
Generación de Datos Sintéticos

La generación de datos sintéticos se está convirtiendo rápidamente en un elemento fundamental del desarrollo moderno de IA, análisis avanzados y transformación digital orientada a la privacidad. Permite a las organizaciones crear conjuntos de datos realistas y estadísticamente precisos que reflejan la información del mundo real—sin exponer datos genuinos de clientes o corporativos. Este enfoque apoya la experimentación segura, el entrenamiento de aprendizaje automático y la validación de modelos, manteniéndose conforme con regulaciones de privacidad establecidas como GDPR, HIPAA y CCPA. Según un reciente informe de Gartner, casi la mitad de los ejecutivos globales ha incrementado su gasto en IA, subrayando la creciente necesidad de un uso responsable y seguro de los datos. Guías adicionales del Marco de Gestión de Riesgos de IA del NIST destacan el papel de los datos sintéticos en la reducción de sesgos y el soporte para un desarrollo de modelos más seguro. Capacidades como el enmascaramiento dinámico de datos mejoran aún más la habilidad de una organización para proteger información sensible a lo largo del proceso.
DataSunrise posiciona los datos sintéticos como una evolución natural de la protección de datos—complementando métodos existentes que incluyen enmascaramiento, cifrado y monitoreo de actividad en bases de datos. Esta funcionalidad capacita a las organizaciones para generar conjuntos de datos completamente anonimizados y de calidad productiva que conservan la estructura, relaciones y patrones estadísticos de los datos reales. Como resultado, los equipos pueden realizar pruebas, análisis y desarrollo en entornos seguros y controlados sin violar requisitos de privacidad o normativos. Los conjuntos sintéticos soportan una colaboración segura, aceleran la innovación y garantizan el cumplimiento en cada etapa del ciclo de vida de la IA.
Cuando se combina con automatización y controles inteligentes de políticas, los datos sintéticos no solo mejoran la protección y el cumplimiento regulatorio, sino que también aumentan la escalabilidad, agilidad operativa y continuidad. Permite a las empresas adoptar IA y análisis dentro de ecosistemas éticos y seguros, desbloqueando innovación mientras mantienen la confianza y alineación regulatoria.
¿Qué son los Datos Sintéticos?
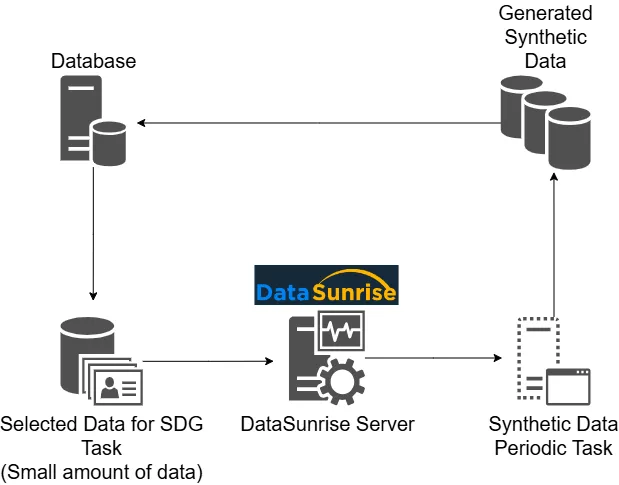
Los datos sintéticos se refieren a información creada artificialmente que refleja la estructura y el comportamiento estadístico de conjuntos de datos reales sin retener valores auténticos. Mantiene formatos, relaciones y distribuciones, permitiendo a los equipos desarrollar, probar y analizar de forma segura. Dado que no se utilizan registros genuinos, los conjuntos sintéticos eliminan riesgos de privacidad mientras permanecen altamente efectivos para modelado de IA, validación de sistemas y esfuerzos de cumplimiento.
Cuándo usar Datos Sintéticos vs. Enmascaramiento
El enmascaramiento estático o dinámico es ideal cuando necesitas conservar la estructura y lógica de datos productivos, pero aún deseas referencia a valores reales. Sin embargo, el enmascaramiento no puede compartirse externamente si el esquema fuente o los metadatos crean riesgo de reidentificación.
Los datos sintéticos son mejores cuando:
- Necesitas simular grandes conjuntos sin conexión a individuos reales
- El cumplimiento requiere cero exposición a valores productivos
- Estás trabajando con registros no estructurados o entrenando modelos de lenguaje grande (LLM)
Escenario: Por qué lo Sintético Supera al Enmascaramiento
Imagina un equipo de ciencia de datos entrenando un modelo de detección de anomalías. Los datos productivos enmascarados preservan estructura, pero correlaciones residuales aún pueden implicar riesgo de reidentificación. Los conjuntos sintéticos, en cambio, no tienen vínculo con clientes reales. El equipo obtiene datos estadísticamente fieles para pipelines de IA, mientras que los oficiales de cumplimiento tienen la tranquilidad de que nada identificable sale del entorno productivo.
Los datos sintéticos no son solo una herramienta de desarrollo, sino un acelerador de cumplimiento. Al generar registros seguros para la privacidad, las empresas reducen riesgos regulatorios, aceleran la adopción de IA y posibilitan colaboración segura con proveedores.
Cuando se combina con enmascaramiento, la generación sintética crea un modelo híbrido: retener integridad referencial para flujos que la necesitan y generar registros totalmente artificiales para pruebas, compartición o entrenamiento de IA. Este enfoque combinado asegura cumplimiento sin frenar la innovación.
Datos Sintéticos — Resumen, Pasos, Validación
Resumen
- Objetivo: crear conjuntos de datos seguros para la privacidad que preserven el esquema y propiedades estadísticas sin exponer registros reales.
- Uso cuando: compartir externamente, entrenamiento de LLM/ML, provisión no productiva o políticas que requieran cero vinculación con individuos.
- Combinación: combinar con enmascaramiento para flujos híbridos que necesiten integridad referencial en áreas limitadas.
Pasos de Implementación
- Definir alcance y propósito (aseguramiento de calidad, análisis, entrenamiento de LLM, compartición con proveedores).
- Catalogar esquema, restricciones y campos sensibles (PII/PHI/PCI) para guiar a los generadores.
- Seleccionar modo de generación (integrado/consciente de políticas en la plataforma, o OSS como SDV/CTGAN/Mockaroo para prototipos).
- Elegir estrategias por columna (sustitución, modelos estadísticos, FPE donde importe forma).
- Preservar relaciones (claves/foráneas) o simular con reglas deterministas donde se requiera.
- Ejecutar piloto en subconjunto; registrar parámetros para reproducibilidad.
- Validar calidad (distribución, correlaciones, distancia de privacidad); ajustar generadores.
- Programar tareas; registrar logs y controlar acceso según política de gobernanza.
Lista de Verificación para Validación
| Verificación | Qué confirmar | Notas |
|---|---|---|
| Distribución | Media/varianza, percentiles dentro de tolerancia | Test KS por columna numérica |
| Correlaciones | Correlaciones clave por pares preservadas (±Δ) | Comparar matrices de correlación |
| Privacidad | Ninguna fila sintética demasiado cercana a muestras reales | Distancia de vecino más cercano |
| Restricciones | Unicidad, formatos, dominios respetados | Checks con expresiones regulares/rangos |
Verificaciones Rápidas
- Documentar generadores, semillas y reglas para reproducibilidad.
- Mantener datasets sintéticos y reales aislados; prohibir uniones entre ellos.
- Para tests UI/integración que requieran integridad referencial estricta, considerar un enfoque híbrido (base enmascarada + expansiones sintéticas).
- Aplicar mismos controles de acceso y políticas de retención a datasets sintéticos usados fuera de la organización.
Casos de Uso de Datos Sintéticos de DataSunrise
| Caso de Uso | Descripción | Ejemplo |
|---|---|---|
| Pruebas de Cumplimiento | Simular conjuntos de datos reales para validar lógica sin usar datos de clientes reales. | Ejecutar algoritmos de detección de fraude en transacciones bancarias generadas. |
| Entrenamiento de IA y ML | Entrenar modelos con conjuntos realistas pero no identificables para evitar incumplimientos regulatorios. | Construir modelos diagnósticos a partir de historiales médicos sintéticos. |
| Preparación y QA | Poblar entornos de prueba con datos vívidos para pruebas UI, de carga o integración. | Rellenar un clúster PostgreSQL de desarrollo con perfiles sintéticos de usuarios. |
| Colaboración Segura | Compartir conjuntos sintéticos entre equipos o con socios sin exponer información sensible. | Proveer registros sintéticos de RRHH a un proveedor externo de análisis. |
¿Qué hace que los Datos Sintéticos de DataSunrise sean Diferentes?
Mientras muchas plataformas ofrecen generación de datos artificiales, pocas lo integran directamente en pipelines de seguridad y cumplimiento de nivel empresarial. Las herramientas de Datos Sintéticos de DataSunrise están estrechamente acopladas con enmascaramiento, auditoría y aplicación de políticas—haciéndolas ideales para uso real en entornos regulados.
- Respaldo integrado de enmascaramiento: Cambio fluido entre enmascaramiento y generación según contexto de acceso o tipo de esquema.
- Generación consciente de políticas: Definir reglas que se alinean con filtros de cumplimiento y etiquetas de datos sensibles.
- Flujos programados: Automatizar creación de datasets sintéticos a través de entornos, aplicaciones y pipelines CI/CD.
- Registro de auditoría: Rastrear cada tarea de generación para trazabilidad completa y preparación para auditorías.
Tanto si pruebas aplicaciones internas como entrenas modelos de IA, Datos Sintéticos de DataSunrise brindan al equipo la flexibilidad de simular cargas productivas—sin arriesgar datos reales.
Cómo Configurar la Generación de Datos Sintéticos en DataSunrise
Paso 1: Establecer Parámetros Generales
Navega a Configuración → Tareas Periódicas y crea una nueva tarea. Selecciona “Generación de Datos Sintéticos” como tipo, y nombra la tarea acorde.
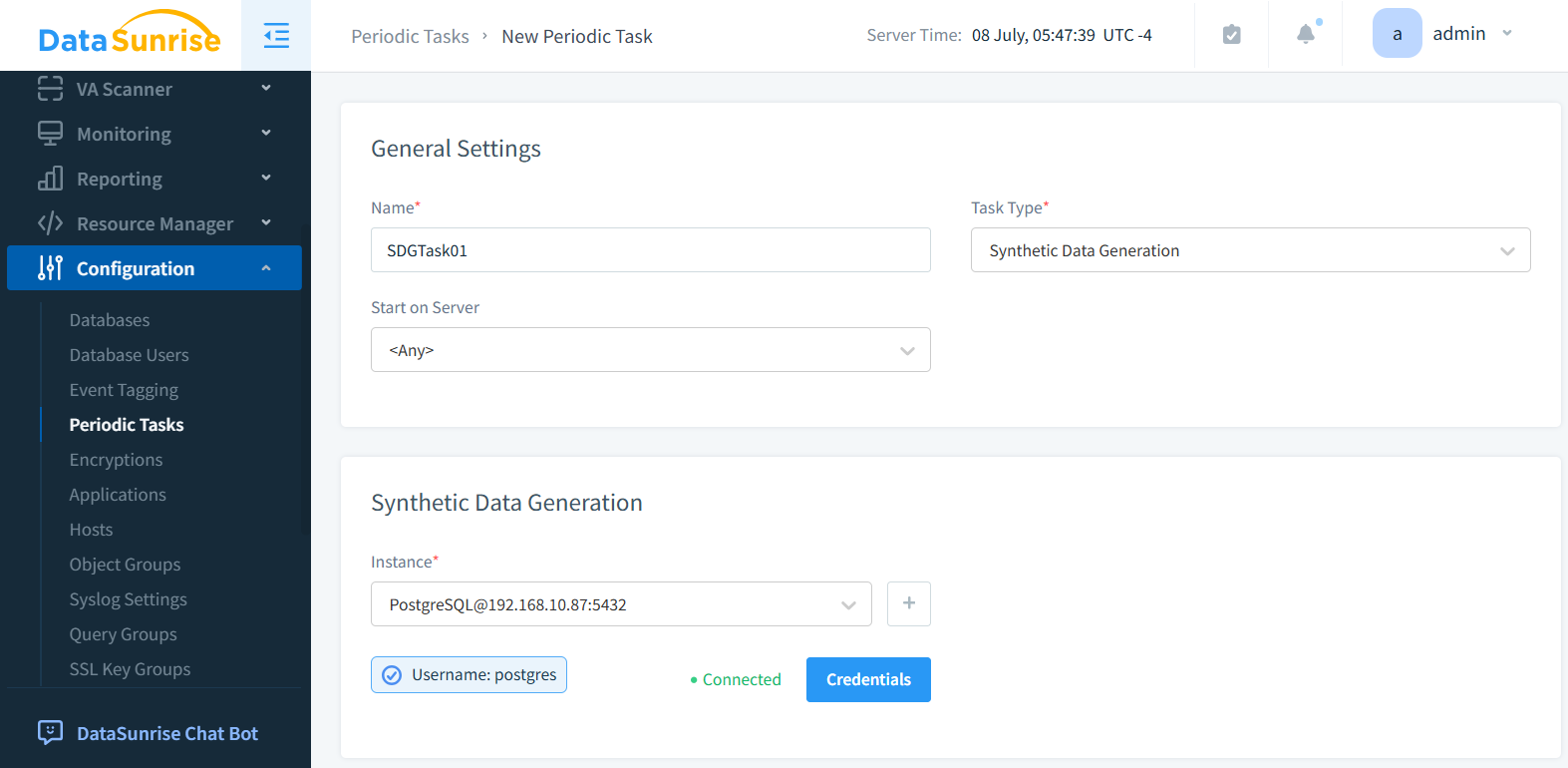
Paso 2: Seleccionar la Instancia de Base de Datos
Elige tu instancia objetivo. A continuación, se muestra PostgreSQL seleccionado como motor de base de datos.
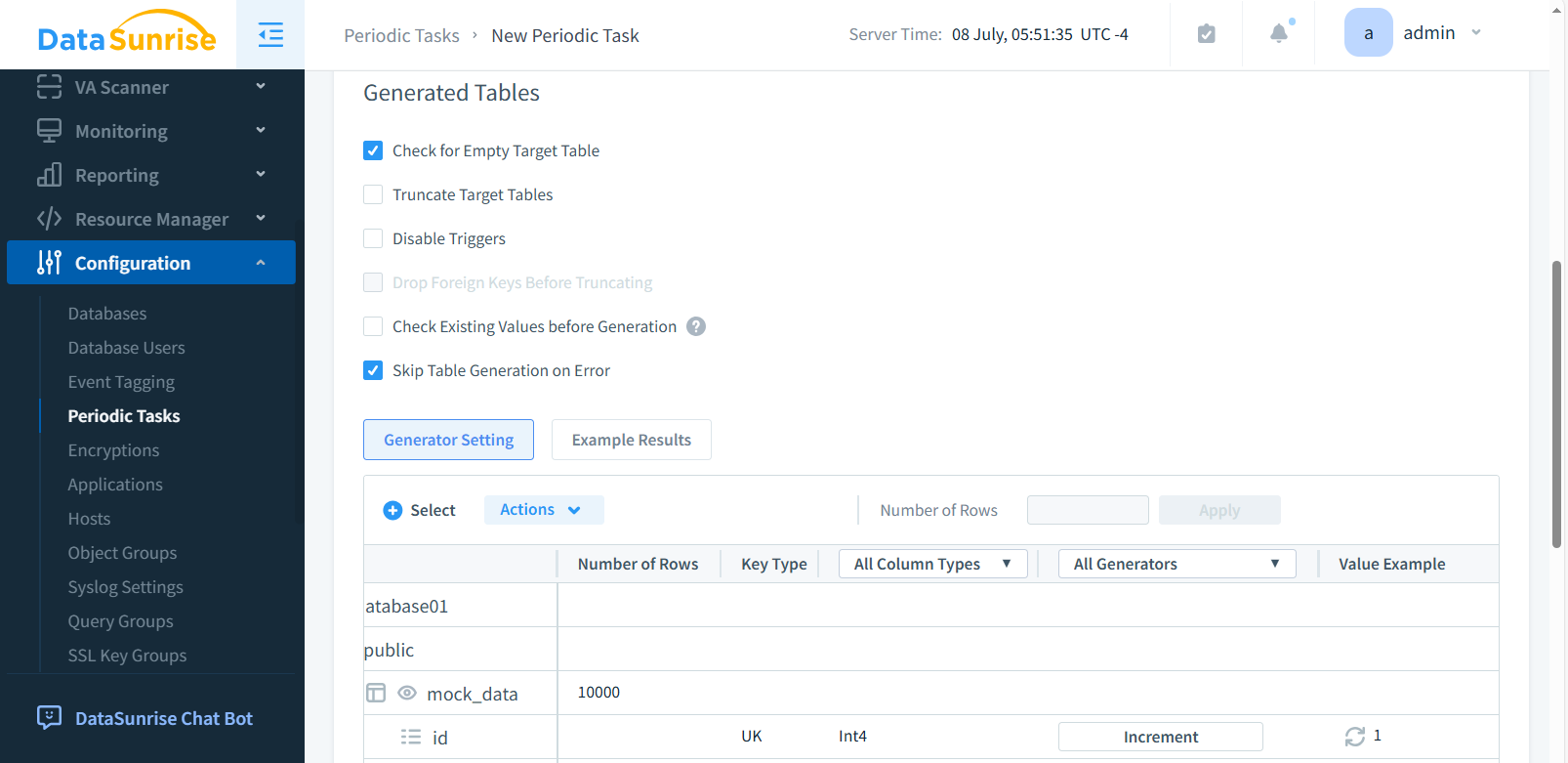
Paso 3: Definir Tablas y Columnas Destino
Selecciona esquema y tablas donde se inyectarán datos sintéticos. Escoge columnas específicas, habilita “Vaciar tabla” si es necesario, y configura el manejo de errores.
Paso 4: Usar Generadores Integrados o Personalizados
Escoge entre generadores integrados de valores (nombres, correos, números, fechas) o define lógica personalizada vía Configuración → Generadores. Esto es útil para patrones específicos de dominio, como simular IDs de pacientes o códigos fiscales.
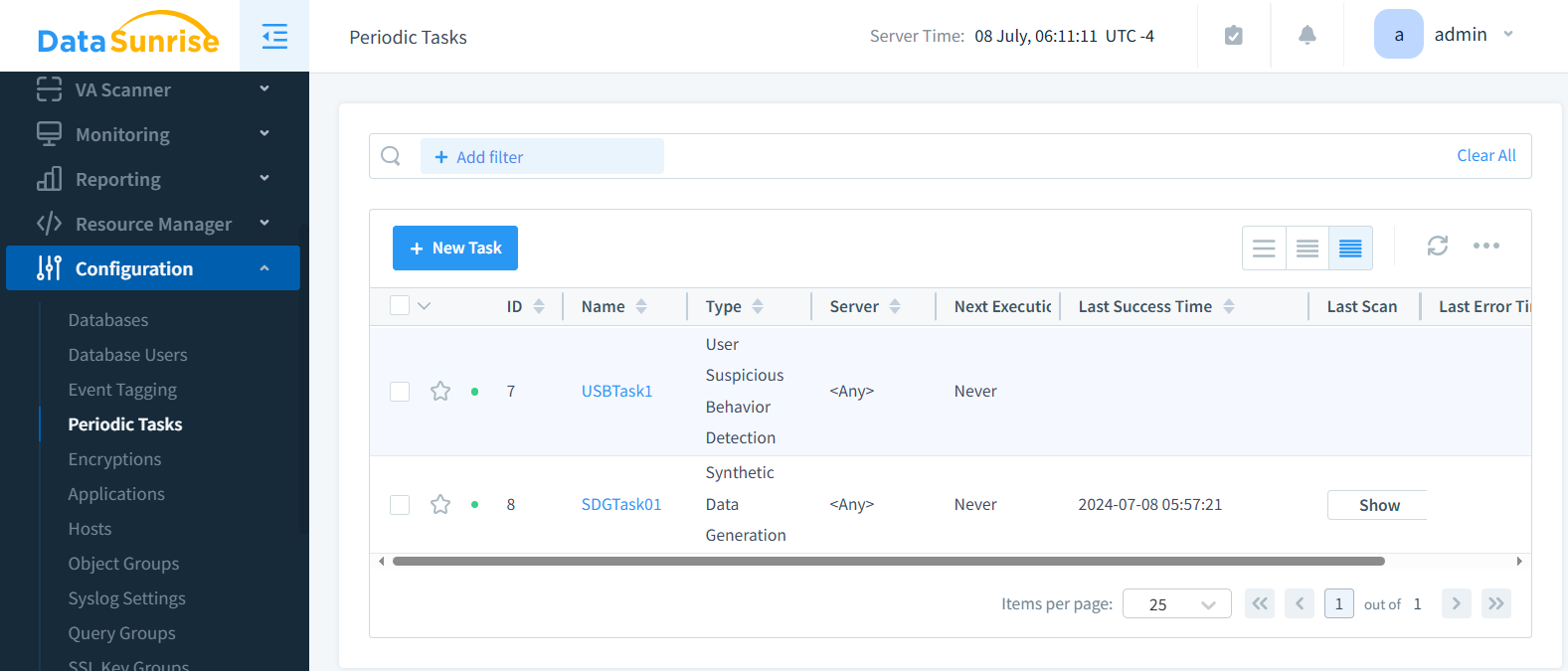
Paso 5: Guardar, Programar y Ejecutar
Una vez guardada, la tarea aparece en tu lista de trabajos. Puedes ejecutarla a demanda o programar ejecuciones periódicas para actualización continua.
Herramientas y Bibliotecas Gratis para Datos Sintéticos
DataSunrise ofrece soporte integral para generación sintética con enmascaramiento, auditoría y controles de cumplimiento. Pero desarrolladores y científicos de datos también pueden beneficiarse de alternativas gratuitas para aprendizaje o prototipos.
SDV (Synthetic Data Vault)
SDV es un framework Python de código abierto que usa modelos estadísticos y GANs para generar conjuntos tabulares sintéticos. Soporta estructuras relacionales y multi-tabla.
pip install sdv
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
real_data, metadata = download_demo(modality='single_table', dataset_name='fake_hotel_guests')
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
synthetic_data = synthesizer.sample(num_rows=500)
print(synthetic_data.head())
CTGAN
Modelo basado en GANs adaptado para datos tabulares, CTGAN funciona bien con conjuntos desequilibrados y tipos de columnas mixtos. Consulta nuestro artículo previo sobre generación de datos AI para código de ejemplo.
Mockaroo
Mockaroo es una herramienta web para generar datasets simulados en formatos CSV, JSON, SQL y otros. Es ideal para prototipos rápidos y soporta esquemas de campos personalizados. El uso gratuito está limitado a 1,000 filas por sesión.
Validación de Calidad de Datos Sintéticos
Generar registros sintéticos es solo la mitad del trabajo. Necesitas confirmar que los datos se comportan como el conjunto real sin exponer valores sensibles. Las verificaciones comunes incluyen:
- Similitud de distribución: Comparar distribuciones de columnas entre datos reales y sintéticos.
- Preservación de correlaciones: Asegurar que las relaciones entre campos se mantengan intactas.
- Distancia de privacidad: Confirmar que ninguna fila sintética sea demasiado cercana a un registro real.
Ejemplo en Python: Test Kolmogorov–Smirnov
from scipy.stats import ks_2samp
# Comparar distribuciones reales vs sintéticas por columna
ks_stat, p_value = ks_2samp(real_data["age"], synthetic_data["age"])
if p_value > 0.05:
print("La distribución sintética de 'edad' coincide con la real")
else:
print("Diferencia significativa detectada")
Chequeo de Matriz de Correlación
import pandas as pd
real_corr = real_data.corr(numeric_only=True)
synth_corr = synthetic_data.corr(numeric_only=True)
diff = (real_corr - synth_corr).abs()
print(diff.head())
Estos pasos de validación aseguran que tus datos sintéticos sean útiles para pipelines de análisis y ML, mientras permanecen seguros para cumplimiento.
Buenas Prácticas para Datos Generados
- Coincidir formatos con expectativas posteriores.
Asegura que los valores sintéticos sigan los mismos patrones—tipos de datos, rangos, formatos y restricciones—para que aplicaciones, pipelines y herramientas analíticas funcionen sin modificaciones. - Preservar relaciones tabulares donde sea necesario.
Mantener dependencias clave como claves primarias/foráneas, jerarquías y tablas de referencia para conservar flujos, uniones y lógica de negocio correctamente. - Documentar reglas de generación para reproducibilidad.
Registrar la lógica, semillas y reglas de transformación usadas para crear el dataset y apoyar regeneración consistente, auditoría y resolución de problemas. - Ejecutar chequeos de coherencia para validar lógica.
Verificar que distribuciones, rangos y comportamientos luzcan realistas—capturando anomalías como valores fuera de rango, campos vacíos o relaciones rotas desde temprano. - Usar enmascaramiento o exclusiones para evitar solapamientos con datos reales.
Confirmar que los valores sintéticos no puedan rastrearse hasta información real de clientes, reduciendo riesgo de reidentificación y fortaleciendo cumplimiento.
Comparación Rápida
| Herramienta | Ideal para | Limitaciones |
|---|---|---|
| SDV | Simulación estadística de datos tabulares | Sólo Python, requiere ajuste |
| CTGAN | Conjuntos complejos y desequilibrados | Entrenamiento lento, puede requerir GPU |
| Mockaroo | Prototipos rápidos CSV/JSON/SQL | Límites de filas, no consciente de esquema |
Datos Sintéticos en Marcos de Cumplimiento
La generación de datos sintéticos se alinea naturalmente con regulaciones modernas al eliminar identificadores directos mientras preserva valor analítico. Así encaja con marcos comunes:
| Marco | Requisito | Cómo ayudan los Datos Sintéticos |
|---|---|---|
| GDPR | Art. 32 — seudonimización y minimización de datos personales | Genera registros artificiales sin vínculo con individuos reales, cumpliendo con seudonimización y minimización. |
| HIPAA | §164.514 — desidentificación de identificadores PHI | Produce registros no identificables de salud para investigación y pruebas mientras protege PHI. |
| PCI DSS | Req. 3.4 — prevenir almacenamiento de PAN en entornos de prueba | Registros sintéticos de pagos permiten QA y compartición con proveedores sin exponer datos reales. |
| SOX | §404 — garantizar integridad de datos financieros para auditoría | Provee datos seguros para auditoría para validar sistemas financieros sin riesgo para registros productivos. |
Al alinear la generación sintética con estos marcos, DataSunrise ayuda a las organizaciones a acelerar adopción de IA y análisis mientras permanecen listas para auditorías y en cumplimiento.
Cuando los Datos Sintéticos No Son Suficientes: Consideraciones y Controles
Si bien los datos generados sintéticamente ofrecen fuertes garantías de privacidad y flexibilidad, no son un reemplazo universal para los datos reales o los flujos de trabajo empresariales de enmascaramiento. Algunos escenarios—como pruebas de integridad referencial, uniones deterministas o análisis longitudinal—pueden aún requerir acceso controlado a datasets enmascarados o seudonimizados.
Para asegurar que los datos generados sirvan efectivamente a tus objetivos, considera estas pautas:
- Alineación con casos de uso: Para validación de modelos, usa datos totalmente sintéticos. Para pruebas de integración o UI, clones productivos enmascarados pueden ser más precisos.
- Documentación de gobernanza: Registra qué campos fueron generados sintéticamente, cuáles preservados y qué herramientas o lógicas se usaron.
- Muestreo vs simulación: No confundas muestreo aleatorio de datos reales con generación sintética. Solo esta última rompe la vinculación con sujetos identificables.
- Preparación para auditoría: Mantén registros de tareas de generación, tiempos de retención y controles de acceso—especialmente si datos sintéticos entran en pipelines compartidos con proveedores o contratistas.
DataSunrise ayuda a conectar estas decisiones con automatización, opciones de respaldo de enmascaramiento y visibilidad completa a través de tipos de datos y entornos. El resultado son flujos de datos más seguros, inteligentes y rápidos—sin compromisos de cumplimiento.
Puntos Clave para Usar Datos Sintéticos de Forma Efectiva
- Elige datos sintéticos cuando el cumplimiento requiera cero exposición a registros reales, o al compartir datasets externamente.
- Combina generación sintética con enmascaramiento para escenarios híbridos—manteniendo integridad relacional donde sea necesario y reemplazando completamente campos de alto riesgo.
- Documenta reglas de generación, políticas de retención y controles de acceso para mantener gobernanza y preparación para auditorías.
- Prueba los datasets sintéticos contra flujos reales para confirmar que cumplen requisitos de rendimiento, precisión y compatibilidad.
- Automatiza las tareas de generación mediante programación e integración con pipelines CI/CD para resultados consistentes y repetibles.
Preguntas Frecuentes sobre Datos Sintéticos
¿Qué son los datos sintéticos?
Los datos sintéticos son información generada artificialmente que refleja la estructura y propiedades estadísticas de conjuntos reales, pero no contiene registros reales de clientes. Permite pruebas, análisis y entrenamiento de IA seguros sin riesgo de privacidad.
¿En qué se diferencian los datos sintéticos del enmascaramiento?
El enmascaramiento altera valores reales para ocultar identificadores, preservando esquema e integridad referencial. Los datos sintéticos, en cambio, crean registros totalmente artificiales sin vínculo con personas reales, siendo más seguros para compartición externa y pipelines de IA.
¿Cuándo deberían las organizaciones usar datos sintéticos?
Los datos sintéticos son ideales para casos donde el cumplimiento exige cero exposición a registros reales—como colaboración con proveedores externos, entrenamiento de LLM, o populate entornos no productivos a escala.
¿Qué marcos regulatorios soportan datos sintéticos?
Marcos como GDPR, HIPAA y PCI DSS reconocen técnicas de seudonimización y desidentificación. La generación sintética es un camino efectivo a cumplimiento cuando se combina con gobernanza.
¿Cuáles son las limitaciones de los datos sintéticos?
Pueden no replicar completamente uniones complejas, historiales longitudinales o patrones atípicos raros. Para estos escenarios, muchas organizaciones combinan enmascaramiento con generación sintética en flujos híbridos.
¿Cómo apoya DataSunrise a los datos sintéticos?
DataSunrise integra generación sintética con enmascaramiento, auditoría y reportes de cumplimiento. Proporciona generadores conscientes de políticas, workflows programados y trazabilidad completa.
Aplicaciones Industriales de Datos Sintéticos
Los datos sintéticos apoyan más que pruebas—habilitan directamente cumplimiento e innovación en diversas industrias:
- Finanzas: Generar logs artificiales de transacciones para entrenamiento de modelos antifraude, cumpliendo requisitos PCI DSS y SOX sin exponer PANs.
- Salud: Crear datasets desidentificados de pacientes alineados con HIPAA, permitiendo investigación segura y desarrollo de IA diagnóstica.
- SaaS y Cloud: Proveer datasets conformes GDPR para entornos staging, validando aislamiento multi-inquilino.
- Gobierno: Compartir datasets poblacionales con contratistas mientras se cumplen GDPR y leyes locales de privacidad.
- Retail y eCommerce: Poblar pipelines analíticos con trayectorias de clientes sintéticas para probar motores de personalización sin riesgo de privacidad.
Al contextualizar datos sintéticos para cada industria, las organizaciones aceleran innovación mientras permanecen listas para auditorías y seguras para la privacidad.
El Futuro de la Generación de Datos Sintéticos
Los datos sintéticos evolucionan rápidamente de una utilidad para pruebas a un componente central de la estrategia de datos empresarial. A medida que las organizaciones buscan innovar responsablemente, las plataformas de próxima generación combinarán generación impulsada por IA, validación de calidad y controles automáticos de cumplimiento para crear datasets realistas pero completamente anonimizados a escala. Estos sistemas no solo reproducirán precisión estadística e integridad estructural, sino que se adaptarán dinámicamente a cambios en modelos de datos, requisitos de privacidad y marcos regulatorios.
Las soluciones futuras ofrecerán integración fluida con tecnologías complementarias como enmascaramiento de datos, monitoreo de actividad en bases de datos y descubrimiento de datos sensibles. Esta interoperabilidad permitirá que las organizaciones transicionen fluidamente entre datos reales, enmascarados y sintéticos según contexto—habilitando análisis seguros, entrenamiento de modelos y colaboración externa sin exponer información regulada. Con el tiempo, este ecosistema adaptativo hará que la innovación que preserva la privacidad sea la norma y no la excepción. Capacidades como la automatización del cumplimiento garantizarán además que los datasets sintéticos cumplan consistentemente con requisitos regulatorios y organizacionales.
Para sectores altamente regulados como finanzas, salud y gobierno, los datos sintéticos redefinirán el balance entre cumplimiento e innovación. Las empresas podrán acelerar la adopción de IA, colaborar de forma segura con terceros y mantener pruebas verificables de que ningún dato auténtico del cliente salió de entornos controlados. En última instancia, el futuro de la generación de datos sintéticos radica en la automatización inteligente y el cumplimiento continuo, transformando la privacidad en un motor de progreso y no en una limitación.
Conclusión
Los datos sintéticos se han convertido en un componente clave de las estrategias modernas de gestión de datos con prioridad en la privacidad, proporcionando una alternativa segura y compatible con regulaciones para usar conjuntos productivos en desarrollo, pruebas, análisis y aprendizaje automático. Al reflejar la estructura, características estadísticas y relaciones de datos reales—sin retener información personalmente identificable o propietaria—permite a las organizaciones innovar, colaborar y analizar con seguridad. Este enfoque privacy-by-design minimiza riesgos de cumplimiento, reduce responsabilidades legales y apoya despliegues éticos de IA en sectores como finanzas, salud, telecomunicaciones y dominio público.
DataSunrise incorpora generación de datos sintéticos dentro de su plataforma integral de seguridad y gobernanza de datos. Mediante aplicación automatizada de políticas, lógica avanzada de enmascaramiento y trazabilidad detallada, la plataforma asegura que los conjuntos sintéticos cumplan tanto con marcos de gobernanza interna como con estándares externos como GDPR, HIPAA, SOX y PCI DSS. Esto permite a las empresas producir datos realistas pero totalmente anonimados aptos para entrenamiento de IA, pruebas de software y colaboración con terceros—sin riesgo de exposición de contenido sensible o confidencial.
Al integrarse con soluciones como el Monitoreo de Actividad en Bases de Datos (DAM), descubrimiento de datos y enmascaramiento dinámico, los datos sintéticos se convierten en un habilitador poderoso para la transformación digital segura. Permiten a las organizaciones acelerar innovación mientras mantienen transparencia y cumplimiento, apoyando la experimentación responsable y la mejora continua. A medida que evolucionan las regulaciones de privacidad y avanzan las tecnologías de IA, los datos sintéticos seguirán siendo un elemento fundamental de la innovación segura, ética y escalable basada en datos.
Siguiente
