
Datenbankprotokollierung: Best Practices und Lösungen
Einführung
Eine Studie von NewVantage Partners ergab, dass 91,9 % der führenden Unternehmen berichten, dass sie kontinuierlich in Daten- und KI-Initiativen investieren. In der heutigen datengetriebenen Welt ist eine effektive Protokollierung entscheidend für die Gesundheit, Sicherheit und Leistung von Datenbanksystemen. Aber haben Sie sich jemals gefragt, welche bewährten Verfahren es für die Speicherung dieser Protokolle gibt? Dieser Artikel taucht in die Feinheiten der Datenbankprotokollierung ein und untersucht die geeignetsten Speicherlösungen und Best Practices, um sicherzustellen, dass Ihre Protokollierungsstrategie sowohl effizient als auch informativ ist.
Was ist Datenbankprotokollierung?
Datenbankprotokollierung ist der Prozess der Aufzeichnung von Ereignissen, Aktionen und Änderungen innerhalb eines Datenbanksystems. Es ist wie das Führen eines detaillierten Tagebuchs über alles, was in Ihrer Datenbank passiert, von Benutzeraktionen bis hin zu Systemprozessen.
Die Feinheiten der Protokollierung von Datenbankvorgängen
Warum Datenbankvorgänge protokollieren?
Die Protokollierung von Datenbankvorgängen erfüllt mehrere kritische Zwecke:
- Fehlerbehebung: Protokolle helfen, Probleme schnell zu identifizieren und zu lösen.
- Datensicherheit: Sie bieten eine Prüfspur zum Aufspüren von unbefugtem Zugriff oder verdächtigen Aktivitäten.
- Leistungsoptimierung: Durch die Analyse von Protokollen können Engpässe identifiziert und die Abfrageleistung verbessert werden.
- Einhaltung gesetzlicher Vorschriften: Viele Branchen erfordern detaillierte Prüfprotokolle zur Einhaltung von Vorschriften.
Was sollte protokolliert werden?
Bei der Protokollierung von Datenbankvorgängen sollten Sie folgende Punkte aufzeichnen:
- Abfrageausführungszeiten
- Benutzeraktionen (Anmeldungen, Abmeldungen, fehlgeschlagene Versuche)
- Schemaänderungen
- Datenänderungen (Einfügungen, Aktualisierungen, Löschungen)
- Sicherungs- und Wiederherstellungsoperationen
- Fehlermeldungen und Ausnahmen
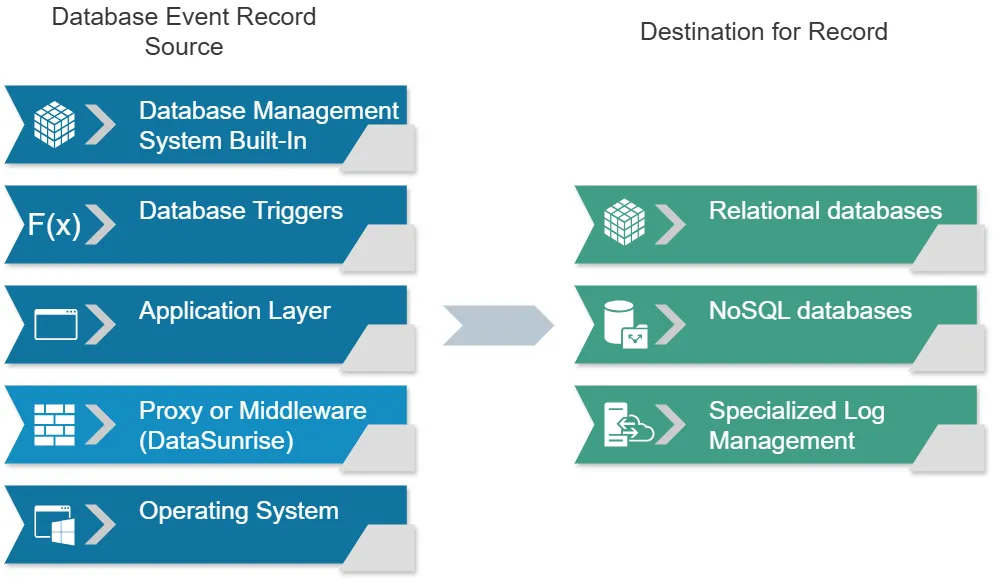
Datenquellen zur Protokollierung
Bevor wir zu den Speicherlösungen kommen, ist es wichtig zu verstehen, woher Protokolldaten stammen. In Datenbanksystemen werden Protokolldaten typischerweise aus mehreren Quellen generiert:
Datenbankverwaltungssystem (DBMS)
Die meisten Datenbanksysteme verfügen über integrierte Protokollierungsmechanismen, die verschiedene Ereignisse und Vorgänge erfassen.
- Beispiel: Das log_destination-Verzeichnis von PostgreSQL enthält Protokolldateien, die vom Datenbankserver generiert werden.
Datenbank-Trigger
Kundenspezifische Trigger können eingerichtet werden, um bestimmte Ereignisse oder Datenänderungen zu protokollieren.
- Beispiel: Ein Trigger, der alle Aktualisierungen einer sensiblen Tabelle protokolliert.
Anwendungsebene
Die Anwendung, die mit der Datenbank interagiert, kann Protokolle über die von ihr durchgeführten Datenbankvorgänge generieren.
- Beispiel: Eine Java-Anwendung, die JDBC verwendet, um SQL-Abfragen vor der Ausführung zu protokollieren.
Proxy oder Middleware
Datenbank-Proxys oder Middleware können den Datenbankverkehr abfangen und protokollieren.
- Beispiel: PgBouncer kann so konfiguriert werden, dass Verbindungsanfragen und Abfragen protokolliert werden.
Betriebssystem
Systemebene-Tools können die Datenbankaktivität auf der Betriebssystemebene erfassen.
- Beispiel: Der Linux-Befehl strace kann Systemaufrufe des Datenbankprozesses protokollieren.
Diese Quellen generieren die Rohprotokolldaten, die gespeichert und analysiert werden müssen.
Speicher für die Protokollierung
Nun wollen wir die verschiedenen Speicheroptionen für diese Protokolldaten untersuchen.
1. Relationale Datenbanken
Relationale Datenbanken wie PostgreSQL oder MySQL können zur Protokollierung verwendet werden. Sie bieten:
- Strukturierte Datenspeicherung
- Leistungsfähige Abfragefunktionen
- ACID-Konformität
Beispiel:
CREATE TABLE operation_logs (
id SERIAL PRIMARY KEY,
operation_type VARCHAR(50),
user_id INT,
query_text TEXT,
execution_time FLOAT,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO operation_logs (operation_type, user_id, query_text, execution_time)
VALUES ('SELECT', 1, 'SELECT * FROM users WHERE id = 5', 0.023);
Ergebnis: Dies erstellt eine Tabelle zur Speicherung von Vorgangsprotokollen und fügt einen Beispielprotokolleintrag ein.
DataSunrise verwendet SQLite als Standard-Protokollierungsdatenbank (auch als Wörterbuchdatenbank bekannt), um alle angegebenen Ereignisse und Regeln zu speichern. Benutzer haben die Möglichkeit, diese Datenbank während des Installationsprozesses zu ändern. Bei der Bereitstellung in Cloud-Infrastrukturen bietet DataSunrise auch entsprechende Optionen, die für solche Umgebungen maßgeschneidert sind.
2. NoSQL-Datenbanken
NoSQL-Datenbanken wie MongoDB oder Cassandra eignen sich hervorragend für die Verarbeitung großer Mengen unstrukturierter Protokolldaten. Sie bieten:
- Skalierbarkeit
- Flexibilität im Datenbank-Schema
- Hohe Schreibgeschwindigkeit
Beispiel (MongoDB):
db.operationLogs.insertOne({
operationType: "UPDATE",
userId: 2,
queryText: "UPDATE products SET price = 19.99 WHERE id = 100",
executionTime: 0.015,
timestamp: new Date()
});
Ergebnis: Dies fügt einen Protokolleintrag in eine MongoDB-Sammlung ein.
3. Spezialisierte Protokollmanagementsysteme
Tools wie Elasticsearch, Splunk oder Graylog sind speziell für das Protokollmanagement konzipiert. Sie bieten:
- Leistungsstarke Such- und Analysemöglichkeiten
- Echtzeitüberwachung und -alarmierung
- Visualisierungstools
Beispiel (Elasticsearch):
POST /operation_logs/_doc
{
"operation_type": "DELETE",
"user_id": 3,
"query_text": "DELETE FROM orders WHERE status = 'cancelled'",
"execution_time": 0.045,
"@timestamp": "2024-07-03T12:34:56Z"
}
Ergebnis: Dies fügt einen Protokolleintrag zu einem Elasticsearch-Index hinzu.
Trennung von Protokollierung und Hauptdatenspeicherung
Der Fall für eine Trennung
Die Verwendung derselben Datenbank sowohl für die Datenspeicherung als auch für die Protokollierung ist nicht immer die beste Vorgehensweise. Hier ist der Grund:
- Leistung: Protokollierungsvorgänge können sich auf die Leistung Ihrer Hauptdatenbank auswirken.
- Sicherheit: Das Trennen der Protokolle fügt eine zusätzliche Sicherheitsebene hinzu.
- Skalierbarkeit: Protokolldaten können schnell wachsen und die Speicherkapazität Ihrer Hauptdatenbank beeinträchtigen.
Wann sollte eine einheitliche Speicherung in Betracht gezogen werden?
In einigen Fällen kann es jedoch von Vorteil sein, dieselbe Datenbank zu verwenden:
- Kleinere Anwendungen mit geringem Datenverkehr
- Wenn Einfachheit bei der Einrichtung und Wartung Priorität hat
- Für spezifische Prüfungsanforderungen, bei denen Protokolle eng mit den Daten verbunden sein müssen
Best Practices für die Datenbankprotokollierung
- Verwenden Sie strukturierte Protokollformate (z.B. JSON) für eine einfachere Analyse und Auswertung.
- Implementieren Sie eine Protokollrotation, um Dateigrößen und Speicherplatz zu verwalten.
- Setzen Sie geeignete Protokollebenen, um ein Gleichgewicht zwischen Detailgrad und Leistung zu finden.
- Verschlüsseln Sie sensible Protokolldaten, um die Sicherheit zu erhöhen.
- Überprüfen und analysieren Sie regelmäßig Protokolle, um Einblicke und Anomalien zu erkennen.
Compliance und Audits
Die Datenbankprotokollierung spielt eine entscheidende Rolle bei der Erfüllung von Compliance-Anforderungen und der Erleichterung von Audits. Wichtige Überlegungen sind:
- Aufbewahrungsrichtlinien: Stellen Sie sicher, dass Protokolle für die erforderliche Dauer aufbewahrt werden.
- Zugriffskontrollen: Beschränken Sie, wer Protokolldaten anzeigen oder ändern kann.
- Manipulationssichere Protokollierung: Implementieren Sie Mechanismen, um Manipulationen an Protokollen zu erkennen.
Leistungsüberlegungen
Obwohl die Protokollierung wichtig ist, sollte der Einfluss auf die Datenbankleistung minimiert werden:
- Asynchrone Protokollierung: Schreiben Sie Protokolle asynchron, um die Latenz zu reduzieren.
- Batching: Fassen Sie mehrere Protokolleinträge zusammen, bevor Sie sie speichern.
- Sampling: Für Systeme mit hohem Datenvolumen sollten Sie in Betracht ziehen, nur eine Stichprobe der Ereignisse zu protokollieren.
Beispiel für asynchrone Protokollierung in Python:
import threading
import queue
log_queue = queue.Queue()
def log_writer():
while True:
log_entry = log_queue.get()
if log_entry is None:
break
# Schreibe log_entry in den Speicher
print(f"Schreibe Protokoll: {log_entry}")
writer_thread = threading.Thread(target=log_writer)
writer_thread.start()
# In Ihrer Hauptanwendung
log_queue.put("Benutzer 123 angemeldet")
log_queue.put("Abfrage ausgeführt: SELECT * FROM users")
# Beim Herunterfahren
log_queue.put(None)
writer_thread.join()
Ergebnis: Dies erstellt einen separaten Thread zum Schreiben von Protokollen, der es der Hauptanwendung ermöglicht, fortzufahren, ohne auf das Abschließen der Protokollschreibvorgänge zu warten.
Skalierbarkeit und Hochverfügbarkeit
Mit dem Wachstum Ihres Systems sollten Sie diese Strategien zur Skalierung Ihrer Protokollierungsinfrastruktur in Betracht ziehen:
- Verteilte Protokollierung: Verwenden Sie ein Cluster von Protokollservern, um hohe Datenmengen zu bewältigen.
- Lastenausgleich: Verteilen Sie die Protokollschreibvorgänge auf mehrere Knoten.
- Replikation: Halten Sie Kopien von Protokollen für Redundanz und Fehlertoleranz bereit.
Tools und Technologien
Mehrere Werkzeuge können Ihre Datenbankprotokollierungsstrategie verbessern:
- Logstash: Zum Sammeln, Verarbeiten und Weiterleiten von Protokollen
- Kibana: Zur Visualisierung und Analyse von Protokolldaten
- Fluentd: Ein Open-Source-Datenkollektor für einheitliche Protokollierung
Sicherheitsüberlegungen
Schützen Sie Ihre Protokolle mit diesen Sicherheitsmaßnahmen:
- Verschlüsselung: Sowohl während der Übertragung als auch im Ruhezustand
- Zugriffskontrollen: Implementieren Sie rollenbasierte Zugriffssteuerungen für Protokolldaten
- Überwachung: Richten Sie Alarme für verdächtigen Zugriff auf oder Änderungen an Protokollen ein
Zusammenfassung und Fazit
Eine effektive Datenbankprotokollierung ist ein Grundpfeiler eines robusten Datenbankmanagements. Durch die Wahl der richtigen Speicherlösung, die Implementierung bewährter Verfahren und die Nutzung geeigneter Tools können Sie ein Protokollierungssystem schaffen, das die Sicherheit erhöht, bei der Fehlerbehebung hilft und wertvolle Einblicke in Ihre Datenbankvorgänge bietet.
Denken Sie daran, dass der Schlüssel zur erfolgreichen Datenbankprotokollierung darin liegt, das richtige Gleichgewicht zwischen umfassender Datenerfassung und Systemleistung zu finden. Eine regelmäßige Überprüfung und Optimierung Ihrer Protokollierungsstrategie stellt sicher, dass sie weiterhin Ihren sich entwickelnden Anforderungen entspricht.
Für benutzerfreundliche und flexible Tools zur Datenbankprüfung, Maskierung und Einhaltung von Vorschriften sollten Sie sich die Angebote von DataSunrise ansehen. Besuchen Sie unsere Website unter DataSunrise.com für eine Online-Demo und entdecken Sie, wie wir Ihre Datenbanksicherheit und Protokollierungsfähigkeiten verbessern können.
