
Das Potenzial der Generierung synthetischer Daten
In der heutigen datengetriebenen Welt steigt die Nachfrage nach vielfältigen Datensätzen für verschiedene Zwecke wie Testen, Training und Entwicklung. Das Beschaffen von Echtwelt-Daten bringt jedoch Herausforderungen mit sich, wie Datenschutzbedenken, Datenzugriffsprobleme und regulatorische Einschränkungen. Die Generierung synthetischer Daten bietet eine Lösung für diese Herausforderungen, indem künstliche Daten erstellt werden, die die Eigenschaften echter Daten widerspiegeln, ohne Privatsphäre oder Sicherheit zu gefährden. In diesem Artikel werfen wir einen genaueren Blick auf synthetische Daten und die Funktion zur Generierung synthetischer Daten, die von DataSunrise bereitgestellt wird.
Verständnis von synthetischen Daten
Synthetische Daten sind künstlich erzeugte Daten, die echten Daten in Bezug auf statistische Eigenschaften, Muster und Strukturen ähneln. Sie enthalten jedoch keinerlei tatsächliche Informationen über Einzelpersonen oder Entitäten. Sie werden mithilfe von Algorithmen und mathematischen Modellen erstellt, um Authentizität zu bewahren und gleichzeitig die Risiken beim Umgang mit sensiblen Daten zu vermeiden.
In einfacheren Worten sind synthetische Daten wie eine virtuelle Nachbildung echter Informationen. Anstatt tatsächliche sensible Daten zu verwenden, bieten synthetische Daten eine sichere Alternative zum Testen, Trainieren von AI-Modellen oder Durchführen von Simulationen, ohne echte persönliche Daten preiszugeben.
Anwendungsgebiete von synthetischen Daten
Synthetische Daten finden ihre vielfältigen Anwendungen in verschiedensten Bereichen und für unterschiedliche Zwecke. Unternehmen, die auf echte Daten aufgrund der Gefahr von Datenpannen verzichten, wenden sich zunehmend synthetischen Daten zu, um die Erstellung fiktiver Datensätze zu beschleunigen. Hier sind einige wichtige Anwendungsgebiete:
- Datenschutz- und Sicherheitstests
- Training von Machine Learning Modellen
- Softwareentwicklung und -tests
- Gesundheitsanalyse
Synthetische Daten werden verwendet, um die Sicherheitssysteme von Organisationen zu bewerten, insbesondere in Sektoren wie Finanzen, Gesundheitswesen und Rechtswesen, ohne echte sensible Informationen preiszugeben.
Immer mehr Branchen nutzen synthetische Daten, um Machine Learning Modelle zu trainieren, ohne die Privatsphäre echter Daten zu gefährden.
Synthetische Daten sind in der Softwareentwicklung hilfreich, indem sie realistische Datensätze für die Erstellung und Bewertung von Anwendungen bereitstellen, insbesondere in Branchen wie Telekommunikation.
Synthetische Daten ermöglichen es Forschern und Datenwissenschaftlern, Studien und Experimente im Gesundheitswesen durchzuführen, ohne die Vertraulichkeit von Patienten zu verletzen.
DataSunrise Generierung synthetischer Daten
DataSunrise bietet eine Funktion zur Generierung synthetischer Daten, die echte Daten genau nachahmt. Sie kann für verschiedene geschäftliche Zwecke genutzt werden, von der Entwicklung und dem Testen bis hin zur Verbesserung von Machine Learning Algorithmen.
Beispielsweise, wenn es erforderlich ist, zufällige Daten von einem Verkaufsteam zu generieren, die E-Mails, Daten, Zeiten, Kreditkartennummern und IDs für statistische Analysen enthalten, können synthetische Daten verwendet werden, um die Privatsphäre zu schützen, insbesondere in Branchen, die mit sensiblen Informationen umgehen, wie Gesundheitswesen oder Finanzen.
Sie müssen neue Daten anstelle der vorhandenen generieren. Lassen Sie uns ein synthetisches Datenset mit DataSunrise erstellen.
Gehen Sie zu Konfiguration – Periodische Aufgaben. Klicken Sie auf +Neue Aufgabe.
Bild 1. Periodische Aufgaben
Im Unterabschnitt Allgemeine Einstellungen setzen Sie den Namen für Ihre periodische Aufgabe, wählen Sie den Aufgabentyp – Generierung synthetischer Daten – und auf welchem Server die Aufgabe gestartet werden soll. Im Unterabschnitt Generierung synthetischer Daten wählen Sie die Datenbankinstanz aus.
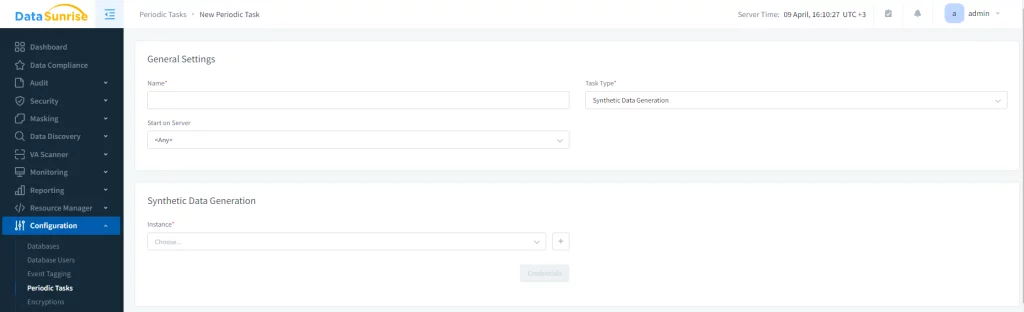
Bild 2. Allgemeine Einstellungen
Im Unterabschnitt Generierte Tabellen wählen Sie die erforderlichen Kontrollkästchen (wir haben nur das Kontrollkästchen für Leere Zieltabelle und Tabellengenerierung bei Fehler überspringen aktiviert).
Hier klicken Sie auf +Auswählen. Es öffnet sich ein Fenster, in dem Sie die benötigten Datenbankobjekte auswählen können. Wählen Sie eine Datenbank, ein Schema, eine Tabelle und eine Spalte aus, für die synthetische Daten generiert werden sollen. Nachdem alles ausgewählt ist, klicken Sie auf Speichern.
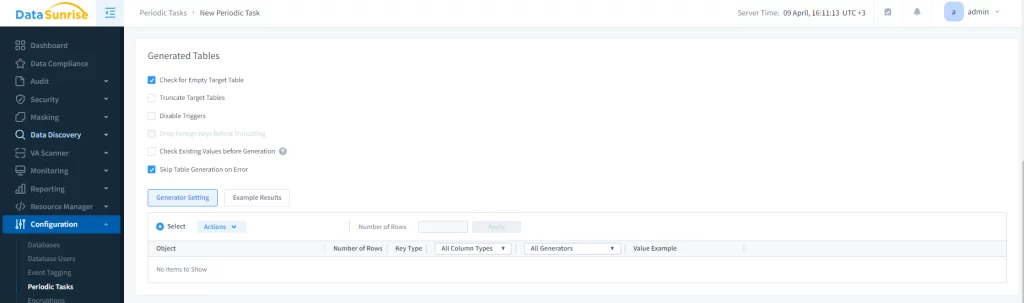
Bild 3. Auswahl der Datenbankobjekte
Anschließend sehen Sie die bereitgestellten Generatoren und Beispielfelder für jedes Objekt. In der Spalte Alle Generatoren können Sie den benötigten Generator auswählen oder erstellen.
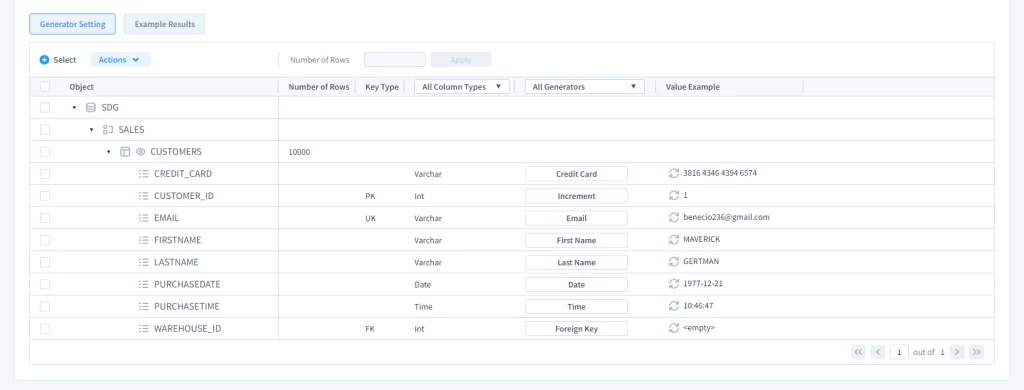
Bild 4. Auswahl von Daten-Generatoren
Im Abschnitt Beispielergebnisse sehen wir die Liste der generierten Daten. Nachdem alles erledigt ist, klicken Sie auf Anwenden oder Speichern.
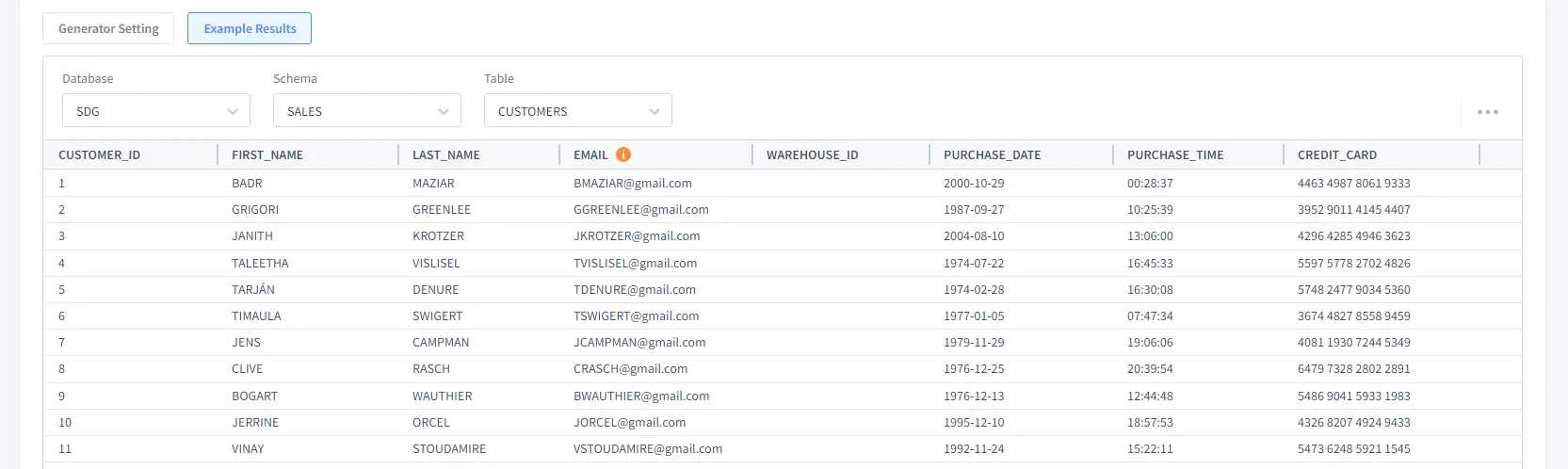
Bild 5. Beispiel für generierte Datensätze
Auch wenn Sie Ihren eigenen spezifischen Generator erstellen möchten, gehen Sie zu Konfiguration – Generatoren, und klicken Sie auf +Generator erstellen. Dort können Sie einen Generatortyp auswählen und dessen Parameter angeben. Klicken Sie auf Speichern und Sie können Ihren Generator in der Aufgabe zur Generierung synthetischer Daten anwenden.
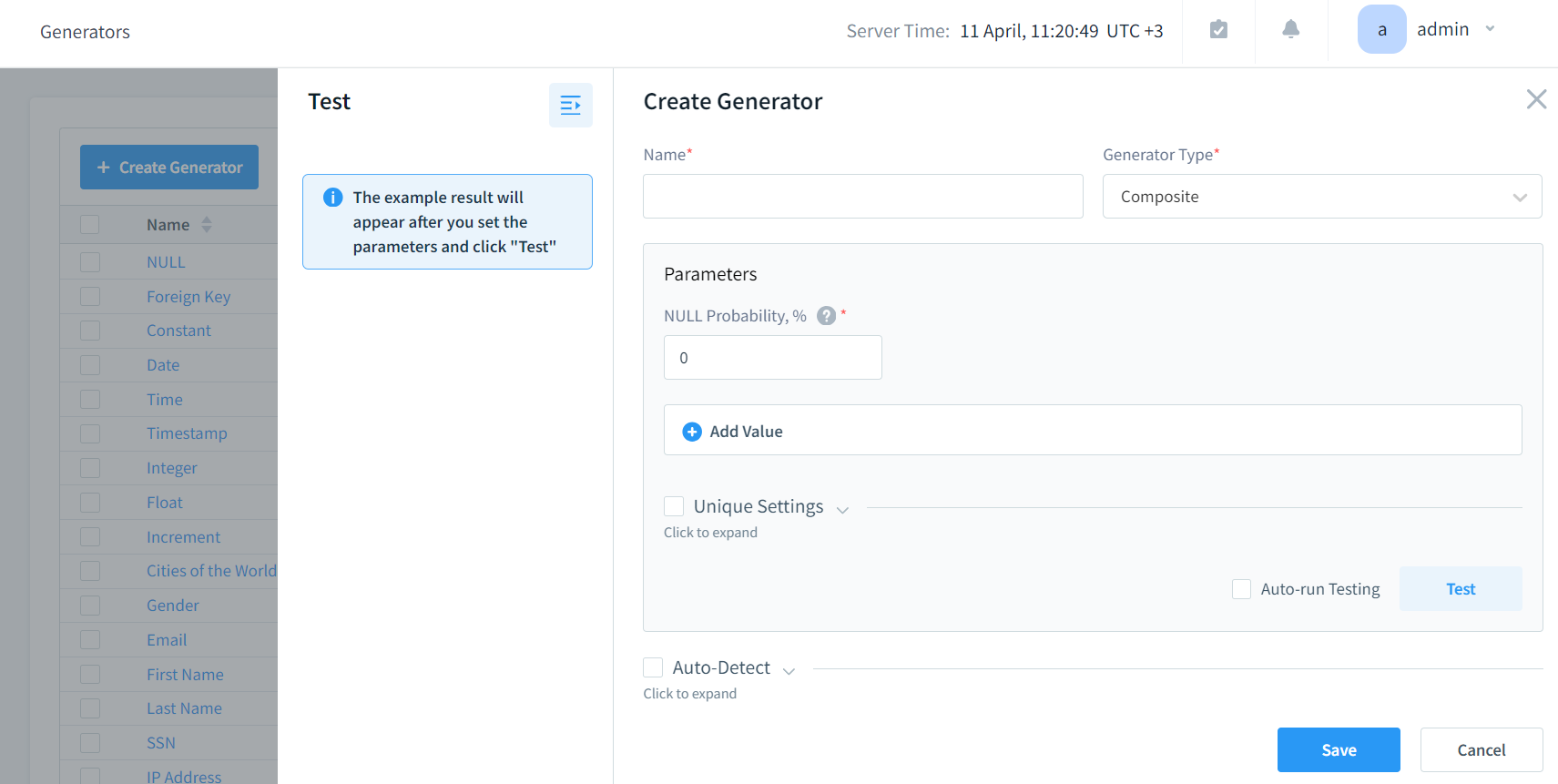
Bild 6. Generierung eines Generators
Die Generierung synthetischer Daten ist einfach und unkompliziert.
Fazit
DataSunrise vereinfacht diesen Prozess und ermöglicht die einfache Integration synthetischer Daten in verschiedene Arbeitsabläufe.
Darüber hinaus ist es wichtig zu beachten, dass, obwohl synthetische Daten viele Vorteile bieten, es entscheidend ist, deren Wirksamkeit und Zuverlässigkeit zu bestätigen. Organisationen sollten sicherstellen, dass die synthetischen Daten die echte Datenverteilung genau repräsentieren und die notwendigen Beziehungen und Abhängigkeiten beibehalten.
Die Generierung synthetischer Daten bietet eine wertvolle Lösung für Organisationen, die mit realistischen Daten arbeiten möchten, während sie gleichzeitig Datenschutz- und Sicherheitsbedenken berücksichtigen. Mit der Funktion zur Generierung synthetischer Daten von DataSunrise können Organisationen das Datenumfeld sicher navigieren und die Vorteile synthetischer Daten für ihre Geschäftsanforderungen nutzen.
