Cómo Aplicar Enmascaramiento Estático en Apache Cloudberry
La implementación de enmascaramiento estático para Apache Cloudberry se ha vuelto esencial para proteger la información sensible en entornos no productivos. Según investigaciones recientes de IBM, el costo promedio de una violación de datos alcanzó los 4.88 millones de dólares en 2024, haciendo que las prácticas robustas de seguridad de datos sean más críticas que nunca.
Apache Cloudberry, una base de datos MPP de código abierto construida sobre PostgreSQL, requiere estrategias integrales de protección de datos para asegurar la información sensible durante los flujos de trabajo de desarrollo y pruebas. Las organizaciones pueden aprovechar la arquitectura de Cloudberry y las funcionalidades de carga de datos mientras implementan técnicas adecuadas de enmascaramiento.
Esta guía ofrece pasos prácticos para implementar enmascaramiento estático utilizando enfoques nativos y explora cómo DataSunrise automatiza y mejora la protección de datos en entornos Apache Cloudberry.
Comprendiendo el Enmascaramiento Estático en Apache Cloudberry
El enmascaramiento estático de datos crea una copia saneada de la base de datos reemplazando permanentemente los datos sensibles con valores realistas pero ficticios. A diferencia del enmascaramiento dinámico, que oculta datos en tiempo real, el enmascaramiento estático transforma físicamente los datos en una instancia de base de datos separada.
Este enfoque resulta particularmente valioso para el desarrollo y pruebas con conjuntos de datos realistas, entornos analíticos que deben evitar exponer información personalmente identificable (PII), el intercambio de datos con terceros para pruebas de integración, y sistemas de capacitación que requieren datos representativos sin comprometer la privacidad. Las organizaciones que implementan enmascaramiento estático deben considerar también estrategias de gestión de datos de prueba para maximizar la efectividad.
Enmascaramiento Estático Nativo en Apache Cloudberry
Apache Cloudberry hereda las capacidades de manipulación de datos de PostgreSQL. Aunque carece de enmascaramiento estático incorporado, puede implementar un enmascaramiento efectivo usando funciones nativas de PostgreSQL. Sin embargo, las organizaciones deben estar conscientes de posibles amenazas de seguridad al trabajar con datos sensibles en entornos no productivos.
Requisitos Previos
Antes de implementar el enmascaramiento estático, asegúrese de contar con una instancia de Apache Cloudberry en funcionamiento con privilegios administrativos, una base de datos objetivo separada para la copia enmascarada y conocimientos básicos de SQL.
Paso 1: Implementar Funciones de Enmascaramiento
Crear funciones personalizadas de enmascaramiento para tipos de datos comunes:
-- Enmascarar direcciones de email
CREATE OR REPLACE FUNCTION mask_email(email TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN CASE WHEN email IS NULL THEN NULL
ELSE 'masked_' || md5(email)::text || '@example.com' END;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
-- Enmascarar tarjetas de crédito (mantener primeros 4 y últimos 4 dígitos)
CREATE OR REPLACE FUNCTION mask_credit_card(card_number TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN CASE WHEN card_number IS NULL THEN NULL
ELSE substring(card_number from 1 for 4) ||
repeat('*', length(card_number) - 8) ||
substring(card_number from length(card_number) - 3) END;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
Paso 2: Copiar y Enmascarar Datos
-- Copiar y enmascarar tabla de clientes
INSERT INTO cloudberry_masked.customer_data (
customer_id, email, credit_card
)
SELECT
customer_id,
mask_email(email),
mask_credit_card(credit_card)
FROM cloudberry_production.customer_data;
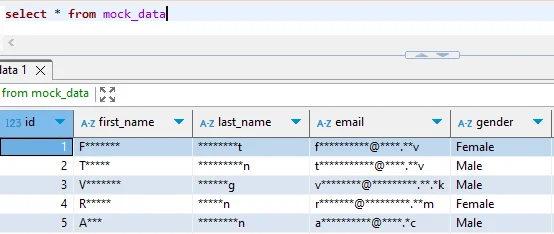
Paso 3: Verificar Datos Enmascarados
-- Comparar datos originales y enmascarados
SELECT customer_id, email FROM cloudberry_production.customer_data LIMIT 3;
SELECT customer_id, email FROM cloudberry_masked.customer_data LIMIT 3;
Limitaciones del Enfoque Nativo
El enfoque nativo presenta varios desafíos para organizaciones con requisitos avanzados. El proceso manual requiere scripts SQL personalizados que consumen mucho tiempo para cada tabla, mientras que la falta de descubrimiento automatizado significa que los datos sensibles no pueden ser identificados automáticamente a través de los esquemas. Las funciones básicas de enmascaramiento pueden no cumplir con las necesidades de regulaciones de cumplimiento, y sin un registro de auditoría completo, las organizaciones carecen de seguimiento de las operaciones de enmascaramiento. Además, el rendimiento puede degradarse significativamente con grandes conjuntos de datos distribuidos a través de la arquitectura MPP de Cloudberry.
Enmascaramiento Estático Mejorado con DataSunrise
DataSunrise ofrece un enmascaramiento de datos integral que mejora significativamente las capacidades nativas de Apache Cloudberry. La plataforma implementa las mejores prácticas de seguridad de bases de datos mientras ofrece características avanzadas para la protección de datos sensibles.
Ventajas Clave
- Descubrimiento Automático de Datos: Identifica datos sensibles según los marcos regulatorios GDPR, HIPAA, y PCI DSS usando técnicas avanzadas de descubrimiento de datos.
- Múltiples Algoritmos de Enmascaramiento: Ofrece diversos tipos de enmascaramiento incluyendo aleatorización, sustitución y cifrado que preserva el formato.
- Enmascaramiento Sin Código In-Place: Configure y ejecute el enmascaramiento sin scripts SQL complejos.
- Integridad Referencial: Mantiene automáticamente las relaciones de claves externas y las relaciones entre tablas en tablas enmascaradas.
- Registro de Auditoría Completo: Registra todas las operaciones de enmascaramiento para requisitos de cumplimiento.
- Compatibilidad Multiplataforma: Aplica políticas uniformes en más de 40 plataformas de bases de datos.
Pasos de Implementación con DataSunrise
1. Conectar la Instancia de Apache Cloudberry
Conecte su base de datos a través de la interfaz de DataSunrise proporcionando host, puerto y credenciales de autenticación.
2. Descubrir Datos Sensibles
Navegue al módulo de Descubrimiento de Datos, seleccione su instancia de Apache Cloudberry, elija plantillas regulatorias (GDPR, HIPAA, PCI DSS) y ejecute un escaneo de descubrimiento para identificar automáticamente los datos sensibles.
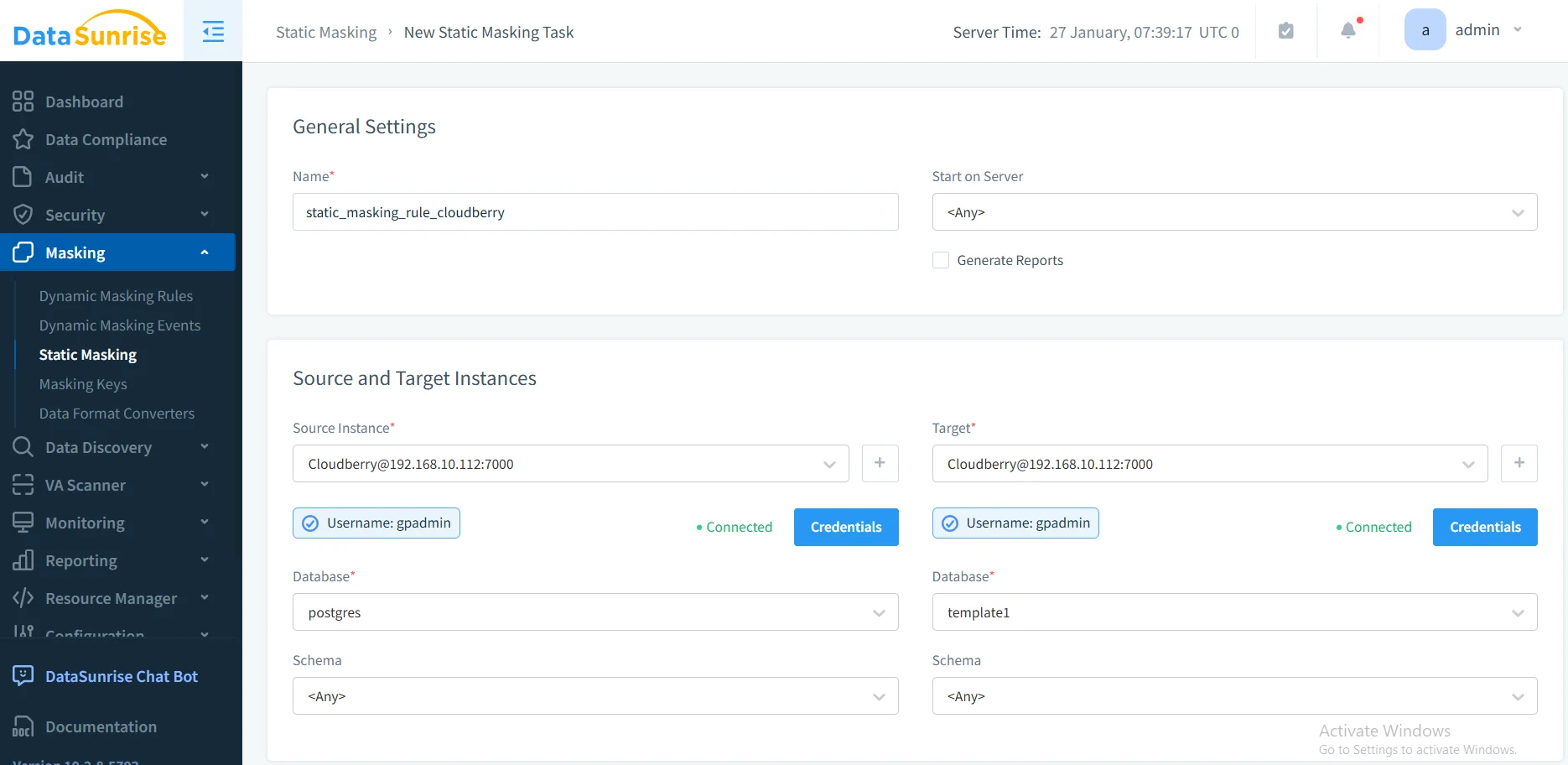
3. Configurar Reglas de Enmascaramiento
Seleccione su base de datos o esquema objetivo, elija algoritmos de enmascaramiento adecuados para cada tipo de dato, configure la preservación de la integridad referencial y ajuste las opciones de consistencia del enmascaramiento.
4. Ejecutar Enmascaramiento In Situ
Seleccione bases de datos origen y destino, revise el plan de enmascaramiento, ejecute la operación y monitoree el progreso en tiempo real a través del panel de DataSunrise.
5. Verificar Resultados
DataSunrise proporciona informes de validación que muestran registros enmascarados, algoritmos aplicados y métricas de cobertura de cumplimiento.
Buenas Prácticas para el Enmascaramiento Estático en Apache Cloudberry
| Área de Práctica | Recomendación |
|---|---|
| Clasificación de Datos | Identifique todos los datos sensibles en su clúster Cloudberry; priorice según requisitos regulatorios e impacto empresarial; implemente controles de acceso adecuados y documente los flujos de datos. |
| Selección de Algoritmos | Utilice enmascaramiento que preserve el formato para compatibilidad con aplicaciones; elija enmascaramiento determinista para consistencia o aleatorio para seguridad; asegúrese de que los algoritmos cumplan regulaciones y considere el cifrado de base de datos para protección adicional. |
| Optimización del Rendimiento | Procese tablas grandes por lotes; aproveche la arquitectura MPP de Cloudberry para ejecución en paralelo; programe el enmascaramiento en horas de baja carga para minimizar impacto. |
| Seguridad y Cumplimiento | Mantenga registros detallados de actividades de enmascaramiento; restrinja acceso usando controles de acceso basados en roles (RBAC); establezca programas regulares de actualización; valide el cumplimiento mediante informes automatizados. |
Conclusión
Aunque la base de PostgreSQL sobre la que se apoya Apache Cloudberry provee capacidades básicas de transformación, las implementaciones nativas requieren un esfuerzo manual significativo y carecen de características empresariales. DataSunrise ofrece un enmascaramiento integral mediante descubrimiento automatizado, algoritmos inteligentes y gestión centralizada de políticas.
Con múltiples opciones de despliegue que soportan entornos en la nube, locales e híbridos, DataSunrise brinda la flexibilidad necesaria para arquitecturas de datos modernas.
