
Enmascaramiento de Datos para Amazon Redshift: Asegure y Controle la Información Sensible

Introducción
Con el uso creciente de almacenes de datos en la nube como Amazon Redshift, las organizaciones enfrentan nuevos desafíos para salvaguardar sus valiosos datos. Los actores internos son responsables de casi la mitad (49%) de las brechas de datos en Europa, Oriente Medio y África, lo que indica la frecuente ocurrencia de amenazas internas tales como el abuso de privilegios y errores involuntarios de los empleados. Esta alarmante estadística destaca la importancia de implementar medidas de seguridad robustas, como el enmascaramiento de datos, para proteger la información sensible y asegurar el cumplimiento de las normativas.
Comprendiendo el Enmascaramiento de Datos para Amazon Redshift
El enmascaramiento de datos es una técnica poderosa utilizada para proteger la información sensible en Redshift, reemplazándola por datos ficticios pero realistas. Al aplicarse a Amazon Redshift, ayuda a las organizaciones a mantener la privacidad de los datos mientras permite a los usuarios autorizados acceder y analizar la información que necesitan.
¿Por qué es importante el enmascaramiento de datos?
- Protege los datos sensibles del acceso no autorizado
- Asegura el cumplimiento de normativas como GDPR y HIPAA
- Reduce el riesgo de brechas de datos y amenazas internas
- Permite el uso seguro de datos de producción en entornos no productivos
Capacidades Nativas de Enmascaramiento de Datos de Amazon Redshift
Amazon Redshift ofrece funciones integradas de enmascaramiento de datos que pueden ayudar a proteger la información sensible. Estas funciones permiten enmascarar datos directamente en sus consultas o vistas.
Funciones Clave de Enmascaramiento de Datos en Redshift
Utilizamos la siguiente tabla con datos sintéticos de mockaroo.com:
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email) values (1, 'Garvey', 'Dummer', '[email protected]'); insert into MOCK_DATA (id, first_name, last_name, email) values (2, 'Sena', 'Trevna', '[email protected]'); …
Al utilizar las funciones nativas de enmascaramiento, se pueden emplear construcciones tales como:
SELECT RIGHT(email, 4) AS masked_email FROM mock_data;
SELECT '[email protected]' AS masked_email FROM mock_data;
CREATE VIEW masked_users AS
SELECT
id,
LEFT(email, 1) || '****' || SUBSTRING(email FROM POSITION('@' IN email)) AS masked_email,
LEFT(first_name, 1) || REPEAT('*', LENGTH(first_name) - 1) AS masked_first_name
FROM mock_data;
SELECT * FROM masked_users;
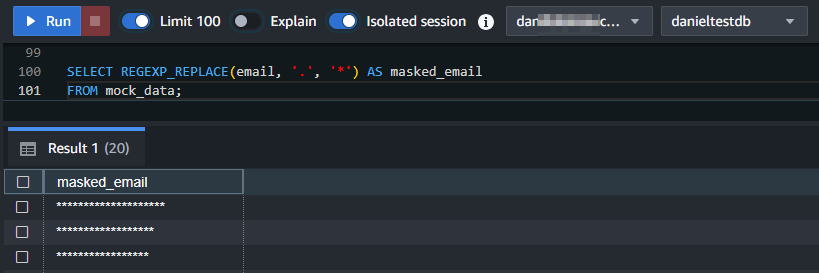
SELECT REGEXP_REPLACE(email, '.', '*') AS masked_email FROM mock_data;
El resultado del ejemplo de REGEXP_REPLACE se muestra a continuación:
Un enfoque más complejo puede implicar las funciones integradas de Python en Redshift.
-- Enmascarar Correo Electrónico --
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;
SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
Enmascaramiento de Datos Dinámico vs. Estático
Al implementar el enmascaramiento de datos para Amazon Redshift, es esencial comprender la diferencia entre el enmascaramiento dinámico y el estático.
Enmascaramiento Dinámico de Datos
El enmascaramiento dinámico aplica las reglas de enmascaramiento en tiempo real cuando se consulta la información. Este enfoque ofrece flexibilidad y no modifica los datos originales.
Beneficios del enmascaramiento dinámico:
- No se realizan cambios en los datos fuente
- Las reglas de enmascaramiento se pueden actualizar fácilmente
- Diferentes usuarios pueden ver distintos niveles de datos enmascarados
Enmascaramiento Estático de Datos
El enmascaramiento estático altera de forma permanente los datos en la base de datos. Este método se utiliza típicamente al crear copias de datos de producción para propósitos de pruebas o desarrollo.
Ventajas del enmascaramiento estático:
- Enmascaramiento consistente en todos los entornos
- Impacto reducido en el rendimiento de las consultas
- Idóneo para crear conjuntos de datos saneados
Creando una Instancia de DataSunrise para Enmascaramiento Dinámico de Datos
Para implementar un enmascaramiento dinámico avanzado en Amazon Redshift, puede utilizar soluciones de terceros como DataSunrise. Así es como puede empezar con DataSunrise:
- Inicie sesión en su panel de DataSunrise
- Navegue a la sección “Instancias”
- Haga clic en “Agregar Instancia” y seleccione “Amazon Redshift”
- Ingrese los detalles de conexión a su Redshift
La imagen a continuación muestra la instancia recién creada, la cual aparece al final de la lista.
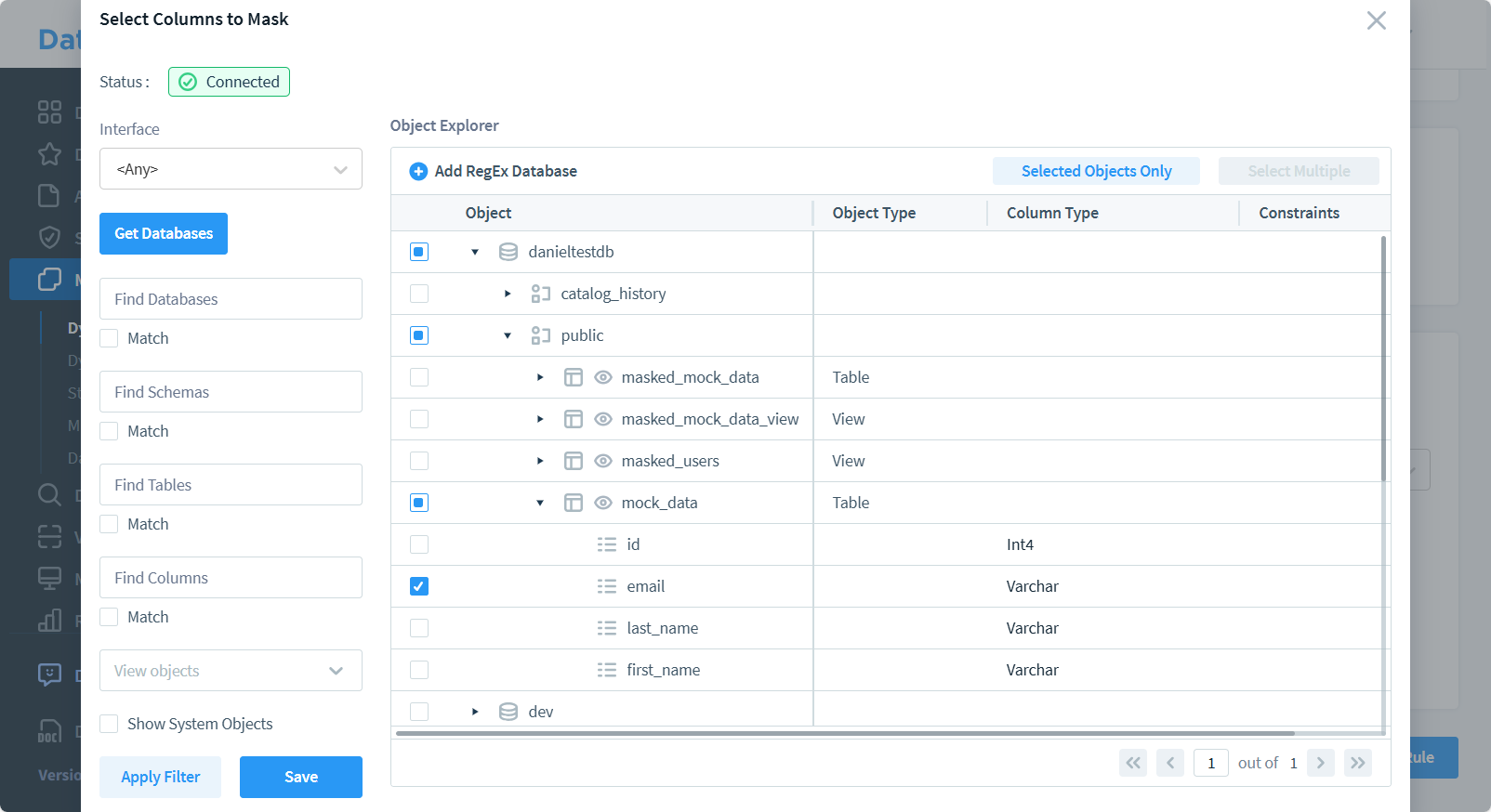
- Configure las reglas de enmascaramiento para las columnas sensibles
- Guarde y aplique la configuración
Una vez configurado, puede ver los datos enmascarados de forma dinámica realizando consultas a su instancia de Redshift a través del proxy de DataSunrise.
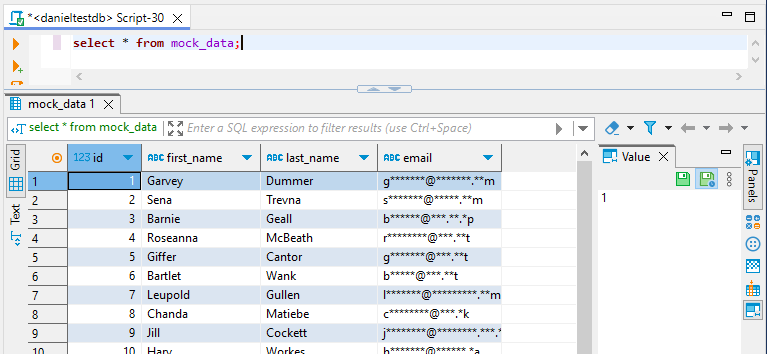
Observe que la columna de correo electrónico está enmascarada. Esto demuestra una regla de enmascaramiento dinámico en acción. Los datos se ofuscan en tiempo real a medida que se ejecuta la consulta, protegiendo la información sensible sin alterar los datos subyacentes.
Mejores Prácticas para el Enmascaramiento de Datos en Amazon Redshift
Para asegurar una protección de datos efectiva, siga estas mejores prácticas:
- Identificar y clasificar los datos sensibles
- Utilizar una combinación de técnicas de enmascaramiento
- Revisar y actualizar regularmente las reglas de enmascaramiento
- Monitorear el acceso a los datos enmascarados
- Capacitar a los empleados en políticas de privacidad de datos
Asegurando el Cumplimiento Normativo con el Enmascaramiento de Datos
El enmascaramiento de datos juega un papel crucial en el cumplimiento de las normativas. Al implementar estrategias de enmascaramiento robustas, las organizaciones pueden:
- Proteger la información de identificación personal (PII)
- Asegurar los principios de minimización de datos
- Mantener la integridad de los datos mientras se preserva la privacidad
- Demostrar la debida diligencia en los esfuerzos de protección de datos
Desafíos y Consideraciones
Si bien el enmascaramiento de datos ofrece beneficios significativos, es importante estar al tanto de posibles desafíos:
- Impacto en el rendimiento de las consultas
- Mantener la consistencia de datos entre sistemas
- Equilibrar la seguridad con la usabilidad de los datos
- Manejo de relaciones de datos complejas
Tendencias Futuras en el Enmascaramiento de Datos para Almacenes de Datos en la Nube
A medida que la adopción de la nube continúa creciendo, podemos esperar avances en las tecnologías de enmascaramiento de datos:
- Algoritmos de enmascaramiento potenciados por IA
- Integración con plataformas de gobernanza de datos
- Mayor compatibilidad entre nubes
- Informes automatizados de cumplimiento
DataSunrise ya ha implementado todas las tendencias de características mencionadas aquí, lo que convierte a nuestro producto en la solución líder para entornos de almacenamiento múltiple.
Conclusión
El enmascaramiento de datos para Amazon Redshift es un componente crítico de una estrategia integral de protección de datos. Al implementar técnicas de enmascaramiento efectivas, las organizaciones pueden salvaguardar la información sensible, asegurar el cumplimiento normativo y mitigar los riesgos asociados con las brechas de datos. A medida que evoluciona el panorama de amenazas, es crucial mantenerse informado sobre las últimas tecnologías y mejores prácticas de enmascaramiento de datos.
Para aquellos que buscan soluciones avanzadas de protección de datos, DataSunrise ofrece herramientas fáciles de usar y de vanguardia para la seguridad de bases de datos, que incluyen funciones de auditoría y descubrimiento de datos. Para experimentar el poder de la completa suite de protección de datos de DataSunrise, visite nuestro sitio web para una demostración en línea y dé el primer paso hacia la protección de sus valiosos activos de datos.
