
¿Qué es un Archivo CSV?
Introducción: El Modesto Archivo CSV
Los archivos CSV se remontan a los primeros días de la informática y siguen siendo un formato confiable para el intercambio de datos. En los años 70 y principios de los 80, el lenguaje Fortran 77 de IBM introdujo el tipo de datos carácter, permitiendo el soporte para entrada y salida separadas por comas. Estos archivos simples pero poderosos han resistido la prueba del tiempo.
Anteriormente describimos las capacidades de DataSunrise para manejar datos semiestructurados en JSON. Si trabajas con conjuntos de datos estructurados o no estructurados, asegúrate de revisar nuestra cobertura sobre sus funciones de protección de datos.
Con DataSunrise, puedes enmascarar y detectar información sensible dentro de archivos con formato CSV almacenados localmente o en Amazon S3. A continuación se muestra un ejemplo de aplicación de enmascaramiento a un archivo CSV durante su procesamiento.
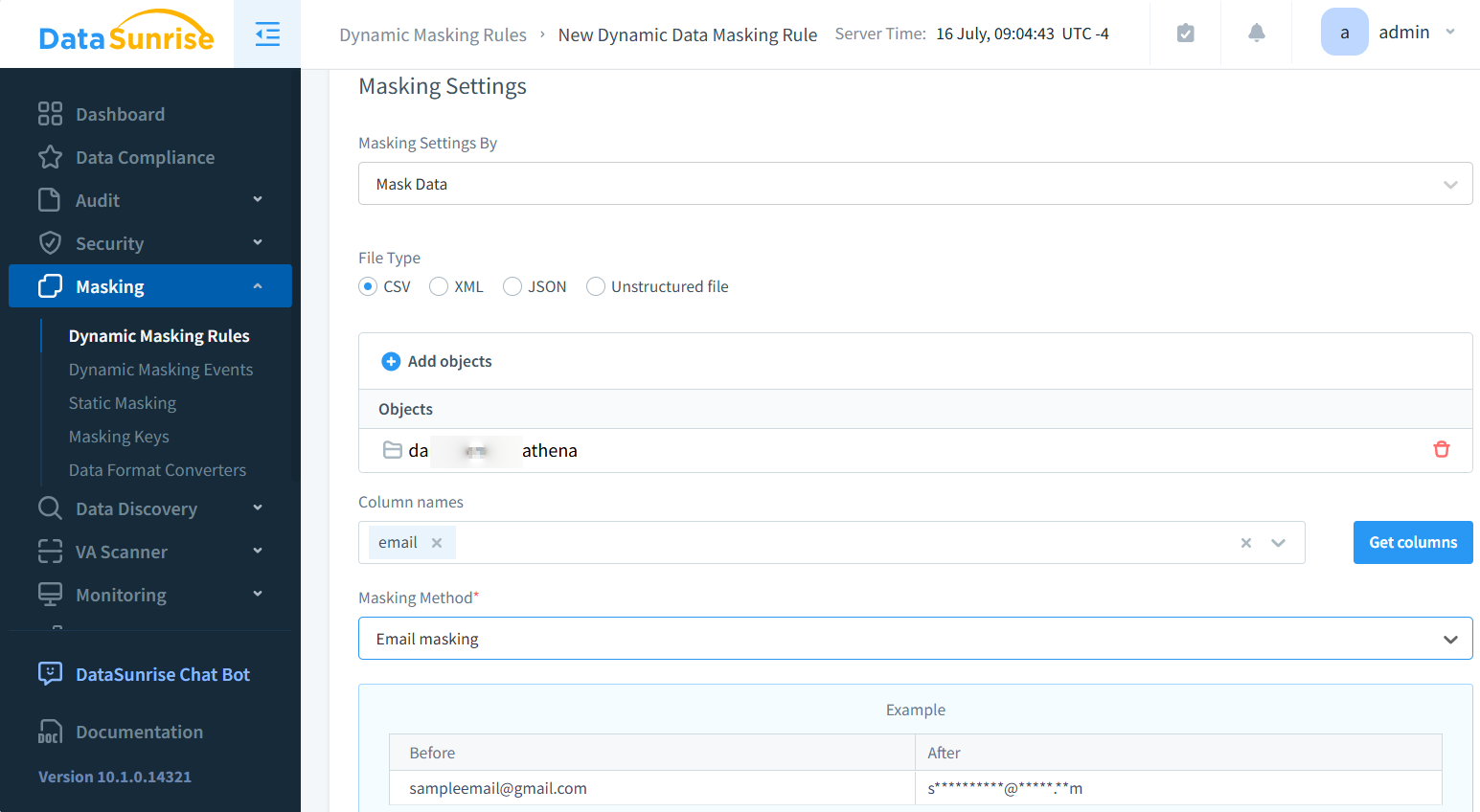
Después de una configuración sencilla, el archivo enmascarado puede ser accedido a través del proxy S3 de DataSunrise usando clientes como S3Browser. Asegúrate de configurar correctamente los ajustes del proxy para ver el contenido enmascarado, como se muestra a continuación:

En el amplio panorama de formatos de datos, el archivo CSV destaca por su claridad y portabilidad. Almacena datos tabulares en una estructura simple donde cada línea representa una fila y los valores están separados por comas. Esa simplicidad permite que el formato sea compatible en múltiples plataformas y sistemas.
¿Qué es un Archivo CSV?
Utilizado para representar filas y columnas en texto plano, un archivo CSV proporciona una forma ligera de almacenar e intercambiar datos estructurados. Cada línea contiene una fila y las comas dividen los campos dentro de ella. El resultado es un formato fácil de leer y de generar programáticamente.
Los archivos típicamente usan la extensión “.csv”; ejemplos incluyen “contacts.csv” o “report_data.csv”. Ábrelos en un editor de texto y verás una lista de valores separados por comas. Herramientas de hojas de cálculo como Excel o Google Sheets interpretan el contenido como tablas estructuradas.
Si bien las comas son delimitadores estándar, pueden aparecer puntos y comas, tabulaciones o barras verticales en algunas implementaciones regionales o personalizadas. Incluir una fila de encabezado es opcional pero recomendado, especialmente cuando el conjunto de datos contiene múltiples campos.
A diferencia de formatos más sofisticados, este no soporta fórmulas integradas, estilos ni datos anidados. Ese compromiso lo hace ideal para exportaciones limpias, pero no adecuado para informes complejos.
¿Por Qué Usar Archivos CSV?
Este formato sigue siendo popular debido a su simplicidad y versatilidad:
- Simplicidad: Fácil de leer, incluso para usuarios sin experiencia técnica.
- Compatibilidad: Soportado por prácticamente todas las herramientas de hojas de cálculo y bases de datos.
- Intercambio de datos: Útil para transferir datos entre sistemas con formatos diferentes.
- Eficiencia de tamaño: Más pequeño que los formatos binarios, lo que ayuda con el almacenamiento y el rendimiento.
Ejemplo de CSV
A continuación un ejemplo básico para ilustrar cómo aparecen los datos en un archivo CSV:
Nombre, Edad, Ciudad John Doe, 30, Nueva York Jane Smith, 25, Londres Bob Johnson, 35, París
Cada registro está en una línea separada, con comas que separan los campos individuales. Esta estructura es consistente en la mayoría de los archivos CSV.
Trabajando con Archivos CSV en Python
Python ofrece bibliotecas integradas que facilitan el trabajo con archivos CSV. El módulo csv se usa frecuentemente para leer y escribir estos archivos en scripts básicos.
import csv
# Leyendo un archivo
with open('data.csv', 'r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
# Escribiendo en un archivo
with open('output.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['Nombre', 'Edad', 'Ciudad'])
csv_writer.writerow(['Alice', '28', 'Berlín'])
Usando Pandas
Para flujos de trabajo más avanzados, la librería pandas es frecuentemente la preferida. Permite a los desarrolladores cargar archivos CSV, manipularlos con estructuras DataFrame ricas y exportar resultados limpios.
import pandas as pd
# Leyendo
df = pd.read_csv('data.csv')
print(df.head())
# Escribiendo
df.to_csv('output.csv', index=False)
Tareas como filtrar, ordenar y agregar datos son mucho más sencillas con pandas. La librería también facilita guardar conjuntos de datos modificados de vuelta en formato CSV para compartir o almacenar.
Las Ventajas y Desventajas de los Archivos Separados por Comas
Ventajas
- Legible por humanos: Los archivos pueden abrirse e interpretarse manualmente
- Ligero: Sobrecarga mínima comparado con formatos binarios
- Universalmente soportado: Funciona en prácticamente todas las herramientas relacionadas con datos
Desventajas
- Complejidad limitada: No soporta tipos de datos anidados o enriquecidos
- Esquema no impuesto: El orden y tipo de columnas están definidos de manera flexible
- Riesgos de integridad: No tiene validaciones ni manejo de errores incorporados
Archivos CSV en el Intercambio de Datos
Este formato de archivo se usa en muchos campos y flujos de trabajo:
- Inteligencia de negocios: Transferencia de informes entre herramientas como Tableau y almacenes basados en SQL
- Investigación científica: Publicación de conjuntos de datos para reutilización y validación
- Aplicaciones web: Permite a los usuarios exportar datos para respaldo o análisis
- IoT y registro de sensores: Formato simple para capturar lecturas
Archivos CSV en Entornos Empresariales
Muchos sistemas empresariales aún usan archivos CSV para importaciones, exportaciones y auditorías. Instituciones financieras generan resúmenes de transacciones en este formato. Sistemas de salud dependen de transferencias seguras de CSV para compartir datos de pacientes. Para migraciones, CSV a menudo actúa como puente entre sistemas heredados y modernos.
Archivos CSV en el Campo del Big Data
A pesar del auge de Parquet y Avro, los archivos CSV no han desaparecido del mundo del Big Data. Siguen cumpliendo funciones clave en ciertas canalizaciones.
- Ingesta: Los datos a menudo llegan como un CSV antes de su transformación
- Compatibilidad con legado: Muchos sistemas upstream generan texto plano
- Exportación de resultados: CSV facilita compartir o archivar datos
Sin embargo, las limitaciones en esquema, compresión y análisis hacen que no sea el más adecuado para análisis a gran escala. Ahí es donde los formatos binarios suelen destacar.
Cuándo Usar un Archivo CSV vs Formato Binario
| Caso de Uso | Mejor Formato | Por Qué |
|---|---|---|
| Intercambio de datos entre sistemas | CSV | Simple, legible por humanos, soportado en todas partes |
| Analítica a gran escala | Parquet / Avro | Soporte de esquemas y compresión de alto rendimiento |
| Exportaciones o registros diarios | CSV | Fácil de automatizar y revisar manualmente |
Conclusión: El Valor Duradero de los Archivos CSV
Incluso con el auge de formatos modernos de datos y sistemas de almacenamiento complejos, CSV sigue siendo uno de los componentes más versátiles y fiables del ecosistema de datos actual. Su simplicidad, compatibilidad universal y estructura legible por humanos lo convierten en un formato esencial para el intercambio de datos, análisis rápido, prototipado y archivado a largo plazo.
En entornos empresariales, herramientas como DataSunrise amplían aún más la practicidad de los archivos CSV al añadir capacidades críticas como enmascaramiento dinámico o estático de datos, registro detallado de auditorías, clasificación de datos y descubrimiento automatizado de campos sensibles. Estas funcionalidades ayudan a las organizaciones a gestionar con seguridad flujos de trabajo basados en CSV, reducir riesgos operativos y cumplir con obligaciones regulatorias en marcos como GDPR, HIPAA y PCI DSS. Si tus equipos trabajan con conjuntos de datos CSV sensibles, considera explorar las soluciones de seguridad de DataSunrise—visita la visión general de la plataforma o agenda una demo para aprender cómo optimizar la protección y gobernanza.
