Herramientas y Técnicas de Enmascaramiento de Datos para Vertica
Las herramientas y técnicas de enmascaramiento de datos para Vertica juegan un papel central en la protección de información sensible en entornos analíticos modernos. Vertica es ampliamente utilizado para análisis de alto volumen, reportes, ciencia de datos y cargas de trabajo de aprendizaje automático. Estos casos de uso requieren acceso flexible y a menudo amplio a los datos, lo que incrementa la probabilidad de que valores confidenciales —como identificadores personales, atributos financieros o información de salud— aparezcan en los resultados de consultas.
A diferencia de las bases de datos transaccionales, los entornos Vertica priorizan el rendimiento y el rendimiento analítico. Como resultado, los datos frecuentemente se desnormalizan, se replican a través de proyecciones y son accedidos por múltiples herramientas simultáneamente. En este contexto, el enmascaramiento debe ser eficiente y consistente, asegurando que los valores sensibles estén protegidos sin interrumpir el análisis.
Este artículo explora técnicas prácticas de enmascaramiento de datos para Vertica y las herramientas que las organizaciones utilizan para implementarlas eficazmente, incluyendo enfoques centralizados alineados con DataSunrise Data Compliance y los requisitos modernos de privacidad de datos.
Por Qué el Enmascaramiento de Datos es Crítico en los Entornos Vertica
La arquitectura de Vertica introduce desafíos únicos para la protección de datos. El almacenamiento columnar, las capas de memoria ROS/WOS y la optimización basada en proyecciones permiten que Vertica procese grandes conjuntos de datos rápidamente. Sin embargo, estas mismas características dificultan la confianza en métodos tradicionales de protección.
Los desafíos comunes incluyen:
- Tablas analíticas amplias que mezclan métricas con atributos sensibles.
- Múltiples proyecciones que almacenan las mismas columnas en diferentes formatos.
- Clusters compartidos accedidos por herramientas BI, trabajos ETL, notebooks y pipelines de ML.
- Consultas SQL ad-hoc que evaden vistas de reportes curadas.
El control de acceso basado en roles nativo de Vertica limita quién puede consultar objetos, pero no controla qué valores de columnas aparecen en los resultados. Una vez que se ejecuta una consulta, Vertica devuelve todos los datos seleccionados en forma clara. Para abordar esta brecha, las organizaciones aplican técnicas de enmascaramiento en tiempo de consulta, a menudo combinadas con controles de acceso avanzados.
Para un contexto adicional sobre el modelo de ejecución de Vertica, consulte la documentación oficial de arquitectura de Vertica.
Técnicas Comunes de Enmascaramiento de Datos para Vertica
Varias técnicas de enmascaramiento se usan comúnmente en entornos Vertica. Cada enfoque ofrece diferentes compensaciones entre seguridad, flexibilidad y esfuerzo de mantenimiento.
- Enmascaramiento estático: Crea copias enmascaradas de tablas para uso no productivo. Aunque es útil para desarrollo o pruebas, el enmascaramiento estático introduce duplicación de datos y mantenimiento continuo, que a menudo se gestiona mediante herramientas de enmascaramiento estático de datos.
- Enmascaramiento basado en vistas: Utiliza vistas SQL para ocultar o transformar columnas sensibles. Este método es frágil porque los usuarios pueden evitar las vistas accediendo directamente a las tablas.
- Enmascaramiento en la capa de aplicación: Aplica lógica de enmascaramiento en herramientas BI o aplicaciones. Este enfoque carece de consistencia y no protege todos los caminos de acceso.
- Enmascaramiento dinámico de datos: Enmascara valores en tiempo de consulta, basado en políticas, sin modificar los datos almacenados.
Entre estas técnicas, el enmascaramiento dinámico de datos ofrece el mejor equilibrio para el análisis en Vertica. Protege valores sensibles en tiempo real mientras preserva la precisión analítica y el rendimiento, especialmente cuando se combina con motores de enmascaramiento dinámico de datos.
Herramientas de Enmascaramiento para Vertica
Un enmascaramiento efectivo en Vertica requiere herramientas que comprendan tanto la semántica SQL como la sensibilidad de las columnas. Muchas organizaciones implementan enmascaramiento usando DataSunrise, que proporciona una capa centralizada de enmascaramiento frente a Vertica y se integra estrechamente con el monitoreo de actividad de base de datos.
DataSunrise integra múltiples capacidades en una sola plataforma:
- Descubrimiento de Datos Sensibles para identificar PII, PHI y datos financieros.
- Enmascaramiento Dinámico de Datos para proteger valores en tiempo de consulta.
- Monitoreo de Actividad de Base de Datos para rastrear accesos y comportamientos.
- Registros de Auditoría para apoyar el cumplimiento regulatorio.
Esta combinación permite a las organizaciones aplicar el enmascaramiento de manera consistente en todas las vías de acceso a Vertica, a la vez que soporta flujos de trabajo de Compliance Manager.
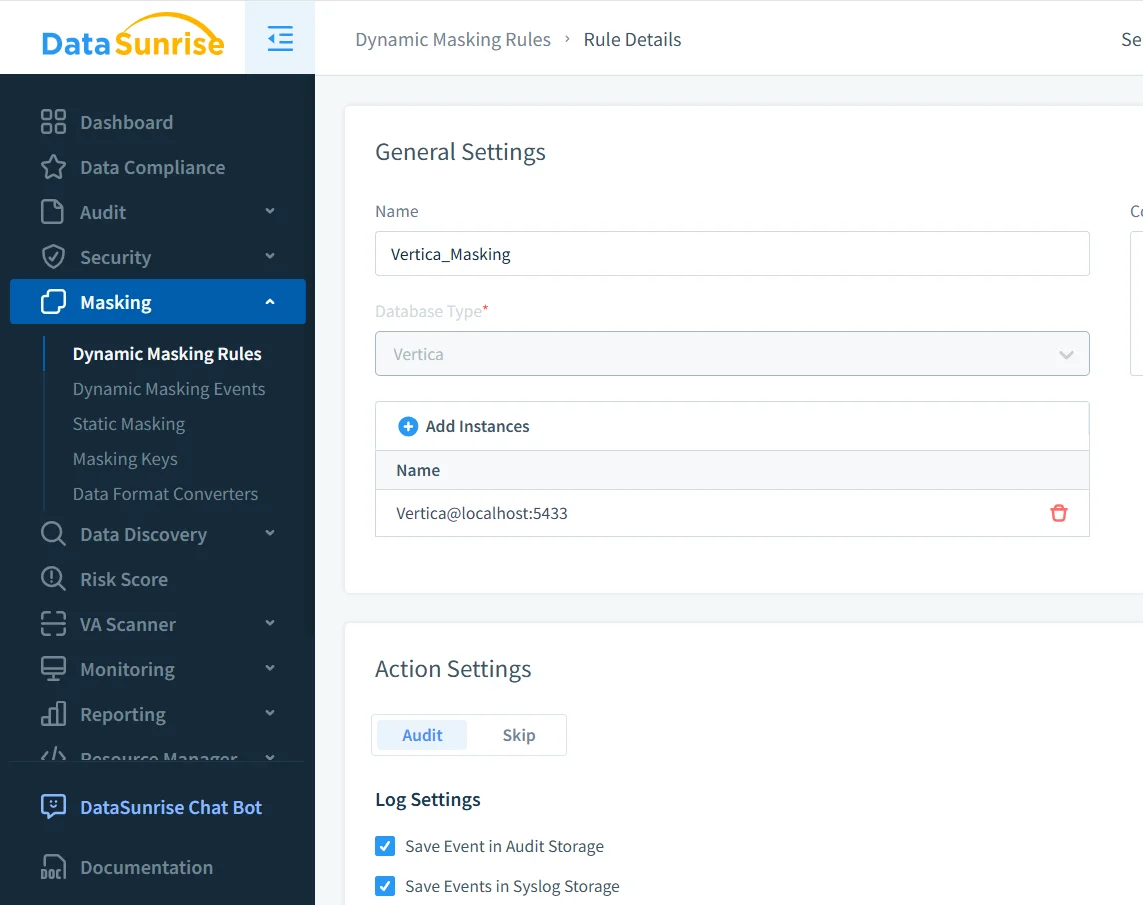
Configuración de una Regla de Enmascaramiento para Vertica
Las reglas de enmascaramiento dinámico definen cómo y cuándo se protege la información sensible. Una regla típica especifica la instancia de Vertica, los esquemas o tablas objetivos, y las columnas que requieren enmascaramiento.
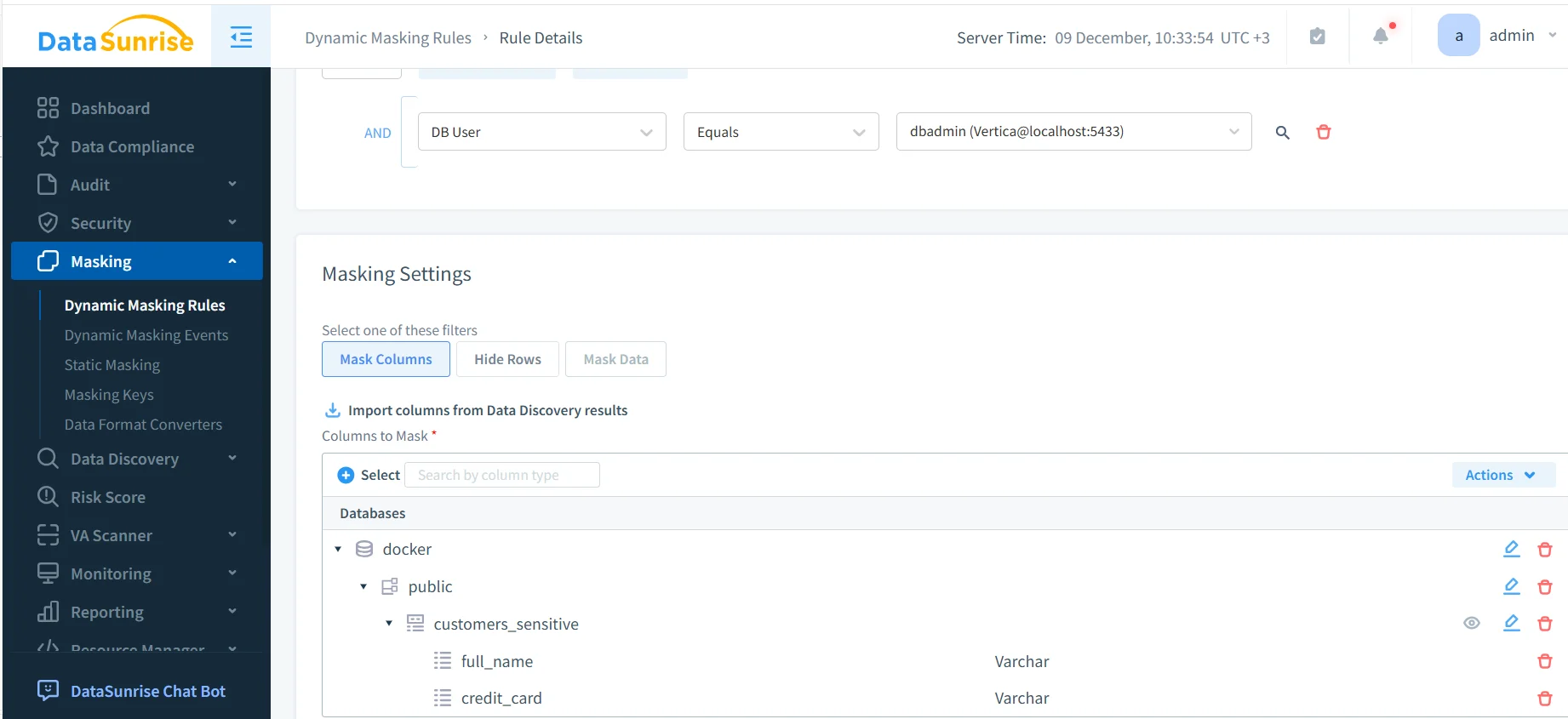
Configuración de regla de enmascaramiento dinámico para Vertica.
Una vez activada, la regla se aplica automáticamente a cada consulta que coincida. Los administradores también pueden definir condiciones basadas en usuarios de la base de datos, aplicaciones o entornos, y correlacionar eventos mediante las capacidades de rastreo de auditoría.
Resultados de Consultas Enmascaradas en Flujos de Trabajo Analíticos
Desde la perspectiva del usuario final, el enmascaramiento dinámico no cambia la forma en que se escriben las consultas. Los analistas continúan usando SQL estándar, y Vertica ejecuta las consultas normalmente. La diferencia aparece solo en los valores devueltos.
Resultados de consultas enmascaradas devueltos al cliente.
Con el enmascaramiento habilitado, los usuarios no privilegiados ven valores anonimizados o parcialmente ocultos, mientras que los agregados, uniones y filtros continúan funcionando correctamente. Esto hace que el enmascaramiento dinámico sea adecuado para paneles BI, análisis exploratorios e ingeniería de características ML gobernados por políticas de gobernanza de datos.
Este enfoque soporta los requisitos de privacidad y minimización de datos bajo regulaciones como GDPR, HIPAA y PCI DSS.
Comparación de Técnicas de Enmascaramiento para Vertica
| Técnica | Descripción | Impacto Operativo |
|---|---|---|
| Enmascaramiento estático | Crea copias enmascaradas permanentes de los datos | Alto mantenimiento, duplicación de datos |
| Enmascaramiento basado en vistas | Usa vistas SQL para ocultar columnas sensibles | Fácilmente evadido mediante consultas directas |
| Enmascaramiento en la capa de aplicación | Lógica de enmascaramiento dentro de BI o aplicaciones | Cobertura inconsistente |
| Enmascaramiento dinámico | Enmascara los valores en tiempo de consulta | Protección centralizada y escalable |
Mejores Prácticas para el Enmascaramiento de Datos en Vertica
- Comience con el descubrimiento para identificar columnas sensibles.
- Aplique enmascaramiento en la capa de consulta en lugar de copiar datos.
- Pruebe el enmascaramiento usando cargas de trabajo analíticas reales.
- Revise los registros de auditoría regularmente para detectar accesos inesperados.
- Alinee las políticas de enmascaramiento con estrategias más amplias de seguridad de datos.
Conclusión
Las herramientas y técnicas de enmascaramiento de datos para Vertica permiten a las organizaciones proteger información sensible mientras preservan la flexibilidad y el rendimiento de las cargas de trabajo analíticas. Al combinar el enmascaramiento dinámico con la aplicación centralizada de políticas y auditoría, los equipos evitan soluciones frágiles y logran una protección consistente en todas las vías de acceso.
Con las herramientas de enmascaramiento adecuadas, Vertica sigue siendo una plataforma de análisis potente mientras los datos sensibles permanecen protegidos a lo largo de BI, ETL y pipelines de aprendizaje automático.
