
Datenfilterung

Im Zeitalter von Big Data stehen Unternehmen vor einer Flut riesiger Informationsmengen aus unterschiedlichen Quellen. Um fundierte Entscheidungen zu treffen, ist es wichtig, zu filtern und die Datenverarbeitung sicher zu gestalten.
Die Datenfilterung ist eine Technik, die den Benutzern hilft, sich auf wichtige Informationen zu konzentrieren. Sie gewährleistet außerdem die Datensicherheit und Einhaltung von Vorschriften. Deshalb ist sie wichtig, um Informationen einzugrenzen.
Dieser Artikel wird die Grundlagen der Datenfilterung erläutern. Außerdem werden ihre praktischen Anwendungen und sicherheitsrelevanten Aspekte untersucht. Zusätzlich werden Beispiele vorgestellt, wie die Datenfilterung erfolgreich angewendet werden kann.
Was ist Datenfilterung?
Die Datenfilterung umfasst die Auswahl einer kleineren Datenmenge aus einem größeren Datensatz unter Verwendung spezifischer Kriterien oder Bedingungen. Filtern bedeutet, Regeln oder Filter anzuwenden, um nur die wichtigen Informationen für die Verarbeitung zu erhalten. Die Datenfilterung hilft dabei, unnötige Informationen zu entfernen und sich auf die wichtigsten Teile der Daten zu konzentrieren.
Die Datenfilterung kann die Effizienz steigern, indem sie die analysierten Daten begrenzt und die Handhabung erleichtert. Sie wird häufig in Datenbankabfragen, Berichten und der Datenanalyse verwendet, um sich auf relevante Informationen zu konzentrieren und irrelevante Details auszuschließen.
Datenquellen für die Filterung
Die Datenfilterung kann auf verschiedene Datenquellen angewendet werden, darunter:
- Strukturierte Daten sind Daten, die in einer bestimmten Weise organisiert sind, was die Suche, Analyse und Auffindbarkeit erleichtert. Diese Daten werden üblicherweise in Datenbanken, Tabellenkalkulationen und CSV-Dateien gespeichert und ordentlich in Zeilen und Spalten angeordnet.
- Unstrukturierte Daten hingegen sind Informationen, die kein vordefiniertes Format oder keine festgelegte Organisation aufweisen. Dies kann verschiedene Arten von Inhalten umfassen, wie schriftliche Dokumente, E-Mails, Social-Media-Beiträge und Webseiten. Diese Materialien können eine Mischung aus Text, Bildern und Videos enthalten. Die Analyse unstrukturierter Daten kann herausfordernd sein, da fortgeschrittene Techniken wie natürliche Sprachverarbeitung und maschinelles Lernen erforderlich sind.
- Semistrukturierte Daten liegen irgendwo zwischen strukturierten und unstrukturierten Daten. Diese Daten haben gewisse organisatorische Eigenschaften, passen jedoch möglicherweise nicht sauber in die traditionelle Datenbankstruktur. Einige Beispiele für semistrukturierte Daten sind XML-Dateien, JSON-Objekte und Protokolldateien. Sie enthalten eine Mischung aus strukturierten und unstrukturierten Informationen.
- Streaming-Daten werden kontinuierlich in Echtzeit erzeugt und verarbeitet. Diese Daten werden typischerweise von Sensoren, IoT-Geräten und Online-Transaktionen generiert und bieten wertvolle Einblicke in aktuelle Trends und Muster. Die Analyse von Streaming-Daten erfordert spezialisierte Werkzeuge und Technologien, um das hohe Volumen und die Geschwindigkeit der eintreffenden Daten zu bewältigen.
Sicherheitsaspekte der Datenfilterung
Die Datenfilterung spielt eine entscheidende Rolle bei der Gewährleistung der Datensicherheit und dem Schutz sensibler Informationen. Bei der Arbeit mit in Cloud-Speichern oder Datenbanken abgelegten Dateien ist es unerlässlich, geeignete Sicherheitsmaßnahmen zu implementieren. Hier sind einige wichtige Überlegungen:
Zugangskontrolle
Setzen Sie strenge Zugangskontrollen ein, um sicherzustellen, dass nur autorisierte Benutzer auf sensible Daten zugreifen und diese filtern können. Verwenden Sie rollenbasierte Zugriffskontrolle (RBAC), um Berechtigungen basierend auf den Rollen und Verantwortlichkeiten der Benutzer zu vergeben.
Datenverschlüsselung
Verschlüsseln Sie sensible Daten sowohl im Ruhezustand als auch bei der Übertragung, um sie vor unbefugtem Zugriff zu schützen. Verwenden Sie starke Verschlüsselungsalgorithmen und sichere Schlüsselverwaltungspraktiken.
Datenbankansichten
Nutzen Sie Datenbankansichten, um gefilterte Teilmengen von Daten zu erstellen, ohne die zugrunde liegenden Tabellen zu verändern. Ansichten ermöglichen es Ihnen, den Zugriff auf bestimmte Spalten oder Zeilen basierend auf Benutzerberechtigungen zu kontrollieren, sodass Benutzer nur die Daten sehen und filtern können, zu denen sie autorisiert sind.
Überwachung und Protokollierung
Implementieren Sie umfassende Überwachungs- und Protokollierungsmechanismen, um den Datenzugriff und die Filteraktivitäten nachzuverfolgen. Überwachen und analysieren Sie Protokolle, um verdächtige oder unbefugte Zugriffsversuche zu erkennen.
Beispiele für Datenfilterung
Lassen Sie uns einige Beispiele dafür betrachten, wie man Datenfilter in verschiedenen Szenarien erstellt.
Beispiel 1
Wir werden uns das Filtern von Daten in einer Tabellenkalkulation ansehen. Angenommen, Sie haben eine Tabellenkalkulation mit Kundendaten. Zeigen Sie nur Kunden aus einer bestimmten Region an. Diese Kunden müssen einen bestimmten Betrag an Ausgaben überschritten haben. Dies hilft, die Daten zu verfeinern.
- Öffnen Sie die Tabellenkalkulation und wählen Sie den Datenbereich aus, den Sie filtern möchten.
- Klicken Sie in der Menüleiste auf die Registerkarte “Daten” und wählen Sie “Filter”.
- Klicken Sie auf den Filterpfeil in der Spalte “Region” und wählen Sie die gewünschte Region aus der Dropdown-Liste aus.
- Klicken Sie auf den Filterpfeil in der Spalte “Kaufbetrag” und geben Sie die Bedingung ein (z.B. größer als 1000 $).
- Die Tabellenkalkulation zeigt nun nur die gefilterten Daten basierend auf Ihren Kriterien an.
Beispiel 2
Wenn Sie Daten in einer Datenbank mithilfe von SQL filtern, denken Sie an eine Tabelle namens “employees”. Diese Tabelle enthält Spalten wie “id”, “name”, “department” und “salary”. Sie möchten die Daten filtern, um Mitarbeiter aus der Abteilung “Sales” mit einem Gehalt von über 50.000 $ zu erhalten.
- Stellen Sie mit einem SQL-Client oder der Kommandozeile eine Verbindung zu Ihrer Datenbank her.
- Führen Sie die folgende SQL-Abfrage aus:
SELECT * FROM employees WHERE department = 'Sales' AND salary > 50000;
Die Abfrage liefert die gefilterte Ergebnismenge und zeigt nur die Mitarbeiter an, die den angegebenen Kriterien entsprechen.
Hinweis: Stellen Sie vor der Ausführung der Abfrage sicher, dass die Tabelle “employees” in Ihrer Datenbank existiert und die relevanten Spalten enthält.
Überblick über Datenkonformität | Regulatorische Rahmenbedingungen
Richtlinienbasierte, KI-unterstützte Filterung
Manuelle Regeln stoßen an ihre Grenzen, sobald sich Daten über verschiedene Clouds und Formate erstrecken. Moderne Plattformen kombinieren automatische Datenklassifizierung mit Richtlinien-Engines, die in Echtzeit entscheiden, welche Zeilen, Spalten oder Dateien jeder Benutzer sehen darf. DataSunrise identifiziert sensible Felder, bewertet Risiken und maskiert oder blockiert dann jede Abfrage, die gegen Richtlinien verstößt, ohne zusätzliche Verzögerungen zu verursachen.
Dieser Ansatz entspricht dem Zero-Trust-Prinzip und sorgt dafür, dass Prüfer zufrieden sind. Jede Zulassungs- oder Ablehnungsentscheidung wird protokolliert, versioniert und kann in Ihr SIEM exportiert werden, was beweist, dass PII, PHI oder Kartendaten niemals durch die Maschen rutschen.
Implementierung der Datenfilterung mit DataSunrise
Dedizierte Software mit zentralisierter Kontrolle aller Datenfilterregeln vereinfacht die Verwaltung und gewährleistet Konsistenz über verschiedene Datenquellen hinweg, wodurch separate Filtermechanismen in jeder Tabellenkalkulation, Datenbankabfrage oder Ansicht entfallen. DataSunrise ist eine umfassende Lösung für das Datenmanagement, die außergewöhnliche und flexible Werkzeuge für Datensicherheit, Auditregeln, Maskierung und Konformität bietet. Mit DataSunrise Audit und Security können Sie fortschrittliche Datenfilterungsfunktionen problemlos implementieren, um sensible Informationen zu schützen und die Datenprivatsphäre zu gewährleisten.
DataSunrise bietet eine benutzerfreundliche Oberfläche mit leistungsstarken Funktionen wie detaillierter Zugangskontrolle, Datenmaskierung und Live-Überwachung. Im Audit können Sie detaillierte Filterregeln anhand verschiedener Kriterien wie Anwendungsbenutzer, Datenbankbenutzer und Anwendung erstellen. Sicherheitsregeln erlauben es, Datenbankbenutzer vom Zugriff auf unangebrachte Daten auszuschließen. Sowohl Sicherheits- als auch Auditregeln ermöglichen es, Abfragen anhand regulärer Ausdrücke über Abfragegruppen zu filtern. DataSunrise integriert sich nahtlos in mehrere Datenbanken und Cloud-Plattformen und ist somit eine vielseitige Lösung für die Datenfilterung in verschiedenen Umgebungen.
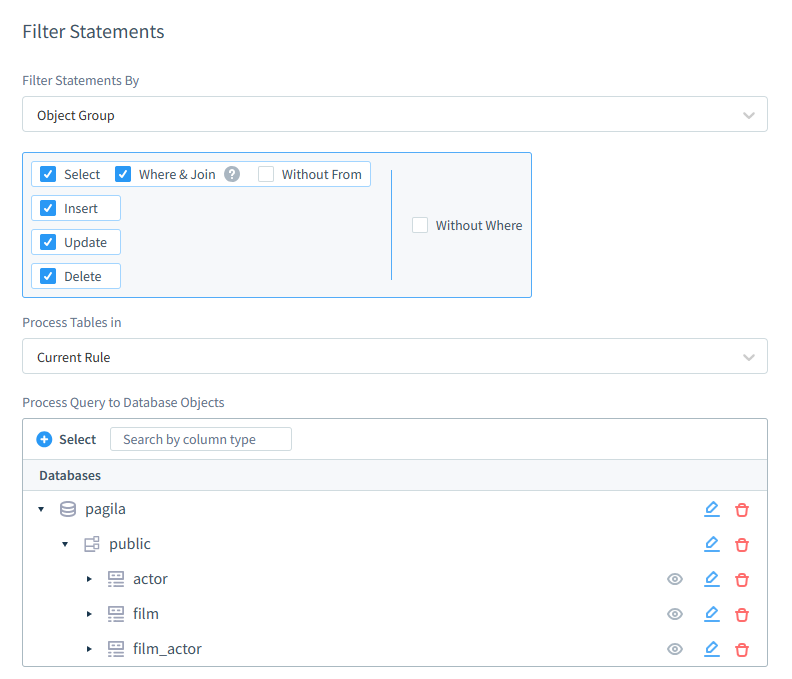
Die Funktion der flexiblen dynamischen Maskierung ermöglicht es Ihnen, sensible Informationen durch leere Zeilen zu ersetzen. Viele weitere Maskierungsmethoden stehen ebenfalls zur Verfügung.
Fazit
Die Datenfilterung ist eine wesentliche Technik für das effektive Verwalten und Verarbeiten großer Datenmengen. Durch das Verständnis der Grundlagen der Datenfilterung, ihrer Anwendungen und sicherheitsrelevanten Aspekte können Organisationen wertvolle Erkenntnisse gewinnen und gleichzeitig den Datenschutz und die Einhaltung von Vorschriften sicherstellen. Die Implementierung der Datenfilterung mit Werkzeugen wie DataSunrise vereinfacht den Prozess und bietet fortschrittliche Möglichkeiten zum Schutz sensibler Informationen.
Um mehr darüber zu erfahren, wie DataSunrise Ihnen bei der Datenfilterung und anderen Anforderungen des Datenmanagements helfen kann, laden wir Sie ein, unser Team bei einer Online-Demo kennenzulernen. Unsere Experten werden die besten Funktionen von DataSunrise hervorheben. Sie werden demonstrieren, wie es Ihrer Organisation helfen kann, Ihre Daten effektiv zu verwalten und zu schützen.
