Wie man Databricks SQL auditieren kann
Die Auditierung von Databricks SQL ist keine reine Abhakübung; deshalb ist es wichtig, wie man Databricks SQL richtig auditieren kann in realen Lakehouse-Umgebungen zu lernen. In realen Lakehouse-Umgebungen wird Databricks SQL häufig zu einer gemeinsamen analytischen Oberfläche für Dutzende von Teams, automatisierten Pipelines und externen BI-Tools. Daher müssen Organisationen Auditing als einen kontinuierlichen Prozess statt als einmalige Konfiguration gestalten.
Dieser Leitfaden erklärt, wie man Databricks SQL richtig auditieren kann: beginnend mit der nativen Sichtbarkeit, der Identifizierung der Grenzen und anschließend der Implementierung eines strukturierten, untersuchungsbereiten Audit-Workflows mit DataSunrise. Der Fokus liegt auf praktischen Entscheidungen, Kontrollpunkten und der Qualität der Beweise statt auf theoretischen Definitionen.
Was Auditing in Databricks SQL bedeutet
Auditierung von Databricks SQL bedeutet, verlässliche und überprüfbare Beweise darüber zu führen, wie das SQL-Warehouse verwendet wird. Dies beinhaltet die Nachverfolgung, wer Abfragen ausgeführt hat, welche Operationen durchgeführt wurden, wann diese stattfanden und ob diese Aktionen den internen Richtlinien und gesetzlichen Anforderungen entsprachen.
In der Praxis muss die Auditierung operationelle und forensische Fragen beantworten, wie z.B.:
- Wer hat auf sensible Tabellen zugegriffen und mit welchen Tools?
- Wurden Datenänderungen erwartet und autorisiert?
- Lässt sich die Ausführungsreihenfolge der Abfragen bei einer Untersuchung rekonstruieren?
- Ist der Prüfungsnachweis vor Manipulationen geschützt und korrekt aufbewahrt?
Ohne klare Antworten auf diese Fragen sind Audit-Daten von geringem praktischem Nutzen. Im Laufe der Zeit kombinieren erfahrene Teams diesen Ansatz mit Database Activity Monitoring, um Untersuchungen und Compliance-Prüfungen über Umgebungen hinweg konsistent zu halten.
Schritt 1: Native Audit-Funktionalitäten von Databricks SQL überprüfen
Databricks SQL stellt eine native Abfragehistorie bereit, die ausgeführte Statements zusammen mit Zeitstempeln, Dauer und Ausführungsstatus anzeigt. Administratoren verlassen sich häufig auf diese Schnittstelle für kurzfristige Fehlersuche und operative Übersicht.
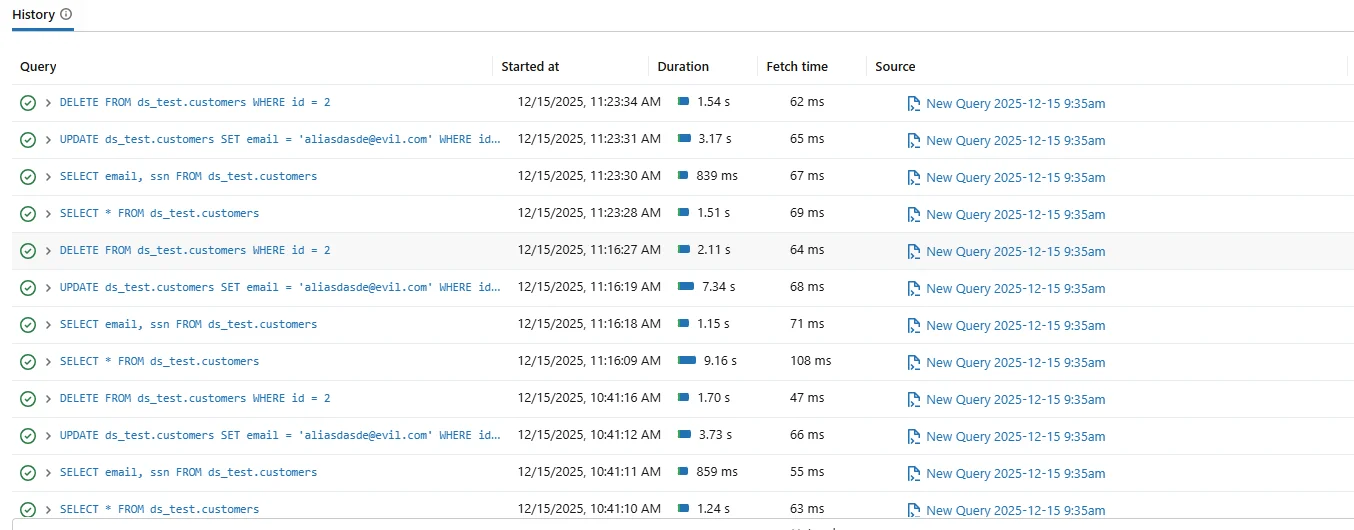
Native Databricks SQL-Abfragehistorie, verwendet für einfache operative Auditierungen.
Obwohl die native Abfragehistorie nützlich ist, wurde sie nicht für formale Audits entwickelt. Die Aufbewahrung ist begrenzt, die Sitzungs-Korrelation schwach und die Integrität der Beweise nicht garantiert.
Um die Aufbewahrung zu verlängern, exportieren Teams häufig Protokolle in externe Plattformen wie Azure Log Analytics oder Amazon CloudWatch. Diese Systeme erfordern jedoch weiterhin erheblichen manuellen Aufwand, um Sitzungen zu korrelieren und Zeitlinien wiederherzustellen. Für eine strukturierte Beweissammlung verlassen sich viele Organisationen auf dedizierte Audit-Logs, die konsistente Metadaten über Benutzer und Workloads aufbewahren.
Schritt 2: Auditscope definieren, bevor Daten gesammelt werden
Einer der häufigsten Fehler bei der Auditierung ist, alles ohne Scope-Definition zu erfassen. Übermäßiges Logging erzeugt Rauschen und verlangsamt Untersuchungen.
| Audit-Dimension | Schlüsselfragen |
|---|---|
| Benutzeraktivität | Welche Benutzer und Servicekonten haben Abfragen ausgeführt? |
| Abfragetypen | Wurden SELECT, UPDATE oder DELETE Aussagen ausgeführt? |
| Datenobjekte | Auf welche Schemata und Tabellen wurde zugegriffen? |
| Ausführungsreihenfolge | Lassen sich Aktionen chronologisch rekonstruieren? |
Schritt 3: Die Audit-Architektur verstehen
Effektive Auditierung folgt einer geschichteten Architektur. SQL-Abfragen stammen von Benutzern, BI-Tools und Anwendungen, werden im Databricks SQL-Warehouse ausgeführt und erzeugen auditrelevante Ereignisse.

Audit-Architektur zeigt Erfassung, Zentralisierung und Analyse der Databricks SQL-Aktivitäten.
Die entscheidende Designfrage ist, wo die Ereignisse erfasst werden. Das native Logging zeichnet Ereignisse lokal auf, während zentralisierte Audit-Plattformen die Ereignisse in Echtzeit erfassen, normalisieren und speichern. In der Praxis kombinieren Teams zentrale Speicherung mit Datenbanksicherheitskontrollen, um Audit-Lücken zu reduzieren und Untersuchungen zu beschleunigen.
Schritt 4: Auditierung mit DataSunrise zentralisieren
DataSunrise auditert Databricks SQL, indem es SQL-Aktivitäten in Echtzeit erfasst und in einem zentralen Audit-Repository speichert. Anstatt sich auf fragmentierte Logs zu verlassen, erstellt es strukturierte Audit-Einträge, angereichert mit Sitzungs-Kontext.
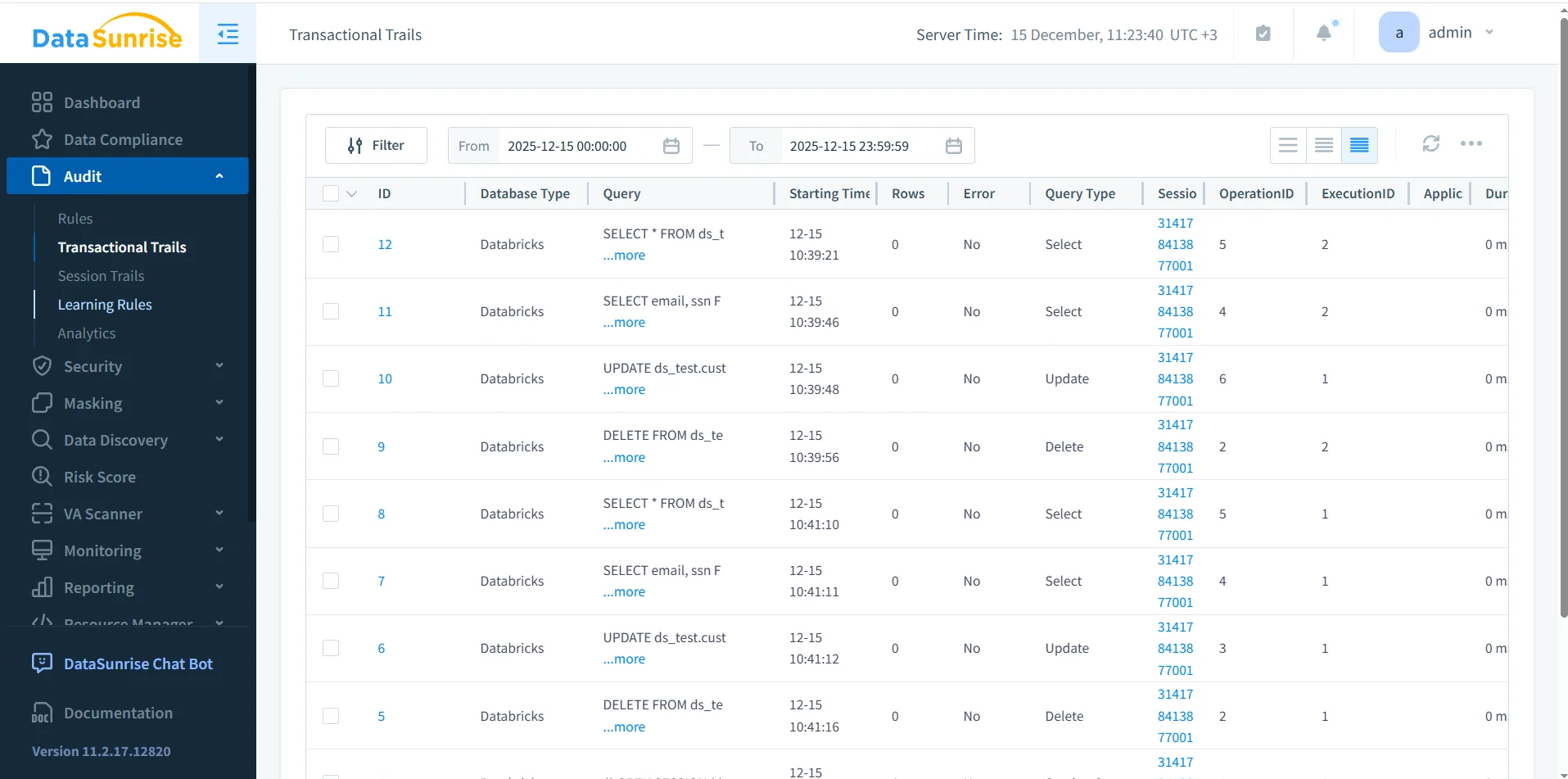
DataSunrise Transaktionsverläufe mit zentraler Übersicht über Databricks SQL-Auditdaten.
Jeder Audit-Eintrag enthält SQL-Text, Abfragetyp, Benutzeridentität, Sitzungskennung, Ausführungsstatus und Zeitinformationen. Diese Struktur unterstützt sowohl Echtzeitüberwachung als auch Nachuntersuchungen.
Schritt 5: Audit-Abdeckung mit realen Abfragen validieren
Nach der Konfiguration des Audits überprüfen Sie die Abdeckung, indem Sie repräsentative Abfragen ausführen und bestätigen, dass sie in der Auditierung in korrekter Reihenfolge erscheinen.
SELECT email, ssn FROM ds_test.customers; UPDATE ds_test.customers SET email = '[email protected]' WHERE id = 2; DELETE FROM ds_test.customers WHERE id = 2;
Eine verlässliche Audit-Einrichtung zeichnet jede Anweisung auf, bewahrt die Ausführungsreihenfolge und verknüpft alle Operationen mit dem gleichen Sitzungs-Kontext.
Schritt 6: Häufige Audit-Fehlerfälle
In der Praxis scheitern Audit-Implementierungen oft auf vorhersehbare Weise. Ein häufiges Problem tritt auf, wenn Audit-Logs Abfragen erfassen, aber den Sitzungs-Kontext weglassen, was die Rekonstruktion von Workflows unmöglich macht. Ein weiterer Fehler ist, wenn Aufbewahrungsrichtlinien Datensätze löschen, bevor das Audit durchgeführt wird.
Zusätzlich kann das Exportieren von Logs ohne Normalisierung inkonsistente Beweise erzeugen. Ermittler haben dann Schwierigkeiten, Zeitstempel oder Benutzeridentitäten systemübergreifend zuzuordnen.
Schritt 7: Aufbewahrung, Integrität und Nachweiskette
Prüfungsbeweise sind nur dann nützlich, wenn sie vertrauenswürdig bleiben. Organisationen müssen sicherstellen, dass Audit-Datensätze nicht verändert werden können und für den erforderlichen Aufbewahrungszeitraum verfügbar sind.
DataSunrise erzwingt zentrale Speicherung, Zugriffskontrollen und Aufbewahrungsrichtlinien. Dadurch bleibt die Integrität der Audit-Beweise erhalten und unterstützt Anforderungen zur Nachweiskette bei Untersuchungen und behördlichen Prüfungen. Für eine breitere Governance-Integration verknüpfen Teams diesen Workflow häufig mit Daten-Compliance-Programmen, um Aufbewahrung und Beweissicherungsprozesse konsistent zu gestalten.
Native vs. zentrale Auditierung: praktische Unterschiede
| Fähigkeit | Native Databricks SQL | DataSunrise Auditierung |
|---|---|---|
| Aufbewahrung | Kurzfristig | Langfristig konfigurierbar |
| Sitzungskorrelation | Minimal | Volle Sitzungserfassung |
| Qualität der Audit-Beweise | Operativ | Untersuchungsbereit |
| Compliance-Berichterstattung | Manuell | Strukturiert und automatisiert |
Fazit: Databricks SQL richtig auditieren
Die Auditierung von Databricks SQL erfordert mehr als nur die Aktivierung der Abfragehistorie. Es bedarf eines klaren Scopes, verlässlicher Erfassung, zentraler Speicherung, bewahrter Ausführungsreihenfolge und geschützter Aufbewahrung.
Durch die Kombination von nativer Sichtbarkeit in Databricks SQL mit zentralisierter Auditierung über DataSunrise erhalten Organisationen Prüfungsbeweise, die Untersuchungen, Compliance-Prüfungen und langfristige Governance unterstützen.
Richtig umgesetzt wird die Auditierung von Databricks SQL zu einem operativen Vorteil statt einer Compliance-Belastung.
