
Enfoques de enmascaramiento de datos en flujos de trabajo de IA y LLM

A medida que la inteligencia artificial (IA) y los modelos de lenguaje a gran escala (LLM) transforman los flujos de trabajo empresariales modernos, proteger los datos sensibles se ha vuelto más crucial que nunca. El enmascaramiento de datos ayuda a resolver este desafío sin frenar la innovación. En este artículo, exploramos enfoques prácticos de enmascaramiento de datos en flujos de trabajo de IA y LLM, con un enfoque en salvaguardas en tiempo real e integración del cumplimiento.
Por qué el enmascaramiento de datos es crucial en los flujos de trabajo de IA
Los modelos de IA generativa a menudo procesan entradas sensibles como registros internos, correos electrónicos, datos personales y registros financieros. Estos sistemas pueden almacenar o reproducir estos datos de forma no intencional. El enmascaramiento previene estos riesgos al ocultar o modificar la información sensible antes de que llegue al modelo.
Por ejemplo, si una solicitud ajustada de un LLM incluye el nombre y el número de teléfono de un cliente real, el modelo podría memorizarlos y reutilizarlos. Una capa de enmascaramiento previene esto al reemplazar los identificadores antes de su ingestión. La política de uso de datos de OpenAI explica cómo los LLM pueden retener el contenido del usuario de manera no intencionada.
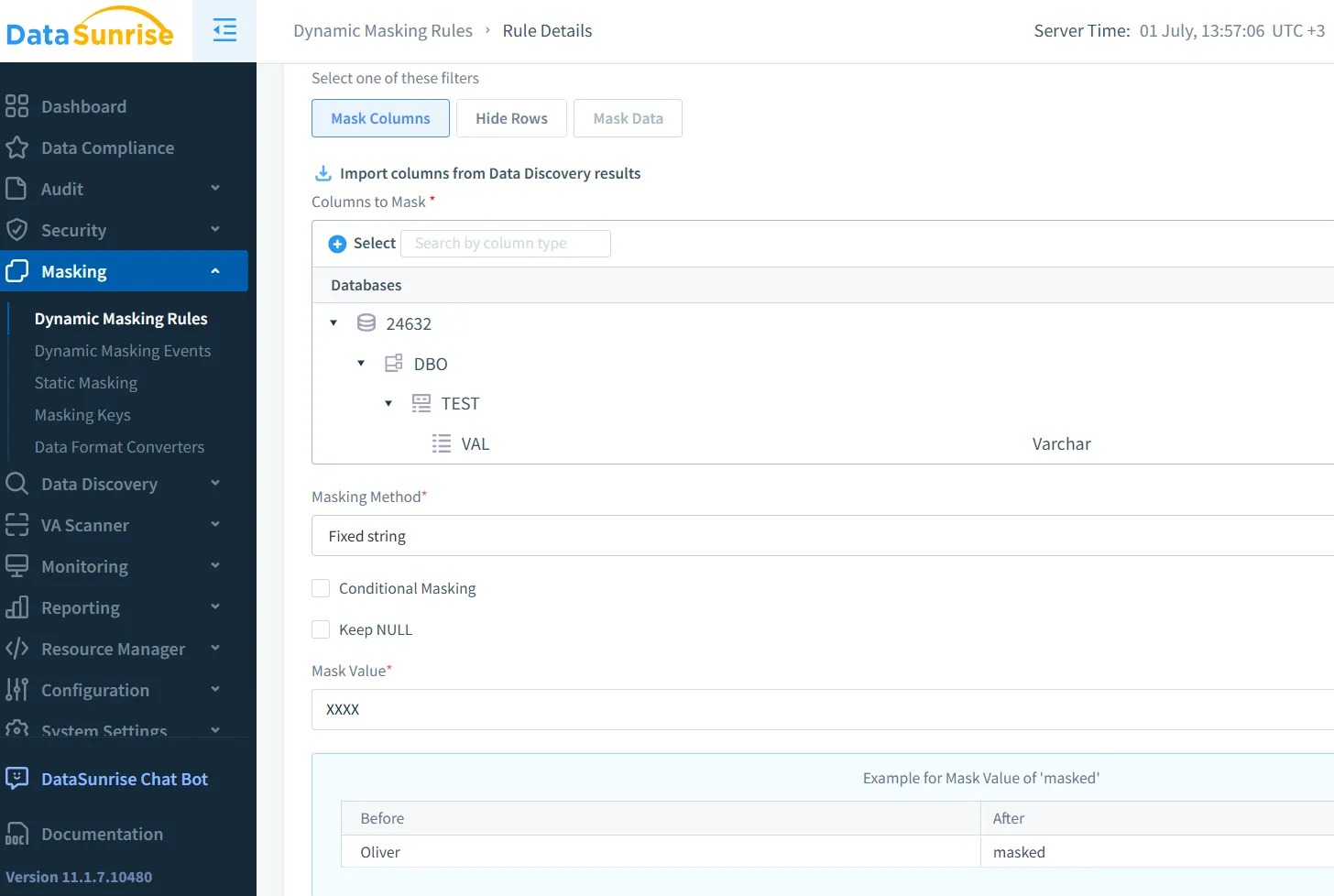
Enmascaramiento estático y dinámico en contextos de LLM
Enmascaramiento estático para el preprocesamiento
El enmascaramiento estático modifica los datos sensibles en reposo y se utiliza a menudo durante la preparación del conjunto de datos. El enmascaramiento estático de DataSunrise transforma permanentemente las exportaciones, preservando la estructura.
Google Cloud DLP admite un enmascaramiento estático similar, incluyendo técnicas que preservan el formato para datos estructurados.
Enmascaramiento dinámico para uso en tiempo real
El enmascaramiento dinámico opera sobre datos en vivo. Por ejemplo, cuando los LLM procesan solicitudes de usuarios, los motores de enmascaramiento pueden suprimir números de tarjetas de crédito o identificaciones nacionales antes de que el modelo los vea. El enmascaramiento dinámico de DataSunrise es muy adecuado para este uso en producción.
Amazon Macie ofrece un servicio relacionado que escanea y enmascara datos en entornos de AWS. Vea más en este post de AWS.
Enmascaramiento de solicitudes en LLM en la práctica
Considere un chatbot de atención al cliente que utiliza un LLM. Los mensajes a menudo incluyen datos privados. Una regla dinámica podría verse así:
CREATE MASKING RULE mask_pii
ON inbound_messages.content
WHEN content LIKE '%SSN%'
REPLACE WITH '***-**-****';
Esta regla evita que los modelos accedan a números de Seguro Social en bruto.
Al aplicar esta lógica en la capa middleware, los equipos no necesitan cambiar el modelo. Las herramientas de seguridad para LLM y ML de DataSunrise ayudan a automatizar este proceso utilizando una detección contextual.
La guía de arquitectura de Microsoft también destaca el enmascaramiento en tiempo real y el uso responsable de datos en los flujos de trabajo de LLM.
Del enmascaramiento a los controles de acceso contextuales
El enmascaramiento es más efectivo cuando se combina con controles de acceso basados en roles, registros de auditoría y análisis de comportamiento. Un desarrollador en preproducción puede ver datos realistas pero falsos, mientras que las entradas de producción permanecen redactadas.
Cuando se conecta a herramientas de monitoreo de actividad, los equipos pueden detectar accesos sin enmascarar o activar alertas. El enmascaramiento se convierte entonces en una capa de seguridad, no solo en una solución de privacidad.
Este diseño se alinea con los principios de Zero Trust del NIST, que priorizan la visibilidad restringida y la aplicación estricta de políticas.
Datos sintéticos como alternativa al enmascaramiento
En lugar de enmascarar datos reales, muchos equipos ahora generan datos sintéticos para entrenar o probar modelos de IA. Estos conjuntos de datos preservan el esquema y la lógica sin exponer a personas reales.
El ICO del Reino Unido reconoce los datos sintéticos como un método para preservar la privacidad bajo el GDPR, especialmente para el desarrollo de IA y ML.
Impulsores de cumplimiento y gestión de riesgos en IA
Regulaciones como el GDPR, HIPAA y PCI DSS requieren que las organizaciones justifiquen, anonimicen o enmascaren los datos sensibles durante el procesamiento. El enmascaramiento respalda estos requisitos a través de la minimización de datos y el control de riesgos.
También se integra en modelos de seguridad basados en datos, donde la gobernanza y la protección están integradas en cada capa.
Patrones de implementación en el mundo real
En sistemas del mundo real, el enmascaramiento típicamente ocurre a través de:
- Scripts de preprocesamiento para datos de entrenamiento
- Motores middleware para enmascaramiento en tiempo de ejecución
- Enmascaramiento mediante proxy inverso para salidas
- Auditoría de registros de inferencia
Utilizando un proxy inverso, los desarrolladores pueden interceptar y redactar datos sensibles antes de que lleguen al modelo o a los registros.
Este enfoque en capas no solo mejora la protección, sino que genera confianza. Los usuarios son más propensos a interactuar cuando saben que sus datos de entrada permanecen privados.
Conclusión: Construyendo pipelines de LLM más seguros
El enmascaramiento no es solo un requisito de cumplimiento. Es una decisión de diseño que define cuán segura opera su IA. Tanto el enmascaramiento estático como dinámico juegan roles críticos en la protección de los datos de los usuarios a lo largo del ciclo de vida.
Cuando se combinan con herramientas de descubrimiento, políticas de auditoría y automatización de seguridad, estas técnicas ayudan a construir sistemas de IA que son seguros por diseño.
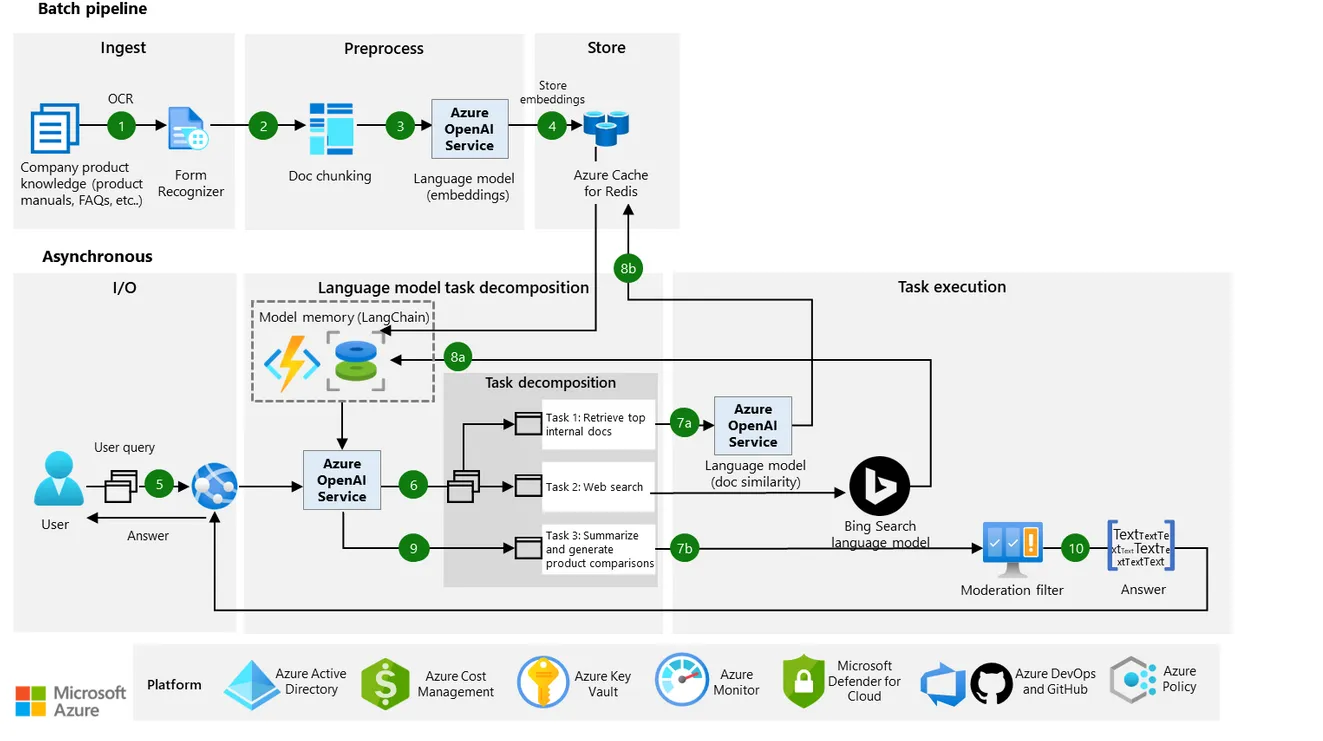
Para equipos que escalan GenAI, la estrategia de enmascaramiento adecuada puede prevenir brechas, reducir la responsabilidad y proteger a los usuarios sin obstaculizar la innovación.
Protege tus datos con DataSunrise
Protege tus datos en cada capa con DataSunrise. Detecta amenazas en tiempo real con Monitoreo de Actividad, Enmascaramiento de Datos y Firewall para Bases de Datos. Garantiza el Cumplimiento de Datos, descubre información sensible y protege cargas de trabajo en más de 50 integraciones de fuentes de datos compatibles en la nube, en instalaciones y sistemas de IA.
Empieza a proteger tus datos críticos hoy
Solicita una Demostración Descargar Ahora