Herramientas y Técnicas de Enmascaramiento de Datos para MariaDB
Los entornos modernos de bases de datos rara vez sirven a un solo propósito. Un despliegue típico de MariaDB soporta aplicaciones, análisis, equipos de soporte, trabajos automatizados e integraciones externas. En muchos casos, todos ellos trabajan con los mismos conjuntos de datos. Cuando esos conjuntos contienen información personal, financiera o regulada, la visibilidad sin restricciones se convierte rápidamente en una responsabilidad.
Para una visión general de la arquitectura y casos de uso de MariaDB, consulte la documentación oficial: https://mariadb.org/
El enmascaramiento de datos aborda este problema transformando los valores sensibles antes de que los usuarios o aplicaciones los reciban. A diferencia del cifrado, el enmascaramiento mantiene intacta la estructura de la base de datos y el comportamiento de las consultas. Al mismo tiempo, limita lo que los usuarios pueden realmente ver. Como resultado, el enmascaramiento complementa naturalmente estrategias más amplias de seguridad de datos
y seguridad de bases de datos.
Mientras tanto, la presión regulatoria continúa creciendo y el riesgo interno se vuelve cada vez más difícil de ignorar. Por esta razón, el enmascaramiento de datos ha pasado de ser una característica “agradable de tener” a un requisito operacional. En entornos regulados, las organizaciones vinculan estrechamente el enmascaramiento con regulaciones de cumplimiento de datos
y la protección de información personal identificable (PII).
Este artículo explica cómo los equipos pueden implementar el enmascaramiento de datos en MariaDB usando técnicas nativas. También muestra cómo las plataformas centralizadas extienden el enmascaramiento a un control basado en políticas, auditable y alineado con el cumplimiento mediante mecanismos como el enmascaramiento dinámico de datos.
¿Qué es el Enmascaramiento de Datos?
El enmascaramiento de datos es una técnica de protección de datos que reemplaza valores sensibles con equivalentes modificados, ofuscados o sintéticos. Su objetivo es reducir el riesgo de exposición mientras mantiene los datos utilizables para desarrollo, análisis y flujos de trabajo operacionales. En la práctica, el enmascaramiento funciona junto con iniciativas más amplias de seguridad de datos
.
Las organizaciones pueden implementar el enmascaramiento de varias maneras. Por ejemplo, los equipos pueden aplicarlo de forma estática a copias de datos, hacerlo dinámico en tiempo de consulta o ajustarlo según la identidad del usuario, rol o ruta de acceso. Aunque cada enfoque sirve a diferentes necesidades operacionales, todos comparten el mismo objetivo: limitar la visibilidad innecesaria de valores sensibles.
La mayoría de las organizaciones utilizan el enmascaramiento para proteger información personal identificable (PII), registros financieros, secretos de autenticación y atributos sensibles para el negocio. Estos tipos de datos aparecen en muchos flujos de trabajo y grupos de usuarios. Por lo tanto, la exposición selectiva se vuelve esencial y apoya directamente las regulaciones de cumplimiento de datos.
A diferencia de los controles de acceso, el enmascaramiento de datos asume que el acceso sucederá. En lugar de bloquear consultas, controla lo que los usuarios ven en los resultados de las consultas. Este enfoque reduce el riesgo sin interrumpir el uso normal de la base de datos.
Técnicas Nativas de Enmascaramiento de Datos en MariaDB
MariaDB no proporciona un marco dedicado de enmascaramiento de datos incorporado. En su lugar, el enmascaramiento se suele aproximar usando construcciones estándar SQL. Estos enfoques pueden ser útiles para demostraciones, entornos limitados o casos de uso específicos, pero dependen de la disciplina manual más que de políticas aplicadas.
Vistas con Columnas Transformadas
Una de las técnicas más comunes es exponer datos enmascarados a través de vistas SQL que transforman columnas sensibles antes de devolver resultados.
/*CREATE VIEW masked_customers AS
SELECT
id,
CONCAT(SUBSTRING(email, 1, 3), '***@***') AS email,
'****-****-****' AS card_number
FROM customers;*/
En este modelo, se espera que las aplicaciones y usuarios consulten la vista en lugar de la tabla subyacente. La lógica de transformación está incorporada directamente en la definición de la vista, lo que vincula estrechamente el comportamiento de enmascaramiento con el diseño del esquema y enrutamiento de consultas. Como resultado, la protección de datos depende de patrones de uso consistentes más que de controles aplicados.

Limitaciones
- Efectivo solo si todo el acceso se enruta estrictamente a través de la vista
- No protege el acceso directo a tablas ni consultas ad-hoc
- Requiere mantenimiento continuo a medida que los esquemas evolucionan
- Se vuelve difícil de gestionar en muchas tablas y bases de datos
Funciones almacenadas para enmascaramiento condicional
Otro enfoque es usar funciones almacenadas para encapsular la lógica de enmascaramiento y aplicarla condicionalmente según el contexto del usuario o variables de sesión.
/*CREATE FUNCTION mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
DETERMINISTIC
RETURN CONCAT(SUBSTRING(email, 1, 3), '***@***');*/
Esta función puede referenciarse luego en sentencias SELECT o vistas, permitiendo reutilizar la misma lógica de enmascaramiento en múltiples consultas. En configuraciones más complejas, se puede introducir lógica adicional para variar el comportamiento del enmascaramiento dependiendo del usuario o rol conectado. Sin embargo, la aplicación sigue dependiendo completamente de cómo se escriben y ejecutan las consultas.
Limitaciones
- Requiere un uso disciplinado y consistente de las consultas
- La lógica de enmascaramiento debe aplicarse manualmente donde se necesite
- No hay aplicación ni visibilidad centralizada
- Es fácil evitarlo consultando directamente las tablas base
Copias enmascaradas separadas de los datos
Para entornos no productivos como desarrollo o pruebas, las organizaciones a menudo crean copias permanentemente enmascaradas de los datos de producción.
/*CREATE TABLE customers_masked AS
SELECT
id,
SHA2(email, 256) AS email,
NULL AS card_number
FROM customers;*/
Este enfoque produce un conjunto de datos donde los valores sensibles están alterados de forma irreversible, haciéndolo más seguro para compartir con desarrolladores o equipos externos. Sin embargo, el proceso de enmascaramiento está desligado del acceso a datos en vivo y debe repetirse cada vez que se actualicen los datos.
Limitaciones
- Genera duplicación de datos y sobrecarga adicional de almacenamiento
- Los conjuntos enmascarados quedan desactualizados conforme los datos de producción cambian
- No protege el acceso a producción ni las consultas en vivo
- Las reglas de enmascaramiento deben aplicarse de nuevo cada vez que se actualizan los datos
Si bien estas técnicas nativas pueden reducir la exposición accidental en escenarios limitados, no proveen un enmascaramiento de datos consistente, escalable ni auditable. A medida que los entornos crecen y los patrones de acceso se diversifican, depender únicamente del enmascaramiento basado en SQL se vuelve cada vez más frágil y difícil de gobernar.
Enmascaramiento Centralizado de Datos para MariaDB con DataSunrise
DataSunrise lleva el enmascaramiento de MariaDB más allá de los atajos a nivel SQL introduciendo una capa de seguridad centralizada basada en políticas. En lugar de incrustar la lógica de enmascaramiento en consultas, vistas o esquemas, la plataforma aplica el enmascaramiento externamente. Como resultado, los equipos protegen los datos sin modificar el código de las aplicaciones ni cambiar la estructura de la base de datos. Este modelo alinea naturalmente el enmascaramiento con prácticas más amplias de seguridad de datos y seguridad de bases de datos.
Enmascaramiento Dinámico de Datos
El enmascaramiento dinámico opera en tiempo real mientras se ejecutan las consultas. Dependiendo del contexto de ejecución, la misma columna puede aparecer enmascarada o sin enmascarar. Por ello, los equipos obtienen un control detallado sobre la exposición de datos sin reescribir SQL ni mantener esquemas paralelos. En la práctica, este enfoque implementa el enmascaramiento dinámico de datos, donde la protección es completamente transparente en el momento de la consulta.
DataSunrise evalúa las decisiones de enmascaramiento utilizando señales contextuales como usuario o rol de base de datos, dirección IP del cliente, origen de la aplicación y atributos de la sesión. Debido a esto, los analistas ven valores enmascarados, las aplicaciones continúan procesando datos reales y los administradores mantienen visibilidad completa. Todo esto funciona sin alterar consultas ni lógica de aplicación.
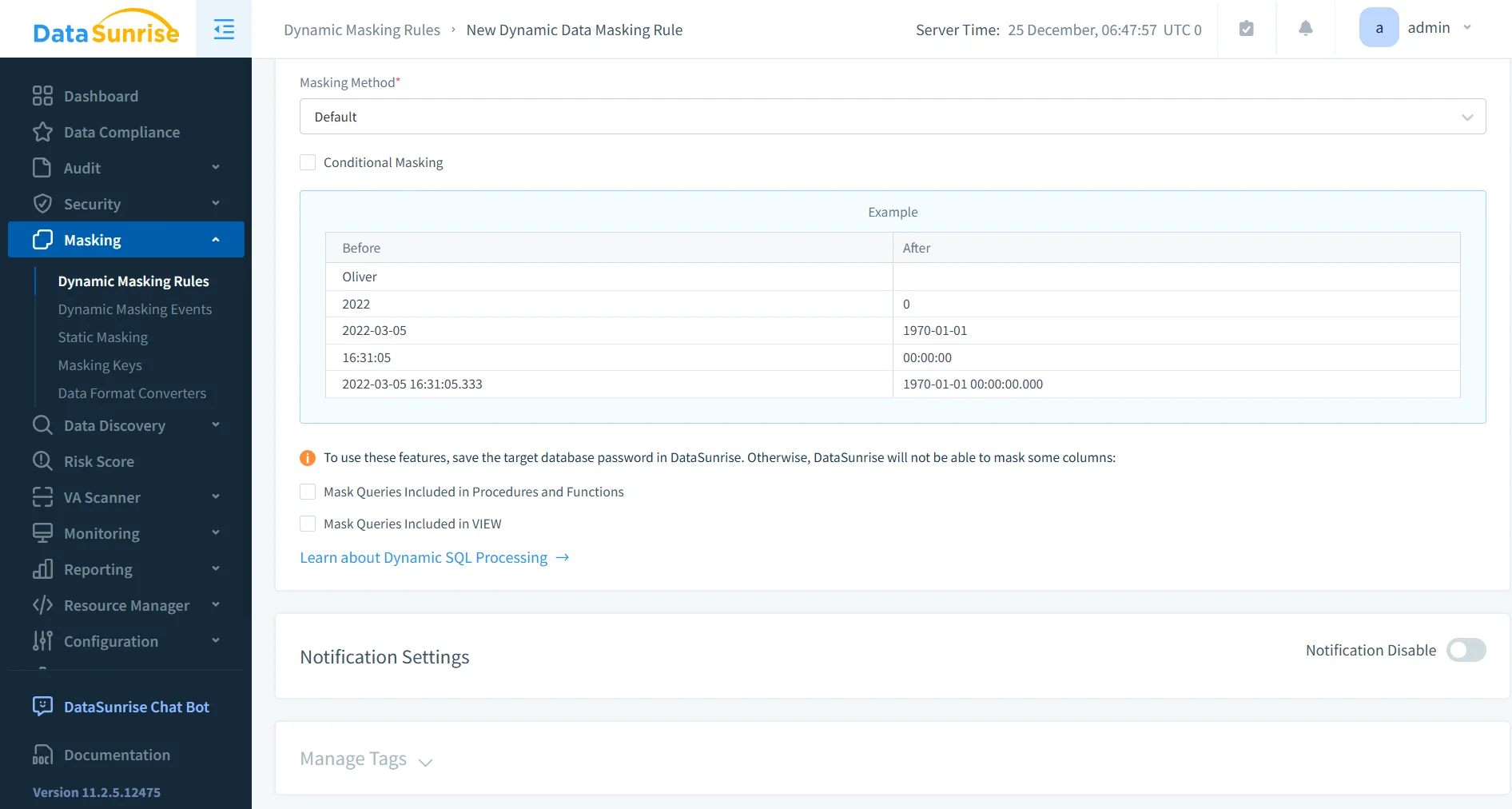
Enmascaramiento Basado en Políticas por Tipo de Dato
Una vez que los equipos descubren y clasifican los datos sensibles, DataSunrise aplica reglas de enmascaramiento automáticamente en esquemas y bases de datos basándose en el tipo de dato en lugar de columnas individuales. Este enfoque se apoya en procesos automatizados de descubrimiento y clasificación de datos. En consecuencia, la protección escala a medida que crecen los entornos.
Por ejemplo, la plataforma reemplaza correos electrónicos con formatos aleatorios pero válidos, tokeniza números telefónicos, aplica hash irreversible a identificadores y enmascara valores financieros usando sustituciones que preservan el formato. Como las reglas de enmascaramiento siguen categorías de datos en lugar de definiciones rígidas del esquema, el esfuerzo de mantenimiento a largo plazo disminuye significativamente.
Enmascaramiento Estático para Flujos de Trabajo No Productivos
Para escenarios no productivos como desarrollo, pruebas o análisis, DataSunrise soporta enmascaramiento estático controlado durante flujos operativos. Estos flujos incluyen clonado de bases de datos, restauración de respaldos, exportación de datos y provisión de datos para pruebas. En este contexto, la plataforma sigue prácticas establecidas de enmascaramiento estático de datos que permiten a los equipos reutilizar datos de producción de manera segura fuera de entornos controlados.
Como resultado, los conjuntos enmascarados permanecen consistentes, irreversibles y auditables. Esto los hace adecuados para flujos de trabajo sensibles al cumplimiento sin exponer los valores reales.
Operaciones de Enmascaramiento Auditables
DataSunrise registra toda la actividad de enmascaramiento en un historial unificado de actividades. Cada evento captura quién accedió a los datos, qué regla de enmascaramiento se aplicó, cuándo y desde dónde ocurrió el acceso. Por lo tanto, los equipos conectan directamente los controles de enmascaramiento con el monitoreo de actividad de base de datos y procesos de cumplimiento.
Al centralizar la aplicación, visibilidad y gestión de políticas, DataSunrise convierte el enmascaramiento de datos para MariaDB en un control consistente, escalable y listo para cumplimiento, en lugar de una colección de patrones SQL frágiles.
Beneficios Empresariales del Enmascaramiento Centralizado de Datos
| Área de Negocio | Impacto |
|---|---|
| Reducción del riesgo de brechas | Limita la exposición de valores sensibles aunque ocurra acceso, reduciendo el impacto de amenazas internas y uso indebido de credenciales |
| Cumplimiento regulatorio | Simplifica la alineación con GDPR, HIPAA, PCI DSS y SOX al aplicar políticas de enmascaramiento consistentes |
| Seguridad en análisis y pruebas | Permite el uso de datos realistas en entornos de análisis y prueba sin duplicar ni exponer datos de producción |
| Visibilidad operacional | Proporciona auditorías unificadas mostrando quién accedió a datos enmascarados, cuándo y bajo qué política |
| Mantenibilidad a largo plazo | Elimina lógica de enmascaramiento SQL frágil y ligada a esquemas, reduciendo esfuerzo continuo de mantenimiento |
Conclusión
MariaDB permite un enmascaramiento básico mediante técnicas basadas en SQL, pero estos enfoques dependen de la aplicación manual y no escalan con entornos crecientes. A medida que aumentan los patrones de acceso y los requisitos de cumplimiento, fallan en proveer protección consistente o visibilidad.
Plataformas centralizadas como DataSunrise convierten el enmascaramiento de datos en un control basado en políticas, auditable y consciente del contexto que opera independientemente de la lógica de aplicación y esquemas. Esto hace que el enmascaramiento sea confiable, aplicable y adecuado para entornos regulados o con datos compartidos.
Para organizaciones que consideran a MariaDB como infraestructura crítica para producción o cumplimiento, el enmascaramiento de datos debe ser un control de seguridad deliberado, no una solución improvisada.
