Datenanonymisierung in Vertica
Datenanonymisierung in Vertica ist eine entscheidende Fähigkeit für Organisationen, die auf groß angelegte Analysen angewiesen sind und dabei persönliche, finanzielle oder regulierte Informationen verarbeiten. Vertica ist für hochleistungsfähige analytische Workloads konzipiert, was es ideal für BI-Berichte, Kundenanalysen und Data Science macht. Gleichzeitig erhöht diese analytische Flexibilität das Risiko, dass sensible Werte in Abfrageergebnissen, Exporten oder nachgelagerten Systemen erscheinen können, wenn sie nicht ordnungsgemäß geschützt sind.
In modernen Vertica-Umgebungen greifen häufig mehrere Teams und Tools auf dieselben Datensätze zu. Analysten explorieren Daten interaktiv, BI-Dashboards führen geplante Abfragen aus und Machine-Learning-Pipelines extrahieren große Trainingsdatensätze. Da diese Workloads auf gemeinsamen Tabellen operieren, müssen Organisationen sicherstellen, dass sensible Attribute geschützt bleiben, ohne analytische Arbeitsabläufe zu unterbrechen oder Daten zu duplizieren.
Dieser Artikel erklärt, wie Datenanonymisierung in Vertica mittels zentralisierter Durchsetzung, dynamischer Anonymisierungstechniken und kontinuierlichem Audit umgesetzt werden kann, wobei DataSunrise Data Compliance als Schutzschicht fungiert.
Warum Datenanonymisierung in Vertica notwendig ist
Die Architektur von Vertica priorisiert analytische Leistung. Daten werden in spaltenbasierten ROS-Containern gespeichert, aktuelle Änderungen befinden sich im WOS, und Projektionen erzeugen mehrere optimierte physische Layouts derselben logischen Tabellen. Während dieses Design Abfragen beschleunigt, erschwert es gleichzeitig den fein granularen Datenschutz.
In der Praxis erhöhen mehrere Faktoren den Bedarf an Anonymisierung:
- Breite analytische Tabellen kombinieren häufig Metriken mit personenbezogenen Daten (PII) oder Zahlungsdaten.
- Projektionen replizieren sensible Spalten über mehrere Nodes.
- Geteilte Cluster unterstützen BI-Tools, ETL-Jobs, Notebooks und ML-Pipelines.
- Ad-hoc-SQL-Abfragen umgehen kuratierte Berichtsebenen.
- Natives Role-Based Access Control (RBAC) steuert den Zugriff, jedoch nicht die Wertebene.
Sobald ein Benutzer über SELECT-Zugriff verfügt, gibt Vertica alle ausgewählten Werte im Klartext zurück. Folglich benötigen Organisationen Anonymisierungsmechanismen, die zur Abfragezeit greifen, anstatt sich allein auf statische Berechtigungen zu verlassen.
Weitere Informationen finden Sie in der offiziellen Vertica-Architekturdokumentation.
Zentralisierte Anonymisierungsarchitektur für Vertica
Ein bewährter Ansatz zur Datenanonymisierung in Vertica ist es, die Durchsetzung vom Speicher zu trennen. In diesem Modell verbinden sich Client-Anwendungen über ein zentrales Gateway anstatt direkt mit Vertica. Jede SQL-Abfrage wird geprüft, Anonymisierungsregeln werden ausgewertet und sensible Werte werden vor der Rückgabe der Ergebnisse transformiert.
Viele Organisationen setzen diese Architektur mithilfe von DataSunrise als transparenten Proxy um. Da die Durchsetzung außerhalb von Vertica erfolgt, bleiben Schemata, Projektionen und Anwendungslogik unverändert.
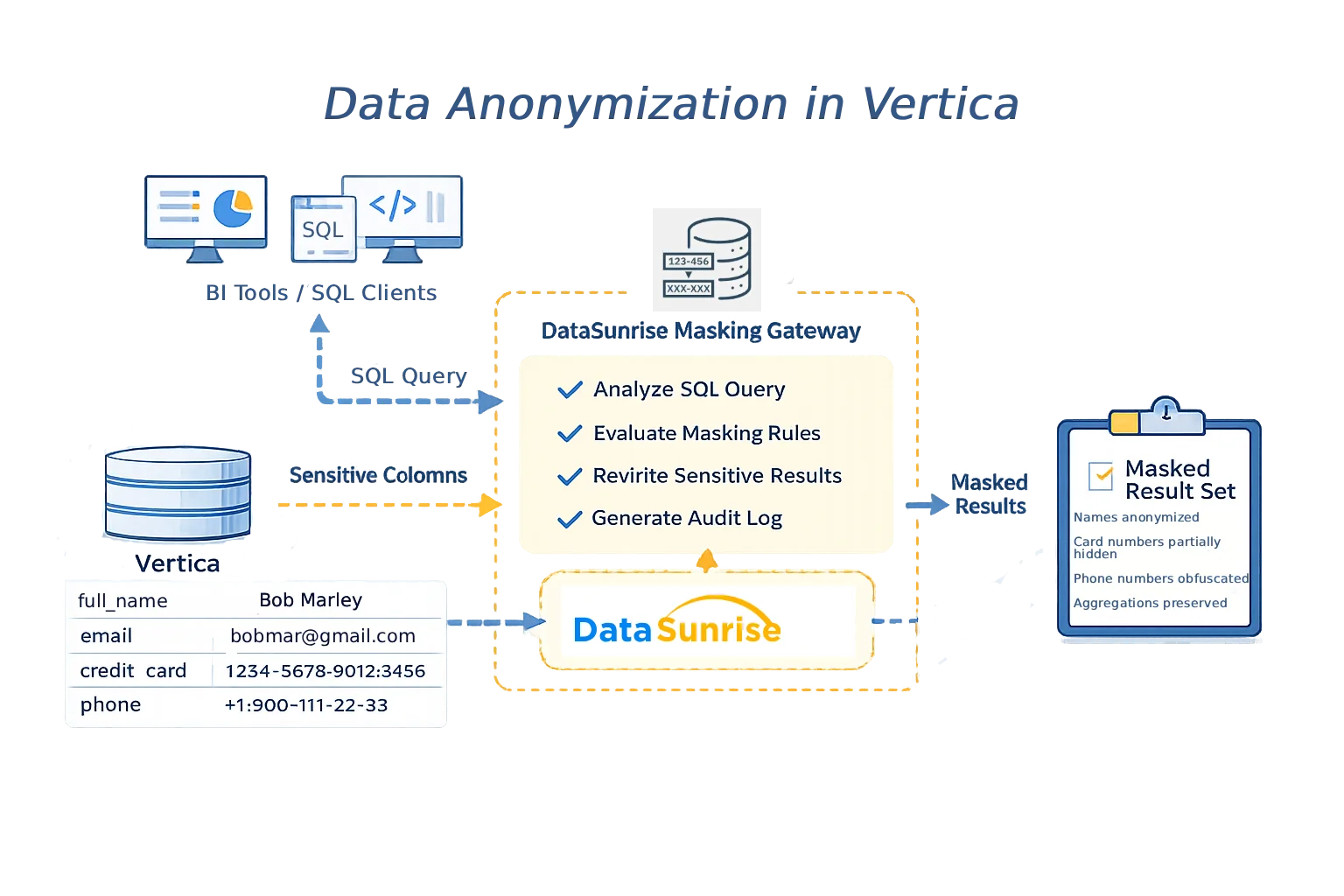
Zentralisierte Datenanonymisierungsarchitektur für Vertica mit DataSunrise als Durchsetzungsschicht.
Diese Architektur stellt sicher, dass Anonymisierungspolitiken einheitlich über alle Zugriffswege hinweg angewendet werden, einschließlich SQL-Clients, BI-Tools und automatisierten Pipelines.
Dynamische Anonymisierung als Kerngedanke
Dynamische Anonymisierung ist die effektivste Technik zum Schutz sensibler Daten in Vertica-Analysen. Anstatt gespeicherte Werte dauerhaft zu verändern, findet die Anonymisierung zur Abfragezeit statt. Wenn eine Abfrage sensible Spalten referenziert, werden die zurückgegebenen Werte durch anonymisierte Darstellungen ersetzt.
DataSunrise bietet integrierte dynamische Datenmaskierung und Anonymisierungsmechanismen, die jede Abfrage anhand von Richtlinienregeln bewerten. Diese Regeln können folgende Aspekte berücksichtigen:
- Datenbankbenutzer oder Rolle
- Typ der Client-Anwendung
- Umgebung (Produktion, Staging, Analytics)
- Sensitivitätsklassifizierung jeder Spalte
Da die Anonymisierung nur im Ergebnisdatensatz erfolgt, verarbeitet Vertica intern weiterhin die realen Werte. Dadurch bleiben Aggregationen, Joins, Filter und Berechnungen genau.
Konfiguration von Anonymisierungsregeln in Vertica
Um Anonymisierung anzuwenden, definieren Administratoren eine Regel, die eine Vertica-Instanz anspricht und angibt, welche Spalten geschützt werden müssen. Regeln beziehen sich typischerweise auf Schemata oder Tabellen, die durch automatisierte Erkennung identifiziert wurden.
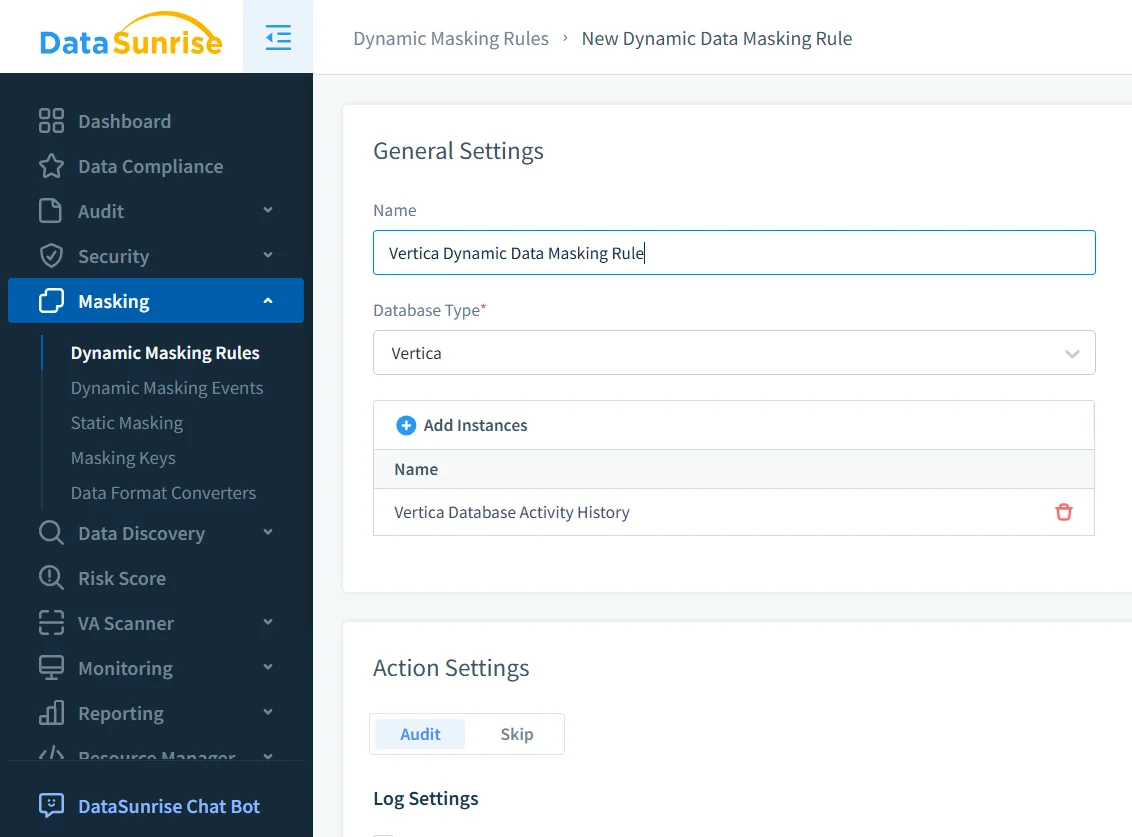
Konfiguration der Anonymisierungsregel für eine Vertica-Datenbankinstanz.
In diesem Schritt aktivieren Administratoren das Audit für Anonymisierungsereignisse und definieren, wie sensible Werte transformiert werden sollen. Formate können vollständige Anonymisierung, teilweise Maskierung oder Tokenisierung umfassen, abhängig von den Richtlinienanforderungen.
Anonymisierte Ergebnisse in analytischen Abfragen
Aus Sicht des Benutzers ist die Anonymisierung transparent. Abfragen verwenden standardmäßiges SQL, und Vertica führt sie normal aus. Sensible Werte erscheinen jedoch anonymisiert in den zurückgegebenen Ergebnissen.
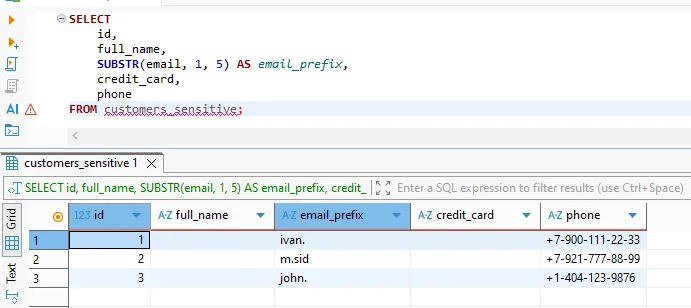
Anonymisierter Ergebnisdatensatz, der an den Client zurückgegeben wird, während die analytische Struktur erhalten bleibt.
Dieses Verhalten ermöglicht es Analysten, mit realistischen Datensätzen zu arbeiten und gleichzeitig die Offenlegung echter Identitäten zu verhindern. Gleichzeitig können Machine-Learning-Pipelines anonymisierte Trainingsdaten ohne Weitergabe personenbezogener Informationen konsumieren.
Audit und Transparenz bei anonymisiertem Zugriff
Anonymisierung muss auditierbar bleiben, um Compliance zu unterstützen. Organisationen müssen nachweisen können, wann Anonymisierung erfolgte, welche Regeln angewendet wurden und wer auf die Daten zugegriffen hat.
DataSunrise zeichnet Audit-Events für jede anonymisierte Abfrage automatisch auf. Diese Aufzeichnungen integrieren sich in das Database Activity Monitoring und können an SIEM-Systeme exportiert werden.
Zentrale Auditierung erleichtert die Einhaltung von Vorschriften wie DSGVO, HIPAA und SOX und unterstützt zudem interne Untersuchungen.
Vergleich von Anonymisierungsansätzen in Vertica
| Ansatz | Beschreibung | Eignung für Vertica |
|---|---|---|
| Statische Anonymisierung | Erstellen dauerhaft anonymisierter Datensätze | Hoher Wartungsaufwand, begrenzte Flexibilität |
| SQL-Views | Anonymisierung über vordefinierte Views | Leicht durch direkte Abfragen umgehbar |
| Anwendungsschicht-Logik | Anonymisierung innerhalb von BI oder Anwendungen | Inkonsistente Abdeckung |
| Dynamische Anonymisierung | Anonymisierung der Ergebnisse zur Abfragezeit | Zentralisiert und skalierbar |
Best Practices für Datenanonymisierung in Vertica
- Beginnen Sie mit automatischer Erkennung, um sensible Felder zu identifizieren.
- Wenden Sie Anonymisierung auf Abfrageebene an, anstatt Daten zu kopieren.
- Testen Sie Richtlinien mit realen BI- und Analyse-Workloads.
- Überprüfen Sie Audit-Logs regelmäßig auf unerwartete Zugriffsmuster.
- Richten Sie die Anonymisierung auf umfassendere Datensicherheits-Strategien aus.
Fazit
Datenanonymisierung in Vertica bietet eine skalierbare und analysefreundliche Methode zum Schutz sensibler Informationen. Durch dynamische Anonymisierung zur Abfragezeit reduzieren Organisationen Risiken der Offenlegung und bewahren gleichzeitig die Leistungsfähigkeit und Flexibilität von Vertica.
Mit DataSunrise als zentrale Durchsetzungsschicht profitieren Teams von konsequentem Schutz, vollständiger Audit-Transparenz und Einhaltung regulatorischer Vorgaben über Dashboards, Skripte und Machine-Learning-Pipelines hinweg – ohne Leistungseinbußen.
