
Was ist Partitionierung?
Wenn Datenbanken in Größe und Komplexität wachsen, leiden oft Leistung und Wartbarkeit. Partitionierung bietet eine Lösung, indem große Datenbankobjekte – wie Tabellen und Indizes – in kleinere, handhabbare Segmente aufgeteilt werden. Diese Technik wird weit verbreitet eingesetzt, um die Abfrageausführung zu beschleunigen, Speicherbetriebskosten zu senken und das Datenlebenszyklusmanagement in Unternehmenssystemen und cloudbasierten Plattformen zu vereinfachen.
Die Hauptvorteile umfassen eine bessere Steuerbarkeit, Leistung und Verfügbarkeit. Dieser Ansatz ermöglicht es Administratoren, verschiedene Teile der Datenbank unabhängig voneinander zu optimieren und zu warten, was die Abfrageeffizienz und Systemverfügbarkeit verbessert und gezieltere Managementstrategien ermöglicht.
- In einigen Fällen verbessert diese Methode die Leistung beim Zugriff auf partitionierte Tabellen.
- Sie kann auch führende Spalten in Indizes definieren, wodurch die Größe der Indizes reduziert und der Arbeitsspeicherzugriff effizienter gestaltet wird. Wenn ein großer Teil eines Segments im Ergebnisset verwendet wird, ist das Scannen dieses Segments wesentlich schneller als das Scannen verstreuter Daten.
- Massives Hochladen und Löschen ist durch einfaches Hinzufügen oder Entfernen von Segmenten möglich, was die Leistung verbessert.
- Selten genutzte Informationen können in kostengünstigere Speichersysteme verschoben werden.
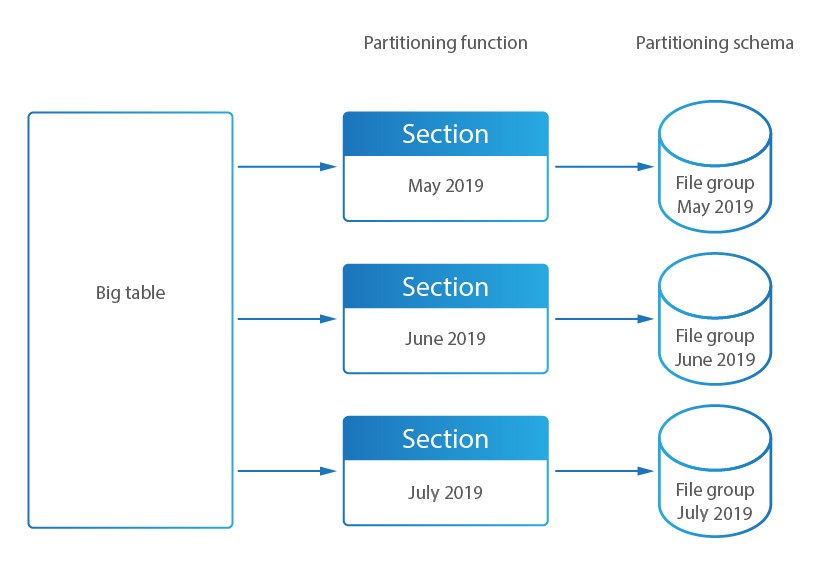
In DataSunrise werden große Audit-Speichertabellen in kleinere Segmente unterteilt, um den Zugriff und die Leistung zu verbessern. Das Database Activity Monitoring von DataSunrise speichert Ergebnisse direkt in dieser internen Datenbank.
- Administratoren können die Daten einfacher verwalten, indem sie sie in zeitbasierte Segmente aufteilen, die sie anschließend archivieren oder von Abfragen ausschließen können.
- Die Lese-/Schreibgeschwindigkeit verbessert sich signifikant beim Interagieren mit Speichertabellen.
- Das Löschen veralteter Audit-Protokolle wird schneller und effizienter.
DataSunrise unterstützt diese Technik für die folgenden Audit-Speicher-Datenbankplattformen:
- PostgreSQL
- MySQL
- MS SQL Server
Partitionierungsparameter
Zu finden in Systemeinstellungen -> Zusätzliche Parameter.
- Partitionslänge (Tage) – Definiert die Dauer jedes Segments (oder Minuten, wenn AuditPartitionShort = 1). Zu finden in Systemeinstellungen -> Audit Storage. Eine Änderung setzt die Struktur zurück: Bestehende Segmente werden entfernt und durch neue ersetzt.
- AuditPartitionCountCreatedInAdvance – Anzahl der vorab erstellten Partitionen. Diese leeren Bereiche ermöglichen ununterbrochenes Schreiben von Daten.
- AuditPartitionFirstEndDateTime – Legt die obere Zeitgrenze des ersten Segments fest. Nützlich, um Partitionen an einem klaren Zeitanker auszurichten (z. B. Montag 00:00:00).
Partitionierung für Compliance und Aufbewahrung
Viele Datenschutzbestimmungen verlangen die zeitnahe Löschung oder Archivierung sensibler Daten. Partitionierung erleichtert das Management von Datenlebenszyklen, indem ältere Datensätze in separate Segmente isoliert werden. Dies ermöglicht schnellere Löschvorgänge, einfachere Archivierung und verbesserte Prüfungsbereitschaft – insbesondere in Branchen, in denen strenge Aufbewahrungsrichtlinien gelten, wie Gesundheitswesen, Finanzen und Telekommunikation.
Partitionierung in modernen Datenumgebungen
In Big-Data-Umgebungen ist die Segmentierung von Daten entscheidend. Viele Cloud-Plattformen bieten inzwischen automatische Partitionierungsoptionen an. AWS Redshift verwendet Verteilungsstile für eine optimale Anordnung der Daten. Azure Synapse setzt Verteilungsmethoden ein, um die Abfrageleistung zu verbessern. Eine partitionierungsbasierte Logik funktioniert auch gut mit Data Lakes, die Petabytes an Informationen verarbeiten. Sie ermöglicht schnellere Abfragen in BI-Anwendungen und unterstützt einen zeitbasierten Zugriff auf historische oder archivierte Daten. Richtige Strategien helfen dabei, Speicherbetriebskosten zu senken und sich an Aufbewahrungsrichtlinien anzupassen.
Effektive Strategien zur Datenverteilung
Die Entwicklung effektiver Strategien zur Datenverteilung in Datenbanken erfordert eine sorgfältige Planung, die auf Zugriffsmustern und Geschäftsanforderungen basiert. Die Organisation nach Bereichen funktioniert am besten für aufeinanderfolgende Werte wie Daten, was es Teams ermöglicht, schnell auf aktuelle Daten zuzugreifen, während ältere Informationen archiviert werden.
Die Hash-Verteilung verteilt Daten gleichmäßig über die Speichersegmente, ideal für Lastverteilung in Umgebungen mit hoher gleichzeitiger Nutzung. Listenbasierte Ansätze organisieren Datensätze nach spezifischen kategorialen Werten, wodurch sie sich perfekt für geografische oder abteilungsbezogene Segmentierungen eignen.
Viele Organisationen implementieren hybride Methoden, die mehrere Verteilungstechniken kombinieren, um die Leistungsbenefits zu maximieren und gleichzeitig den Wartungsaufwand zu minimieren. Regelmäßige Analyse und Bereinigung stellen sicher, dass Abfragen konsistent nur die notwendigen Datensegmente ansprechen, um optimale Leistung bei wachsendem Datenvolumen zu gewährleisten.
Partitionierungsmanagement in DataSunrise
DataSunrise unterstützt automatisierte Datensegmentierung: Es erstellt die erforderlichen Tabellen (für PostgreSQL), pflegt aktuelle Funktionen, Schemata, Dateigruppen und Indizes (für MS SQL) und passt Schlüssel an, um mit nativen Partitionierungsmodellen (für MySQL) übereinzustimmen. DataSunrise verwaltet den gesamten Lebenszyklus der Segmente, von der Erstellung bis zur Bereinigung.
Das System führt SELECTs über die Haupttabelle aus, während es INSERT/UPDATEs an spezifische Segmente weiterleitet (außer bei MS SQL Server), was die Schreibperformance verbessert.
Namen der Partitionen und Tabellen
PostgreSQL erstellt Kindtabellen als Partitionen unter Verwendung des Formats <table_name>_p<datetime>, wobei <datetime> die obere Grenze im Format YYYYMMDDhhmm darstellt.
MySQL verwendet native Mechanismen zur Partitionierung. Es generiert Partitionsnamen unter Verwendung des Formats p<datetime>, wobei die gleiche Zeitstempelkonvention zur Anwendung kommt.
MS SQL Server wendet die Partitionierung mithilfe eines schemabasierten Ansatzes an, anstelle von Kindtabellen.
