Amazon Redshift Datenbank-Aktivitätsverlauf
Amazon Redshift betreibt groß angelegte analytische Arbeitslasten, doch seine operative Telemetrie ist bekanntermaßen fragmentiert. Abfrage-Spuren befinden sich in den STL_* Systemtabellen, Scan-Ebene-Details verstecken sich in den SVL_* Ansichten, und Sitzungs-Metadaten verteilen sich über mehrere Systemprotokolle. Keine dieser Komponenten liefert von Haus aus eine einheitliche Ausführungsdarstellung. Mit wachsender Cluster-Größe – einschließlich Autoskalierung, Concurrency Scaling und Multi-Warehouse-Betrieb – wird diese Fragmentierung zu einer echten Governance-Herausforderung. Laut der offiziellen AWS-Dokumentation zu Redshift-Systemtabellen wurden diese Protokolle nie dafür ausgelegt, als zentrales Aktivitätsprotokoll zu dienen, was die Notwendigkeit einer externen Konsolidierungsebene unterstreicht.
Ein zentrales Amazon Redshift Datenbank-Aktivitätsprotokoll löst dieses Problem, indem es Abfrageereignisse zu kohärenten Zeitachsen rekonstruiert. Es ermöglicht Sicherheitsteams, Dateningenieuren und Compliance-Prüfern, zu sehen, wie Arbeitslasten sich verhalten, auf welche Daten sie zugreifen, wer Änderungen initiiert und ob verdächtige Aktivitäten stattfinden. Plattformen wie DataSunrise erweitern diese Fähigkeit, indem sie native Protokolle mit Klassifizierung sensibler Daten und einheitlichen Überwachungsschichten anreichern (Database Activity Monitoring).
Dieser Artikel zerlegt Redshifts native Mechanismen für Aktivitätsverläufe, die Herausforderungen der verteilten AWS-Architektur und wie DataSunrise verstreute Protokolle zu einer einheitlichen, revisionssicheren Historie konsolidiert, die sich für Untersuchungen, Compliance und Echtzeit-Monitoring eignet. Für grundlegende Kontextinformationen zu Governance-Methoden können Sie auch auf unser Material zu Datenaktivitätsverlauf verweisen, da dieselben Prinzipien für analytische Architekturen gelten.
Indem DataSunrise Protokollfragmente auf Knotenebene mit Benutzeridentitäten, Objektsensitivität und Sicherheitslage korreliert, schließt es Sichtbarkeitslücken, die durch Redshifts native Subsysteme hinterlassen werden – ein Konzept, das in unserem Leitfaden zu Audit-Protokollen weiter vertieft wird.
Bedeutung des Datenbank-Aktivitätsverlaufs
Der Datenbank-Aktivitätsverlauf wird in modernen Redshift-Implementierungen, in denen mehrere Arbeitslasten, gemeinsame Schemata und verteilte Teams gleichzeitig tätig sind, unverzichtbar. Historische Sichtbarkeit stellt operative Verantwortlichkeit sicher, reduziert Unsicherheiten bei Vorfalluntersuchungen und liefert den Kontext für prüfungsfähige Beweise.
Zentrale Nutzenpunkte sind:
- Zuverlässige forensische Rekonstruktion, unverzichtbar zum Verstehen von systemweiten Auswirkungen bei Ausfällen oder Anomalien.
- Verifizierung der Legitimität des Datenzugriffs, Klarheit darüber, wer wann mit sensiblen Datensätzen interagiert hat.
- Erkennung subtiler Abweichungen bei Arbeitslasten, die auf Konfigurationsabweichungen oder frühe Kompromittierungsanzeichen hinweisen können.
- Übereinstimmung mit Compliance-Rahmenwerken, bei denen historische Zugriffsmuster beweisbar und reproduzierbar sein müssen.
- Konsistenz über Multi-Cluster-Architekturen hinweg, gewährleistet zentrale Sichtbarkeit über das hinaus, was Redshift nativ darstellt.
Eine ausgereifte Fähigkeit zum Aktivitätsverlauf transformiert Redshift von einer schnellen Analyseplattform zu einer vollständig gesteuerten, betrieblich transparenten Datenplattform.
Native Redshift-Quellen für den Aktivitätsverlauf
Amazon Redshift stellt aktivitätsbezogene Informationen über mehrere niedrigstufige Protokolle und Systemtabellen bereit. Jede Struktur bietet eine Teilansicht des Abfrageverhaltens, jedoch keine vollständige Korrelation.
1. STL-Systemtabellen
STL-Systemtabellen bilden die grundlegende Telemetrieebene in Amazon Redshift. Sie speichern Ereignisse auf Knoten-Ebene, das heißt, die Datenbank zeichnet auf, was jeder Compute-Slice getan hat, aber nicht, wie die gesamte Abfrage als Ganzes lief. Dies ist mächtig für niedrigstufige Diagnosen, jedoch inhärent fragmentiert.
Wichtige STL-Tabellen umfassen:
stl_query— SQL-Text, Zeitstempel, Ausführungsdauer, Abbruchstatus.stl_connection_log— Authentifizierungsversuche und Sitzungslebenszyklus-Ereignisse.stl_insert/stl_update/stl_delete— DML-Operationen, die Tabellendaten verändern.stl_ddltext— alle DDL-Ereignisse einschließlich CREATE, ALTER, DROP.Weitere nützliche Tabellen:
stl_querytext— kompletter SQL-Text über mehrere Zeilenstl_wlm_query— WLM-Warteschlangenplatzierung und Performancestl_error— Laufzeitfehler und Fehlerdiagnosen
Diese Tabellen bilden zusammen ab, wie Redshift eine Abfrage lokal auf jedem Knoten ausgeführt hat, jedoch nicht, wie die Knoten miteinander in einer einheitlichen Weise interagierten.
Beispiel: Abrufen der letzten Abfragen
SELECT
query,
userid,
starttime,
endtime,
substring,
aborted
FROM stl_query
ORDER BY starttime DESC
LIMIT 30;
Beispiel: Rekonstruktion des vollständigen SQL-Texts
SELECT
q.query,
LISTAGG(t.text, '') WITHIN GROUP (ORDER BY t.sequence) AS full_sql
FROM stl_query q
JOIN stl_querytext t
ON q.query = t.query
WHERE q.userid <> 1 -- Systemabfragen herausfiltern
GROUP BY q.query
ORDER BY q.starttime DESC
LIMIT 10;
2. SVL virtuelle Log-Ansichten
SVL-Ansichten aggregieren STL-Protokolle und bieten eine höherstufige Ansicht darüber, wie die Abfrage tatsächlich gelaufen ist. Betrachten Sie sie als von Redshift erstellte „Ausführungsübersichten“, denen jedoch weiterhin eine ereignisübergreifende Korrelation fehlt.
Kern-SVL-Objekte umfassen:
svl_qlog— Abfragelebenszyklusmetriken (Start, Ende, Zuweisung, Abschluss).svl_scan— Metriken zu Tabellenscans, verarbeitete Zeilen, gescannte Bytes, Scan-Typ.svl_statementtext— normalisierte SQL-Darstellung zur Musteranalyse.Weitere relevante Ansichten:
svl_hash— Details zu Hash Join-Operationensvl_s3query— Aktivität, die durch Redshift Spectrum erzeugt wird
Diese Ansichten helfen Teams zu verstehen, wie Redshift Abfragen physisch verarbeitet hat, bilden jedoch keine vollständige Aktivitätszeitlinie über Sessions, Nutzer und Arbeitslasten hinweg.
Beispiel: Scan-Introspektion
SELECT
q.query,
q.userid,
s.tbl AS table_id,
s.rows,
s.bytes,
s.is_rrscan AS redistribution_required,
q.starttime
FROM svl_qlog q
JOIN svl_scan s
ON q.query = s.query
ORDER BY q.starttime DESC
LIMIT 20;
Beispiel: Abrufen normalisierten Anweisungstexts
SELECT
query,
sequence,
text
FROM svl_statementtext
WHERE query = <QUERY_ID>
ORDER BY sequence;
3. System-Level- und externe Protokolle
Der Überwachungsstack von Redshift wird durch Systemprotokolle und AWS-verwaltete Logging-Kanäle ergänzt. Diese Protokolle liefern Kontext, den STL/SVL-Tabellen alleine nicht bieten können:
- CloudWatch Audit Streams — Erfasst Abfragen, Verbindungsversuche und Fehler in einem zentralen Protokolldienst.
- WLM-Warteschlangenprotokolle — Verfolgt Warteschlangen-Zuweisungen, Wartezeiten, Gleichzeitigkeitseinschränkungen und Slot-Auslastung.
- Redshift Data API-Protokolle — Wichtig für serverlose Workflows und anwendungsgetriebene SQL-Ausführung.
- Spectrum-Protokolle — Sichtbarkeit in externe Tabellen-Lesevorgänge und Verarbeitung auf S3-Basis.
Diese Quellen liefern wichtige Metadaten, aber die manuelle Verknüpfung mit STL/SVL bleibt erforderlich.
Beispiel: WLM-Performance-Analyse
SELECT
service_class,
query,
total_queue_time,
total_exec_time,
wlm_start_time,
wlm_end_time
FROM stl_wlm_query
ORDER BY wlm_start_time DESC
LIMIT 25;
Beispiel: Aktuelle Ausführungsfehler anzeigen
SELECT
query,
userid,
starttime,
endtime,
result,
TRIM(error) AS error_message
FROM stl_error
ORDER BY starttime DESC
LIMIT 20;
Beispiel: CloudWatch Insights – Redshift Audit-Abfragen
fields @timestamp, @message
| filter @message like /Connection|Query|Error/
| sort @timestamp desc
| limit 50
Wie DataSunrise einen vollständigen Redshift-Datenbank-Aktivitätsverlauf erstellt
DataSunrise beseitigt Redshifts native Fragmentierung, indem es einen ganzheitlichen, normalisierten und compliance-fähigen Aktivitätsverlauf erzeugt. Anstatt niedrigstufige Protokolle zusammenzufügen, erhalten Organisationen eine einzelne, kohärente betriebliche Erzählung, angereichert mit Risikokontext, Sensitivitätsbewusstsein und Benutzerzuordnung.
DataSunrise bietet dies durch:
1. Reverse-Proxy-Korrelations-Engine
Der DataSunrise Reverse Proxy wird zum einzigen autoritativen Beobachtungspunkt für sämtlichen SQL-Verkehr, der auf Amazon Redshift zielt. Da jede Abfrage durch den Proxy fließt, erfasst die Plattform Kontextinformationen, die Redshifts native Protokolle niemals sehen, wie Anwendungserkennung, Client-IP-Herkunft und verhaltensübergreifende Muster. SQL wird normalisiert, tokenisiert, mit Sensitivitätsmetadaten angereichert und mit Ausführungskontext korreliert, bevor ein Datensatz geschrieben wird.
Das Ergebnis sind vollständig deterministische Audit-Einträge – nicht die knotenverteilten Fragmente, die STL/SVL produzieren –, sondern vollständige, benutzerzugeordnete Aktionen, die sich für forensische Rekonstruktion und Compliance-Berichte eignen.
Für eine tiefere Betrachtung der zentralisierten Überwachungsprinzipien siehe:
→ Database Activity Monitoring
2. Zentralisierte Aktivitätszeitachse
DataSunrise fasst die ansonsten zersplitterten Signale von Redshift zu einer globalen, chronologisch geordneten Zeitachse zusammen. Anstatt STL-Protokolle, WLM-Datensätze und CloudWatch-Einträge manuell zusammenzufügen, synthetisiert die Plattform alles zu einer einheitlichen historischen Erzählung. Dazu gehören Authentifizierungsversuche, DML/DDL-Ereignisse, sensibler Objektzugriff, Richtlinienübereinstimmungen und Sicherheitswarnungen.
Das System korrigiert Zeitstempelabweichungen, inkonsistente lokale Ausführungen auf Knoten und fragmentierte Ereignismodelle – und erzeugt eine zusammenhängende Geschichte darüber, wie Nutzer und Anwendungen Redshift über die Zeit interagieren.
Mehr über strukturierte Historie finden Sie hier:
→ Datenaktivitätsverlauf
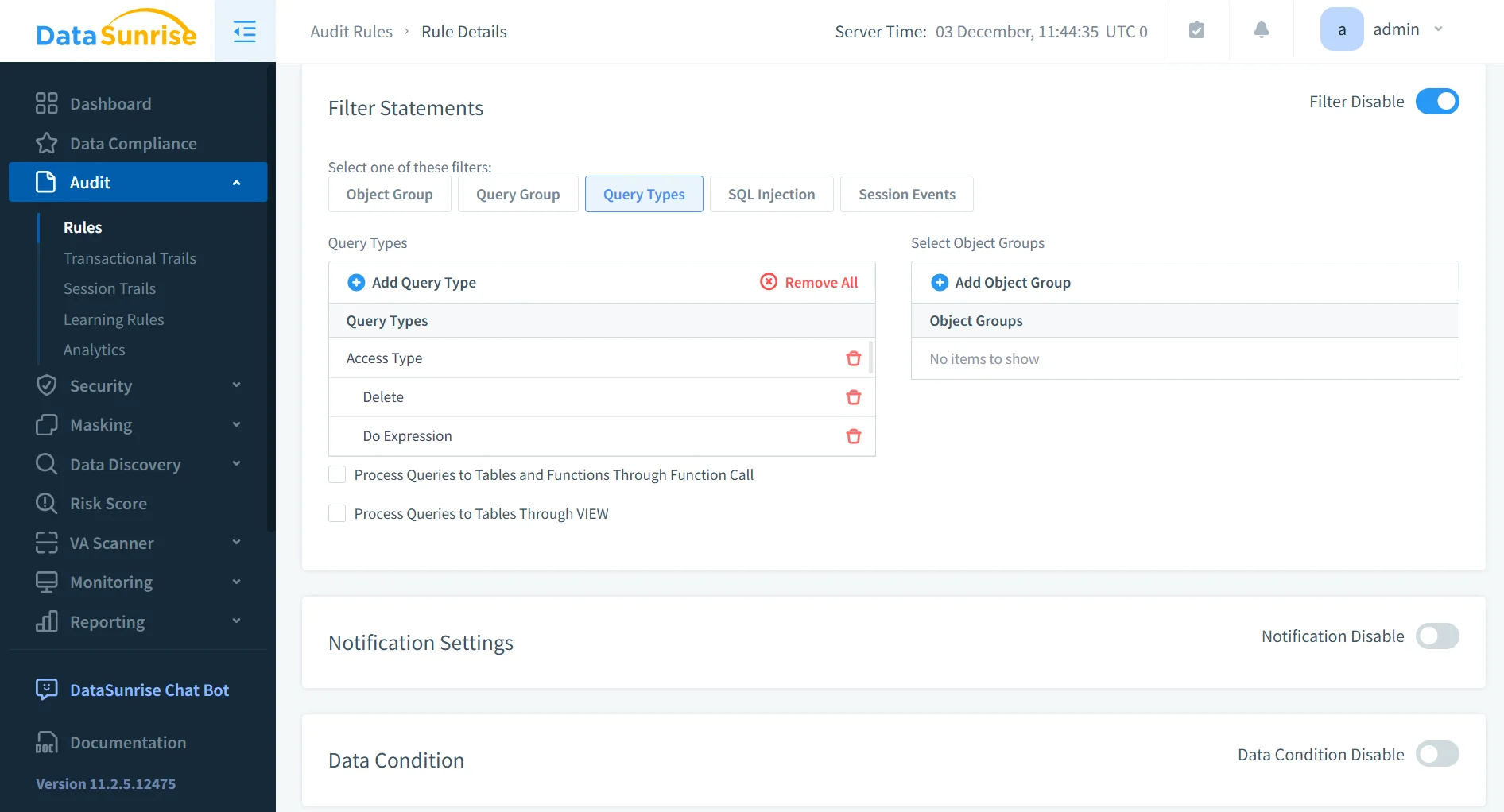
3. Granulare, regelbasierte Überwachung
DataSunrise erlaubt Administratoren, präzise gefasste Audit-Regeln anzuwenden, die einzelne Schemata, sensible Felder, risikoreiche Benutzer oder spezifische Operationen gezielt erfassen. Das minimiert Rauschen, reduziert Speicherbedarf und stellt sicher, dass Compliance-Teams sich nur auf relevante Ereignisse konzentrieren.
Regeln können an regulatorische Anforderungen, interne Governance-Richtlinien oder dynamische Risiko-Bewertungen gebunden sein. In Kombination mit automatischer Sensitivitäts-Erkennung entsteht ein maßgeschneiderter Audit-Fussabdruck, der mit der organisatorischen Komplexität skaliert.
Für einen Überblick über flexible Regelmodelle siehe:
→ Audit-Protokolle
4. Echtzeit-Erkennung von Bedrohungen und Verhaltensmustern
Traditionelles Redshift-Logging reagiert nach der Abfrageausführung, wodurch Sicherheitsteams bei aufkommenden Bedrohungen blind bleiben. DataSunrise führt Echtzeit-UEBA-ähnliche Verhaltensanalytik ein, die kontinuierlich lernt, wie legitime Arbeitslasten normalerweise funktionieren. Abweichungen – wie unerwartete Tabellenscans, plötzliche Rechteerhöhungen, Massen-Datenauszüge oder anomale Joins – lösen sofortige Alarme aus.
Diese proaktive Sicherheitsschicht erkennt Aktivitätsmuster, die native Redshift-Tools nicht interpretieren können, und schließt damit eine bedeutende Sicherheitslücke im Cloud-Datenlager.
Verhaltensintelligenz im Detail:
→ User Behavior Analysis
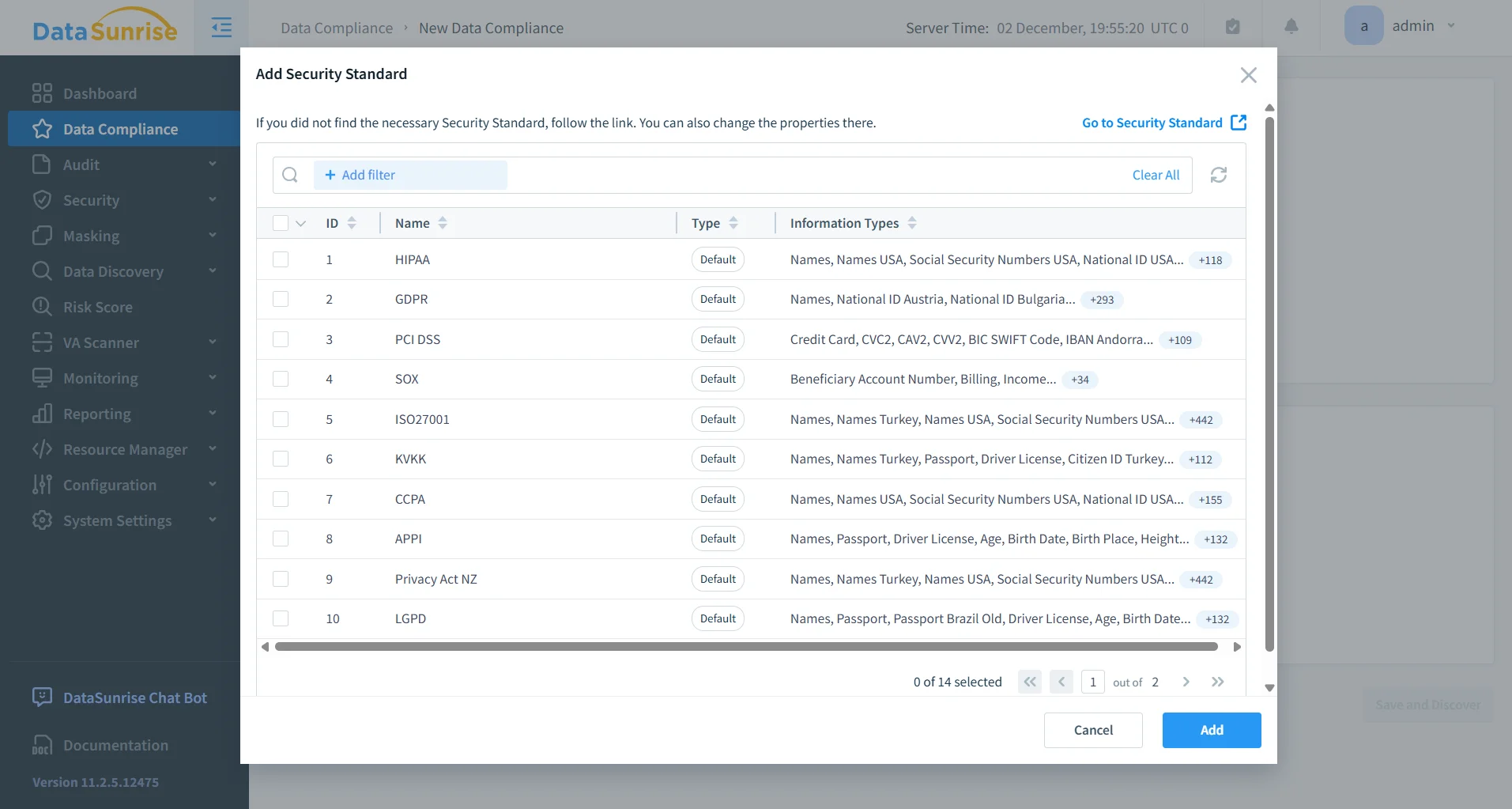
5. Compliance-fähige Prüfpfade
DataSunrise wandelt Redshifts niedrigstufige Betriebsprotokolle in auditkonforme Prüfpfade um, die mit großen Compliance-Standards übereinstimmen. Ereignisse werden unveränderlich gespeichert, global über Cluster korreliert und mit Kontext wie Sensitivitätsstufe, Benutzerrolle und Richtlinienrelevanz angereichert.
Organisationen erhalten die Möglichkeit, Prüfanforderungen mühelos zu erfüllen, zeitlich abgestimmte Beweise zu erzeugen und strenge Governance-Kontrollen über alle Redshift-Arbeitslasten hinweg zu demonstrieren – etwas, das Redshifts native Telemetrie allein nicht leisten kann.
Automatisierte Compliance-Integration finden Sie hier:
→ Compliance Manager
Wesentliche Vorteile von DataSunrise
| Vorteil | Beschreibung |
|---|---|
| Einheitliche Aktivitätszeitachse | Eliminiert Redshifts fragmentierte STL/SVL-Protokolle durch Korrelation aller SQL-, Authentifizierungs- und Metadatenereignisse zu einer einzigen chronologischen Historie. |
| Tiefe Sichtbarkeit in sensiblen Datenzugriff | Identifiziert, welche Abfragen regulierte oder risikoreiche Daten abgerufen haben, unterstützt durch Klassifizierungsmetadaten. |
| Verhaltensanalytik & Bedrohungserkennung | ML-gesteuerte Anomalieerkennung markiert Abweichungen vom typischen Arbeitslast- und Benutzerverhalten. |
| Granulare Audit-Kontrollen | Regeln können gezielt bestimmte Objekte, Rollen, Operationen oder Compliance-Rahmenwerke ansprechen, reduzieren Störsignale und fokussieren auf kritische Aktivitäten. |
| Langfristige Aufbewahrung & Unveränderlichkeit | Bewahrt Prüfprotokolle weit über das STL-Aufbewahrungsfenster hinaus in manipulationssicherem Speicher auf. |
| Clusterübergreifende Korrelation | Normalisiert Aktivitäten aus mehreren Redshift-Clustern, Serverless-Endpunkten und hybriden Architekturen in einer einheitlichen Governance-Ebene. |
| Abbildung von Compliance-Rahmenwerken | Annotiert automatisch Ereignisse hinsichtlich der Relevanz für SOX, HIPAA, PCI DSS, GDPR und interne Governance-Richtlinien. |
| Exportfertige Berichte | Erzeugt prüferfähige Exporte in CSV-, JSON- und PDF-Formaten ohne manuelles Zusammenfügen von Protokollen. |
Fazit
Amazon Redshift liefert grundlegende Telemetrie, doch seine verteilte Architektur, lokal auf Knoten gespeicherte Logs und verstreute Systemtabellen erschweren die Rekonstruktion eines kohärenten Aktivitätsverlaufs in großem Maßstab. Das native Modell zwingt Ingenieure dazu, STL/SVL-Einträge, CloudWatch-Ströme und WLM-Protokolle manuell zu korrelieren – von denen jeder nur Fragmente des vollständigen Ausführungsbilds darstellt. Dadurch fällt es Organisationen schwer, Sichtbarkeit zu erlangen, die chronologisch, vollständig, sensiblen Daten bewusst und mit formalen Compliance-Rahmen abgestimmt ist. Ohne eine einheitliche Aktivitätszeitachse erfordern kritische Aufgaben wie Vorfallrekonstruktion, Erkennung von Insider-Bedrohungen und Governance sensibler Objekte erheblichen manuellen Aufwand und sind anfällig für Lücken.
DataSunrise beseitigt diese Einschränkungen, indem es alle Redshift-Ereignisse aggregiert, normalisiert und anreichert zu einer einzigen, gesteuerten Audit-Spur. Die Proxy-Architektur erfasst kontextuelle Metadaten, die Redshift nie offenlegt – einschließlich Anwendungsidentität, Verhaltensbaselines, Zugriffsrisikobewertung und clusterübergreifender Korrelation. Die Plattform integriert Sensitivitätsentdeckung, automatisierte Richtliniendurchsetzung und dynamisches Monitoring, um sicherzustellen, dass jede Aktion zugeordnet, geordnet und in Echtzeit bewertbar ist. Kombiniert mit machine-learning-gestützter Anomalieerkennung verwandelt DataSunrise Redshift in ein betrieblich transparentes System, das für regulierte Branchen, langfristige Audit-Aufbewahrung und unternehmenskritische Daten-Governance geeignet ist.
Für erweiterte Einsichten in strukturierte Audit-Pipelines siehe die Kernarchitektur unter
→ Audit Trails
Für Einblicke in objekt- und sitzungsbezogene Muster verweisen wir auf
→ Datenbank-Aktivitätsverlauf
Zur Klassifizierung und Behandlung regulierter Informationen empfehlen wir
→ PII & Sensitive Data Übersicht
Zur Compliance-Ausrichtung und automatischer Evidenzgenerierung siehe
→ DataSunrise Compliance Manager
