automatizada consciente de IA |
Conclusión
Las Herramientas de Cumplimiento de Datos NLP, LLM y ML para Vertica brindan a las organizaciones la capacidad de desplegar tecnologías de IA de manera segura y responsable. El enmascaramiento dinámico bloquea la exposición de valores sensibles. La aplicación de SQL previene consultas inseguras o no deseadas generadas por sistemas autónomos. La auditoría automatizada proporciona visibilidad completa y evidencia para revisiones regulatorias. En conjunto, estos controles forman un marco automatizado de cumplimiento integral que protege los datos de Vertica a lo largo de todas las cargas de trabajo NLP, LLM y ML.
