
Clusterdaten: Wie sie funktionieren & wie man sie anwendet

Clusterdaten sind eine leistungsstarke Technik, die hilft, verborgene Muster und Trends in großen Datensätzen aufzudecken. Sie gruppieren ähnliche Objekte, wodurch es einfacher wird, komplexe Informationen zu analysieren und zu verstehen. Datenwissenschaftler nutzen die Clusterung, um schnell Themen zu identifizieren, Anomalien zu erkennen und wertvolle Einblicke aus riesigen Datenmengen zu gewinnen.
Was ist Daten-Clustering?
Im Kern ist Daten-Clustering eine Methode des unüberwachten maschinellen Lernens. Es erfordert keine gekennzeichneten Daten oder vordefinierte Kategorien. Stattdessen findet der Algorithmus natürliche Gruppierungen innerhalb des Datensatzes basierend auf Ähnlichkeit. Wir ordnen ähnliche Objekte in dieselbe Gruppe ein und trennen unterschiedliche Objekte.
Der Prozess ist flexibel und kann mit verschiedenen Arten von Daten arbeiten:
- Dokumente
- Punkte in einem Diagramm
- Umfrageantworten
- Genetische Sequenzen
Solange es eine Möglichkeit gibt, die Ähnlichkeit zwischen zwei Objekten zu messen, kann Clustering angewendet werden. Diese Vielfalt macht es zu einem bevorzugten Werkzeug für explorative Datenanalysen in verschiedenen Branchen.
Datencluster-Analyse in Aktion
Stellen Sie sich vor, Sie betreiben eine E-Commerce-Website mit tausenden von Produkten. Sie möchten das Kundenverhalten besser verstehen und personalisierte Empfehlungen anbieten. Durch die Clusterung Ihrer Produktdaten könnten Sie interessante Gruppen entdecken:
- Bestseller, die häufig zusammen gekauft werden
- Nischenartikel, die spezifische Zielgruppen ansprechen
- Saisonale Trends rund um Feiertage oder Ereignisse
Diese Erkenntnisse können Marketingstrategien, Bestandsverwaltung und Webseitengestaltung beeinflussen. Sie können beliebte Produktbündel hervorheben, E-Mail-Kampagnen auf Kundensegmente zuschneiden und die Navigation basierend auf dem Surfverhalten optimieren.
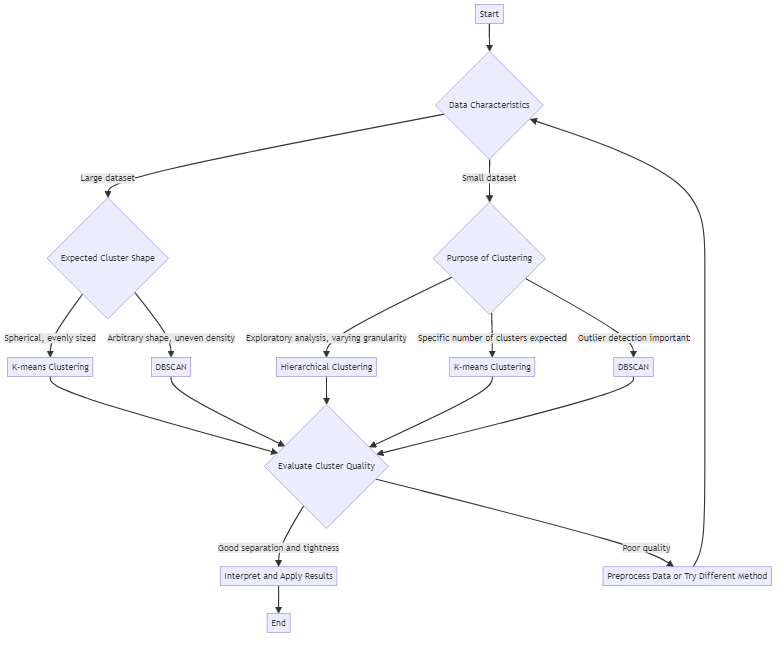
Den richtigen Clustering-Algorithmus wählen
Verschiedene Clustering-Algorithmen eignen sich für unterschiedliche Zwecke. Zu den gebräuchlichen gehören:
- K-means: Teilt Daten in eine vordefinierte Anzahl (k) von Datenclustern auf. Funktioniert gut, wenn man eine Vorstellung davon hat, wie viele Gruppen zu erwarten sind.
- Hierarchische Clusterung: Erstellt verschachtelte Datencluster in einer baumartigen Struktur. Nützlich zur Visualisierung von Daten auf unterschiedlichen Granularitätsstufen.
- DBSCAN: Identifiziert Cluster beliebiger Form und markiert Ausreißer. Geeignet für Datensätze mit Rauschen und ungleichmäßiger Dichte.
Die richtige Wahl hängt von Faktoren wie der Datenmenge, der erwarteten Clusterform und der Toleranz für Ausreißer ab. Es lohnt sich oft, mehrere Ansätze auszuprobieren, um zu sehen, welcher die bedeutungsvollsten Ergebnisse liefert.
Bewertung der Datencluster-Qualität
Nicht alle Cluster sind gleich. Ein gutes Clustering-Ergebnis zeichnet sich durch enge, gut getrennte Gruppen aus. Objekte innerhalb eines Clusters sollten hochgradig ähnlich sein, während Objekte in verschiedenen Clustern deutlich voneinander abweichen sollten. Silhouettenwerte und Visualisierungstechniken können helfen, die Qualität von Datenclustern zu bewerten.
Die Validierung von Clustern anhand von Fachwissen ist entscheidend, um die Genauigkeit und Relevanz der Clustering-Ergebnisse sicherzustellen. Wir können prüfen, ob die Cluster mit Expertenmeinungen oder Geschäftszielen übereinstimmen. Dies hilft uns festzustellen, ob sie für den spezifischen Fachbereich oder die Branche geeignet sind. Dieser Validierungsprozess trägt dazu bei, zu bestätigen, dass die Cluster aussagekräftig und für Entscheidungsfindungen nützlich sind.
Clustering hilft dabei, Muster in Daten zu finden, aber es ist erst der Anfang. Menschen müssen die Ergebnisse des Clusterings interpretieren, um umsetzbare Erkenntnisse zu gewinnen und fundierte Entscheidungen zu treffen. Durch den Einsatz von Zahlen und Expertenmeinungen können wir die Daten und deren Auswirkungen auf das Geschäft besser verstehen.
Zusammenfassend sind die Validierung von Clustern anhand von Fachwissen und die Interpretation der Ergebnisse wesentliche Schritte im Clustering-Prozess. Indem wir Wissen und Urteilsvermögen in einem bestimmten Bereich einsetzen, stellen wir sicher, dass die Gruppen nützlich und praxisorientiert sind. Dies wird letztendlich zum Erfolg des Unternehmens beitragen.
Anwendungen von Clusterdaten
Die Anwendungsfälle für Clusterdaten reichen über verschiedene Bereiche:
- Kundensegmentierung für zielgerichtetes Marketing
- Anomalieerkennung in der Betrugsprävention
- Bildkompression und Mustererkennung
- Bioinformatik und Genexpressionsanalyse
- Analyse von sozialen Netzwerken und Gemeinschaftserkennung
Wo immer komplexe Daten zu entwirren sind, bietet Clustering einen wertvollen Ausgangspunkt. Es vereinfacht die Datenlandschaft und bringt Schlüsselaspekte zur weiteren Untersuchung zutage.
Best Practices für Clusterdaten
Um das Beste aus Clusterdaten herauszuholen, sollten Sie diese Tipps beachten:
- Daten vorverarbeiten und normalisieren, um faire Vergleiche zu gewährleisten
- Mit verschiedenen Distanzmetriken und Algorithmen experimentieren
- Ergebnisse anhand statistischer Maßnahmen und Fachwissen validieren
- Datencluster visualisieren, um Erkenntnisse effektiv zu vermitteln
- Den Prozess iterativ verfeinern, sobald neue Daten verfügbar werden
Mit der richtigen Implementierung können Clusterdaten den entscheidenden Unterschied machen. Sie verwandeln überwältigende Datensätze in umsetzbare Erkenntnisse und befähigen Organisationen, klügere Entscheidungen zu treffen.
Clusterdaten im Einsatz
Nutzen Sie die Kraft Ihrer Daten mit Clustering. Die Clusteranalyse ist ein entscheidendes Werkzeug für Marketer, Forscher und Datenwissenschaftler. Sie hilft Ihnen, Einblicke in das Kundenverhalten zu gewinnen, Gen-Netzwerke zu erforschen und komplexe Probleme zu lösen. Beginnen Sie noch heute, die Welt der Daten-Clusterung zu erkunden und verborgene Muster zu entdecken.
