
Enmascaramiento Dinámico de Datos para Amazon Redshift

Introducción
Las organizaciones enfrentan una creciente presión para proteger los datos personales mientras mantienen el cumplimiento normativo. Presentamos el enmascaramiento dinámico de datos para Amazon Redshift – una solución poderosa que ayuda a las empresas a asegurar sus datos sin comprometer la funcionalidad.
Adentrémonos en el mundo del enmascaramiento dinámico de datos y exploremos cómo puede revolucionar tu estrategia de seguridad de datos.
Según el Tablero de la Base Nacional de Vulnerabilidades (NVD), a partir de agosto de 2024, se han reportado 24,457 nuevos registros de Vulnerabilidades y Exposiciones Comunes (CVE) este año, y apenas estamos a mitad de camino.
Esta asombrosa estadística destaca la necesidad crítica de contar con medidas robustas de protección de datos. El enmascaramiento dinámico de datos ofrece un enfoque de vanguardia para salvaguardar la información sensible en las bases de datos de Amazon Redshift.
Comprendiendo las Capacidades de AWS Redshift para el Enmascaramiento de Datos
Amazon Redshift ofrece varias funciones integradas que pueden ser utilizadas para un enmascaramiento de datos básico. Si bien estas funciones no son tan completas como las soluciones de enmascaramiento especializadas, ofrecen un punto de partida para proteger la información sensible.
Datos de prueba
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email) values (6, 'Bartlet', 'Wank', '[email protected]'); insert into MOCK_DATA (id, first_name, last_name, email) values (7, 'Leupold', 'Gullen', '[email protected]'); insert into MOCK_DATA (id, first_name, last_name, email) values (8, 'Chanda', 'Matiebe', '[email protected]'); …
Uso de REGEXP_REPLACE
Una de las formas más sencillas de enmascarar datos en Redshift es utilizando la función REGEXP_REPLACE. Esta función te permite reemplazar partes de una cadena en función de un patrón de expresión regular.
A continuación, se muestra un ejemplo de cómo puedes usar restricciones y REGEXP_REPLACE para enmascarar un número de teléfono:
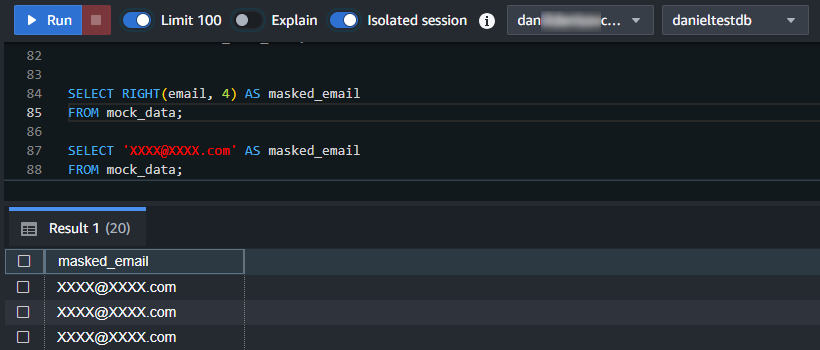
SELECT RIGHT(email, 4) AS masked_email FROM mock_data;
SELECT REGEXP_REPLACE(email, '.', '*') AS masked_email FROM mock_data;
Esta consulta reemplaza los primeros seis dígitos de un número de teléfono por caracteres ‘X’, dejando visibles solo los últimos cuatro dígitos.
O incluso más sencillo:
SELECT '[email protected]' AS masked_email FROM mock_data;
Vistas Enmascaradas
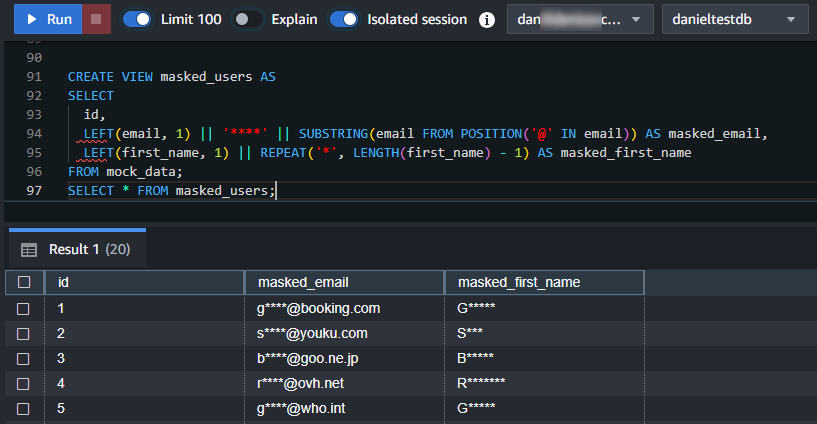
CREATE VIEW masked_users AS
SELECT
id,
LEFT(email, 1) || '****' || SUBSTRING(email FROM POSITION('@' IN email)) AS masked_email,
LEFT(first_name, 1) || REPEAT('*', LENGTH(first_name) - 1) AS masked_first_name
FROM mock_data;
SELECT * FROM masked_users;
Aprovechando las Funciones Integradas de Python
Redshift también soporta funciones definidas por el usuario (UDFs) escritas en Python. Estas pueden ser herramientas poderosas para implementar una lógica de enmascaramiento más compleja.
A continuación, se muestra un ejemplo sencillo de UDFs en Python que enmascaran direcciones de correo electrónico y nombres:
-- Enmascarar Correo Electrónico --
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;
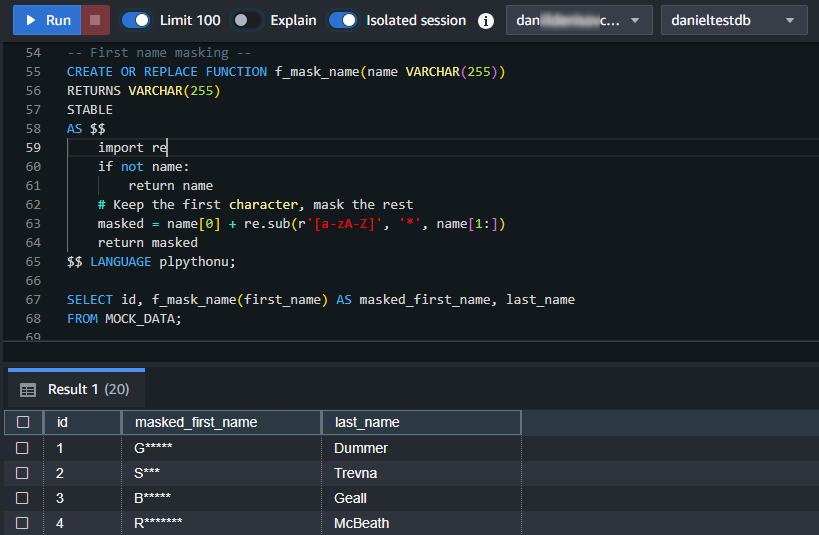
-- Enmascarar nombres -- CREATE OR REPLACE FUNCTION f_mask_name(name VARCHAR(255)) RETURNS VARCHAR(255) STABLE AS $$ import re if not name: return name # Mantener el primer carácter, enmascarar el resto masked = name[0] + re.sub(r'[a-zA-Z]', '*', name[1:]) return masked $$ LANGUAGE plpythonu;
SELECT id, f_mask_name(first_name) AS masked_first_name, last_name FROM MOCK_DATA;
Creando una Instancia de DataSunrise para el Enmascaramiento Dinámico de Datos
Si bien las capacidades integradas de Redshift ofrecen un enmascaramiento básico, carecen de la flexibilidad y facilidad de uso que proporcionan soluciones especializadas como DataSunrise. Exploremos cómo configurar el enmascaramiento dinámico de datos utilizando DataSunrise.
Configurando el Enmascaramiento Dinámico de Datos
Para configurar el enmascaramiento dinámico de datos:
- En el panel, navega a la sección “Enmascaramiento”.
- Selecciona “Reglas de Enmascaramiento Dinámico” desde el menú.
- Haz clic en “Agregar Nueva Regla” para crear una regla de enmascaramiento.
- Elige tu instancia de base de datos de Amazon Redshift de la lista de bases de datos conectadas.
- Selecciona la tabla y la columna que deseas enmascarar.
- Elige un método de enmascaramiento (más detalles sobre estos en la siguiente sección).
- Guarda tu regla y aplica los cambios.
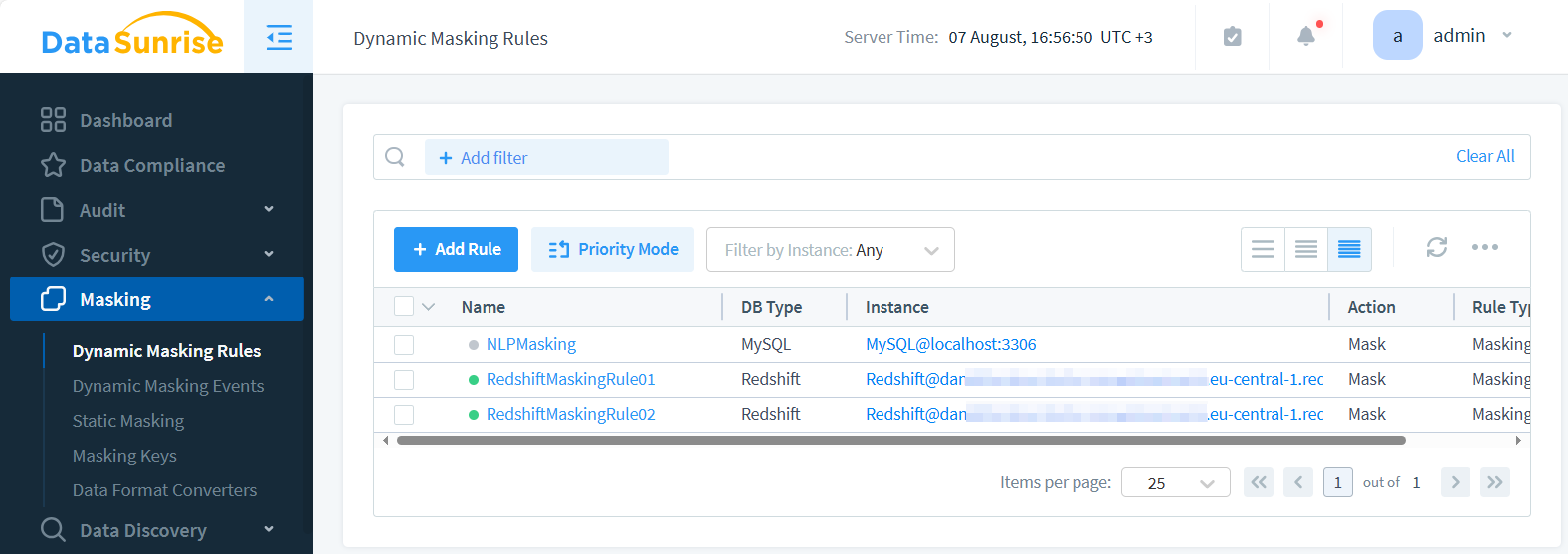
La imagen muestra dos reglas de enmascaramiento dinámico de datos. La primera regla, etiquetada como ‘RedshiftMaskingRule01’, está configurada para enmascarar direcciones de correo electrónico. La segunda regla, ‘RedshiftMaskingRule02’, está configurada para enmascarar nombres.
Después de configurar las reglas, puedes ejecutar una consulta de prueba para ver los datos enmascarados dinámicamente en acción. El acceso a los datos enmascarados en DBeaver se ilustra a continuación.
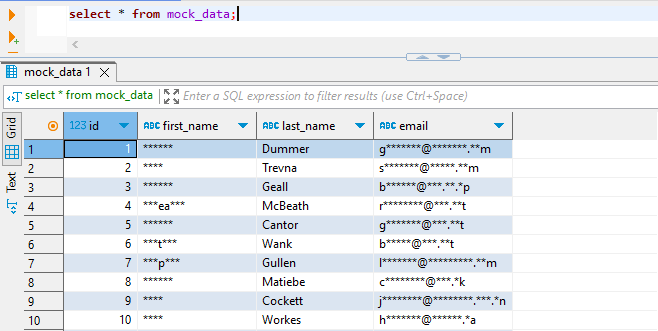
Crear reglas de enmascaramiento dinámico con DataSunrise es notablemente simple, requiriendo solo unos pocos clics. Este proceso simplificado contrasta fuertemente con los métodos nativos más complejos. Lo mejor de todo es que esta facilidad de uso se aplica a decenas de bases de datos y sistemas de almacenamiento soportados, ofreciendo una versatilidad y eficiencia inigualables en la protección de datos.
Explorando los Métodos de Enmascaramiento
DataSunrise ofrece varios métodos de enmascaramiento para adaptarse a diferentes tipos de datos y requerimientos de seguridad. Examinemos tres enfoques comunes:
Cifrado con Formato Preservado (FPE)
FPE es una técnica avanzada de enmascaramiento que cifra los datos manteniendo su formato original. Esto es particularmente útil para campos como números de tarjetas de crédito o números de seguro social, donde los datos enmascarados deben conservar la misma estructura que los originales.
Ejemplo: Original: 1234-5678-9012-3456 Enmascarado: 8736-2940-5281-7493
Valor de Cadena Fijo
Este método reemplaza todo el campo por una cadena predefinida. Es simple pero efectivo para casos en los que la estructura real de los datos no es importante.
Ejemplo: Original: John Doe Enmascarado: [REDACTED]
Valor Nulo
A veces, la mejor manera de proteger datos sensibles es ocultarlos por completo. El método de valor nulo reemplaza los datos originales por un valor nulo, eliminándolos efectivamente de los resultados de consultas para los usuarios no autorizados.
Ejemplo: Original: [email protected] Enmascarado: NULL
DataSunrise ofrece una diversa gama de métodos de enmascaramiento, proporcionándote numerosas opciones para adaptar tu estrategia de protección de datos:
Beneficios del Enmascaramiento Dinámico de Datos
Implementar el enmascaramiento dinámico de datos para Amazon Redshift ofrece varias ventajas clave:
- Mayor seguridad de los datos: Protege la información sensible del acceso no autorizado.
- Cumplimiento normativo: Satisface los requisitos de regulaciones de protección de datos como GDPR y CCPA.
- Flexibilidad: Aplica diferentes reglas de enmascaramiento basadas en roles de usuario o elementos de datos específicos.
- Integración sin interrupciones: Enmascara datos de manera dinámica sin modificar la estructura subyacente de la base de datos.
- Mejora en pruebas y desarrollo: Proporciona datos realistas pero seguros para entornos que no son de producción.
Mejores Prácticas para la Implementación del Enmascaramiento Dinámico de Datos
Para maximizar la efectividad de tu estrategia de enmascaramiento de datos:
- Identifica datos sensibles: Realiza un proceso exhaustivo de descubrimiento de datos para localizar toda la información sensible.
- Define políticas claras: Establece reglas de enmascaramiento consistentes en toda tu organización.
- Realiza pruebas exhaustivas: Verifica que el enmascaramiento no interfiera con la funcionalidad de las aplicaciones.
- Monitorea y audita: Revisa periódicamente las reglas de enmascaramiento y su efectividad.
- Capacita a tu equipo: Asegúrate de que todas las partes interesadas comprendan la importancia del enmascaramiento de datos y cómo utilizarlo correctamente.
Conclusión
El enmascaramiento dinámico de datos para Amazon Redshift es una herramienta poderosa en el arsenal de la seguridad de datos moderna. Al implementar estrategias de enmascaramiento robustas, las organizaciones pueden proteger los datos sensibles, mantener el cumplimiento normativo y mitigar los riesgos asociados con las brechas de datos.
A medida que la protección de datos se vuelve cada vez más crítica, soluciones como DataSunrise ofrecen herramientas amigables para el usuario y de vanguardia para una seguridad integral de bases de datos. Además del enmascaramiento dinámico de datos, DataSunrise proporciona características como auditoría y descubrimiento de datos, mejorando aún más tu capacidad para salvaguardar información valiosa.
¿Listo para llevar la seguridad de tus datos en Amazon Redshift al siguiente nivel? Visita el sitio web de DataSunrise para una demo en línea y descubre cómo nuestras herramientas avanzadas pueden transformar tu enfoque hacia la protección de datos.
Siguiente
