
¿Qué es el particionamiento?
A medida que las bases de datos crecen en tamaño y complejidad, el rendimiento y la facilidad de mantenimiento a menudo se ven afectados. El particionamiento ofrece una solución al dividir objetos grandes de la base de datos —como tablas e índices— en segmentos más pequeños y manejables. Esta técnica se utiliza ampliamente para acelerar la ejecución de consultas, reducir los costos de almacenamiento y simplificar la gestión del ciclo de vida de los datos en sistemas empresariales y plataformas basadas en la nube.
Las principales ventajas incluyen un mejor control, rendimiento y disponibilidad. Este enfoque permite a los administradores optimizar y mantener diferentes partes de la base de datos de forma independiente, mejorando la eficiencia de las consultas y el tiempo de actividad del sistema, al mismo tiempo que posibilita estrategias de gestión más específicas.
- En algunos casos, este método mejora el rendimiento al acceder a tablas particionadas.
- También puede definir columnas principales en los índices, reduciendo el tamaño del índice e incrementando la eficiencia del acceso a la memoria. Cuando se utiliza una gran parte de una sección en el conjunto de resultados, escanear esa sección es mucho más rápido que escanear datos dispersos.
- La carga y eliminación masiva son posibles simplemente agregando o eliminando secciones, lo que mejora el rendimiento.
- La información de acceso infrecuente puede trasladarse a sistemas de almacenamiento de menor costo.
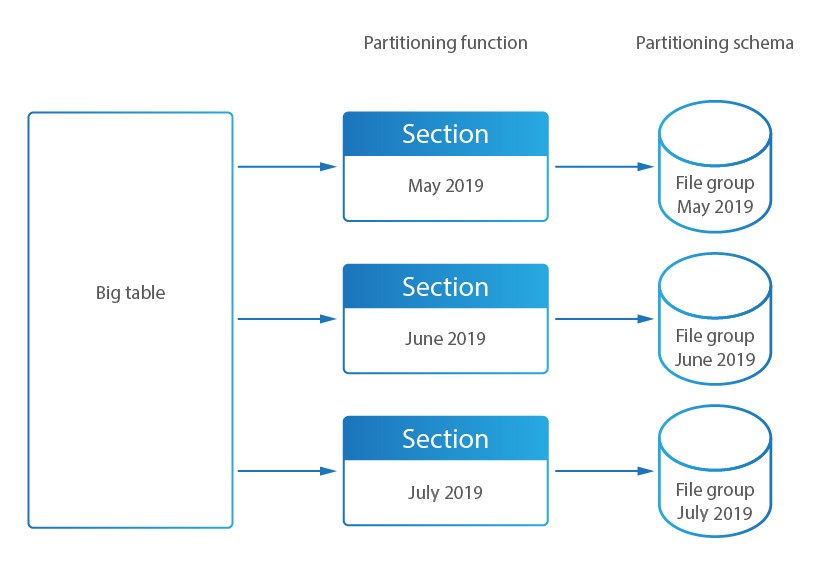
En DataSunrise, las grandes tablas de Almacenamiento de Auditoría se dividen en secciones más pequeñas para mejorar el acceso y el rendimiento. El Monitoreo de Actividad de la Base de Datos de DataSunrise almacena los resultados directamente en esta base de datos interna.
- Los administradores pueden gestionar los datos más fácilmente dividiéndolos en segmentos basados en el tiempo, los cuales pueden archivar o excluir de las consultas.
- La velocidad de lectura/escritura mejora significativamente al interactuar con las tablas de almacenamiento.
- Eliminar registros de auditoría obsoletos se vuelve más rápido y eficiente.
DataSunrise admite esta técnica para las siguientes plataformas de bases de datos de Almacenamiento de Auditoría:
- PostgreSQL
- MySQL
- MS SQL Server
Parámetros de particionamiento
Se pueden encontrar en Configuración del Sistema -> Parámetros adicionales.
- Longitud de las particiones (días) – Define la duración de cada sección (o minutos si AuditPartitionShort = 1). Se encuentra en Configuración del Sistema -> Almacenamiento de Auditoría. Cambiar este valor reinicia la estructura: las secciones existentes se eliminan y se sustituyen por nuevas.
- AuditPartitionCountCreatedInAdvance – Número de particiones preparadas para el futuro. Estos espacios vacíos permiten la escritura continua de datos sin interrupciones.
- AuditPartitionFirstEndDateTime – Especifica el límite superior de tiempo de la primera sección. Es útil para alinear las particiones con un ancla temporal clara (por ejemplo, lunes 00:00:00).
Particionamiento para el cumplimiento y retención
Muchas regulaciones de datos exigen la eliminación o el archivado oportuno de datos sensibles. El particionamiento facilita la gestión del ciclo de vida de los datos al aislar los registros antiguos en segmentos distintos. Esto permite una eliminación más rápida, un archivado más sencillo y una preparación mejorada para auditorías —especialmente en industrias sujetas a políticas de retención estrictas, como la salud, las finanzas y las telecomunicaciones.
Particionamiento en entornos modernos de datos
En entornos de big data, la segmentación de datos es crítica. Muchas plataformas en la nube ahora ofrecen opciones de particionamiento automático. AWS Redshift utiliza estilos de distribución para una organización óptima de los datos. Azure Synapse emplea métodos de distribución para mejorar el rendimiento de las consultas. La lógica basada en particiones también funciona bien con data lakes que manejan petabytes de información. Esto permite una consulta más rápida en aplicaciones de BI y soporta el acceso basado en el tiempo a datos históricos o archivados. Las estrategias adecuadas ayudan a reducir los costos de almacenamiento y a alinearse con las políticas de retención.
Estrategias efectivas de distribución de datos
Crear estrategias efectivas de distribución de la base de datos requiere una planificación cuidadosa basada en patrones de acceso y requisitos empresariales. La organización por rangos funciona mejor para valores secuenciales, como las fechas, permitiendo a los equipos acceder rápidamente a datos recientes mientras archivan la información antigua.
La distribución por hash distribuye los datos de manera uniforme a lo largo de segmentos de almacenamiento, siendo ideal para el balanceo de carga en entornos de alta concurrencia. Los enfoques basados en listas organizan los registros por valores categóricos específicos, lo que los hace perfectos para la segmentación geográfica o departamental.
Muchas organizaciones implementan métodos híbridos, combinando múltiples técnicas de distribución para maximizar los beneficios de rendimiento mientras minimizan la sobrecarga de mantenimiento. El análisis de poda regular garantiza que las consultas se dirijan de manera consistente únicamente a los segmentos de datos necesarios, proporcionando un rendimiento óptimo a medida que crecen los volúmenes de datos.
Gestión de particiones en DataSunrise
DataSunrise admite la segmentación automática de datos: crea las tablas requeridas (para PostgreSQL), mantiene funciones, esquemas, grupos de archivos e índices actualizados (para MS SQL) y ajusta las claves para que coincidan con los modelos nativos de particionamiento (para MySQL). DataSunrise gestiona todo el ciclo de vida de las secciones, desde su creación hasta su limpieza.
El sistema ejecuta SELECTs a través de la tabla principal, mientras dirige los INSERT/UPDATE a secciones específicas (excepto para MS SQL Server), mejorando el rendimiento de escritura.
Nombres de particiones y tablas
PostgreSQL crea tablas hijas como particiones utilizando el formato <nombre_tabla>_p<datetime>, donde <datetime> es el límite superior en formato AAAAMMDDhhmm.
MySQL utiliza mecanismos nativos para el particionamiento. Genera nombres de particiones utilizando el formato p<datetime>, siguiendo la misma convención de marca de tiempo.
MS SQL Server aplica el particionamiento utilizando un enfoque basado en esquemas en lugar de tablas hijas.
