
Cómo auditar Apache Hive

Introducción
Apache Hive es ampliamente utilizado por muchas organizaciones para procesar y analizar grandes cantidades de datos estructurados almacenados en Hadoop. A medida que aumenta el volumen de datos sensibles que se procesan a través de Hive, implementar mecanismos de auditoría efectivos se vuelve esencial no solo para la seguridad sino también para el cumplimiento normativo.
Esta guía lo acompañará a través del proceso de configuración y activación de las capacidades de auditoría para Apache Hive, desde las características nativas de auditoría hasta soluciones mejoradas con DataSunrise, asegurando que disponga de la visibilidad necesaria para monitorear el acceso a los datos, detectar actividades no autorizadas y mantener el cumplimiento.
Cómo auditar Apache Hive utilizando las capacidades nativas
Apache Hive ofrece varios mecanismos integrados para la auditoría que se pueden configurar para rastrear las actividades de los usuarios y las operaciones realizadas sobre los datos. Exploremos cómo configurar estas capacidades nativas de auditoría:
Paso 1: Habilitar la Autorización basada en Estándares SQL
La Autorización basada en Estándares SQL en Hive proporciona un modelo de control de acceso basado en roles que incluye capacidades básicas de auditoría. Este modelo registra las operaciones y cambios de privilegios realizados por los usuarios.
Para habilitar la Autorización basada en Estándares SQL, modifique su archivo de configuración hive-site.xml:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
Después de realizar estos cambios, reinicie los servicios de Hive para aplicar la configuración.
Paso 2: Configurar el Marco de Registro
Apache Hive utiliza Log4j para registrar eventos, el cual puede configurarse para capturar la información de auditoría. Para mejorar el registro de auditorías, modifique el archivo hive-log4j2.properties:
# Registro de Auditoría de Hive
appender.AUDIT.type = RollingFile
appender.AUDIT.name = AUDIT
appender.AUDIT.fileName = ${sys:hive.log.dir}/${sys:hive.log.file}.audit
appender.AUDIT.filePattern = ${sys:hive.log.dir}/${sys:hive.log.file}.audit.%d{yyyy-MM-dd}
appender.AUDIT.layout.type = PatternLayout
appender.AUDIT.layout.pattern = %d{ISO8601} %p %c: %m%n
appender.AUDIT.policies.type = Policies
appender.AUDIT.policies.time.type = TimeBasedTriggeringPolicy
appender.AUDIT.policies.time.interval = 1
appender.AUDIT.policies.time.modulate = true
appender.AUDIT.strategy.type = DefaultRolloverStrategy
appender.AUDIT.strategy.max = 30
# Logger de Auditoría
logger.audit.name = org.apache.hadoop.hive.ql.audit
logger.audit.level = INFO
logger.audit.additivity = false
logger.audit.appenderRef.audit.ref = AUDIT
Estos ajustes crean un archivo de registro de auditoría dedicado que captura todos los eventos de auditoría en un formato estructurado.
Paso 3: Habilitar los Registros de Auditoría de HDFS
Dado que las operaciones de Hive involucran en última instancia operaciones en HDFS, habilitar los registros de auditoría de HDFS proporciona una capa adicional de auditoría. Modifique el archivo hdfs-site.xml:
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.audit.log.async</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.audit.log.debug.cmdlist</name>
<value>open,create,delete,append,rename</value>
</property>
Reinicie los servicios de HDFS para aplicar estos cambios.
Paso 4: Probar el Registro de Auditoría
Para verificar que la auditoría está funcionando correctamente, realice varias operaciones en Hive y revise los registros de auditoría:
-- Crear una base de datos de prueba
CREATE DATABASE audit_test;
-- Crear una tabla
USE audit_test;
CREATE TABLE employee (
id INT,
name STRING,
salary FLOAT
);
-- Insertar datos
INSERT INTO employee VALUES (1, 'John Doe', 75000.00);
INSERT INTO employee VALUES (2, 'Jane Smith', 85000.00);
-- Consultar datos
SELECT * FROM employee WHERE salary > 80000;
-- Actualizar datos
UPDATE employee SET salary = 90000.00 WHERE id = 1;
-- Eliminar tabla
DROP TABLE employee;
Después de ejecutar estas operaciones, revise los registros de auditoría para asegurarse de que se estén registrando todas las actividades:
cat ${HIVE_LOG_DIR}/hive.log.audit

Paso 5: Integrar con Apache Ranger (Opcional)
Para contar con capacidades de auditoría más completas, integre Apache Hive con Apache Ranger. Ranger proporciona administración de seguridad centralizada y registros de auditoría detallados para los componentes de Hadoop.
Instale Apache Ranger utilizando la guía de instalación oficial.
Configure el complemento Ranger para Hive modificando el archivo
hive-site.xml:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value>
</property>
- Configure los ajustes de auditoría de Ranger en
ranger-hive-audit.xml:
<property>
<name>xasecure.audit.is.enabled</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.driver</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.url</name>
<value>jdbc:postgresql://ranger-db:5432/ranger</value>
</property>
Limitaciones de la Auditoría Nativa
Si bien estos mecanismos nativos de auditoría proporcionan una funcionalidad básica, presentan varias limitaciones:
- Datos de auditoría fragmentados: La información de auditoría se dispersa en varios archivos de registro y sistemas.
- Configuración compleja: Configurar una auditoría integral requiere la configuración de múltiples componentes.
- Herramientas de monitoreo limitadas: Los registros de auditoría nativos carecen de interfaces fáciles de usar para su análisis.
- Informes de cumplimiento manuales: Generar informes de cumplimiento requiere scripts personalizados o extracción manual.
- Intensivo en recursos: Una auditoría extensa puede afectar el rendimiento en entornos de alto volumen.
Cómo auditar Apache Hive de manera eficiente con DataSunrise
Para las organizaciones que requieren soluciones de auditoría más completas, DataSunrise proporciona capacidades avanzadas que abordan las limitaciones de la auditoría nativa de Hive. Exploremos cómo configurar DataSunrise para auditar Apache Hive:
Paso 1: Desplegar DataSunrise
Comience desplegando DataSunrise en su entorno. DataSunrise ofrece opciones de despliegue flexibles que incluyen configuraciones locales, en la nube e híbridas.
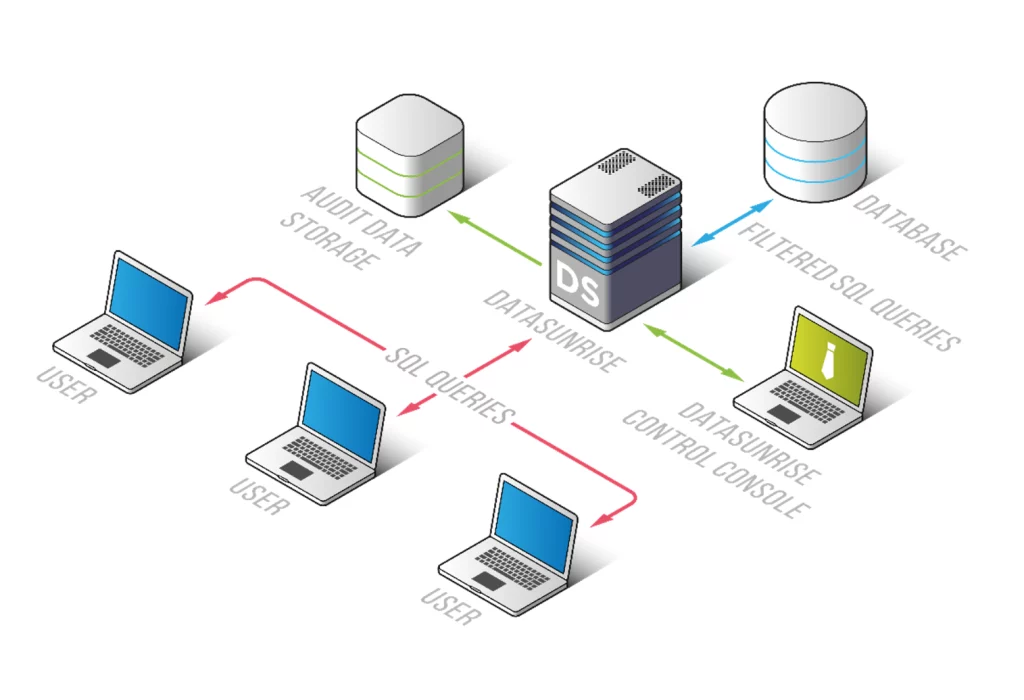
Paso 2: Conectarse a Apache Hive
Una vez que DataSunrise esté desplegado, conéctelo a su entorno Apache Hive:
- Navegue hasta la consola de administración de DataSunrise.
- Diríjase a “Bases de datos” y seleccione “Agregar Base de Datos”.
- Seleccione “Apache Hive” como el tipo de base de datos.
- Ingrese los detalles de conexión para su instancia de Hive, incluyendo host, puerto y credenciales de autenticación.
- Pruebe la conexión para asegurarse de que esté configurada correctamente.

Paso 3: Configurar las Reglas de Auditoría
Genere reglas de auditoría para definir qué actividades deben ser monitoreadas:
- Vaya a “Reglas” y seleccione “Agregar Regla”.
- Elija “Auditoría” como el tipo de regla.
- Configure los parámetros de la regla, incluyendo:
- Nombre y descripción de la regla
- Objetos de destino (bases de datos, tablas, vistas)
- Usuarios y roles a monitorear
- Tipos de operaciones a auditar (SELECT, INSERT, UPDATE, DELETE, etc.)
- Condiciones basadas en el tiempo (si es necesario)
- Guarde y active la regla.

Paso 4: Probar y Validar la Auditoría
Realice varias operaciones en Hive para validar que DataSunrise esté auditando correctamente las actividades:
- Ejecute las mismas consultas de prueba utilizadas anteriormente para validar la auditoría nativa.
- Navegue a la sección “Registro de Auditoría” en DataSunrise para ver los eventos de auditoría capturados.
- Verifique que todas las operaciones se registren correctamente con información detallada que incluya:
- Identidad del usuario
- Marca de tiempo
- Consulta SQL
- Tipo de operación
- Objetos afectados
- Dirección IP de origen

Conclusión
Una auditoría efectiva de Apache Hive es esencial para mantener la seguridad, garantizar el cumplimiento y obtener visibilidad sobre los patrones de acceso a los datos. Mientras que las capacidades nativas de auditoría de Hive proporcionan una funcionalidad básica, las organizaciones con requerimientos avanzados se benefician de soluciones integrales como DataSunrise.
DataSunrise mejora la auditoría de Apache Hive con gestión centralizada, trazas de auditoría detalladas, alertas en tiempo real e informes automatizados de cumplimiento. Al implementar una solución robusta de auditoría, las organizaciones pueden proteger sus datos sensibles, mantener el cumplimiento normativo y responder rápidamente a incidentes de seguridad.
¿Listo para mejorar las capacidades de auditoría de su Apache Hive? Programe una demostración y vea cómo DataSunrise puede ayudarlo a implementar una auditoría integral en su entorno Hive.
