Datenverschleierung in Vertica
Datenverschleierung in Vertica ist ein praxisorientierter Ansatz zum Schutz sensibler Informationen, bei gleichzeitigem Erhalt der Nutzbarkeit analytischer Datensätze. Vertica wird weit verbreitet für groß angelegte Analysen, Reporting und Data Science eingesetzt, wo hohe Abfrageleistung und flexibler Zugriff unverzichtbar sind. Sobald jedoch sensible Attribute wie persönliche Kennungen, Finanzdaten oder regulierte Geschäftsdaten in analytischen Tabellen auftauchen, führt uneingeschränkte Sichtbarkeit zu ernsthaften Compliance- und Sicherheitsrisiken.
Im Gegensatz zur Verschlüsselung, die Daten im Ruhezustand oder während der Übertragung schützt, konzentriert sich die Verschleierung darauf, zu steuern, was Benutzer tatsächlich in den Abfrageergebnissen sehen. In Vertica-Umgebungen, in denen dieselben Tabellen mehreren Teams und Tools dienen, hilft Datenverschleierung Organisationen, die Datenexposition zu reduzieren, ohne Daten zu duplizieren oder vorhandene Abfragen zu ändern. Dadurch behalten Teams ihre analytische Agilität bei und erzwingen zugleich einen konsistenten Schutz, der mit Datenschutzprinzipien im Einklang steht.
Dieser Artikel erklärt, wie Datenverschleierung in Vertica mithilfe zentraler Kontrollmechanismen, dynamischer Maskierungstechniken und Auditierung implementiert wird, wobei DataSunrise als Durchsetzungsschicht über seine Data Compliance-Funktionen agiert.
Warum Datenverschleierung in Vertica wichtig ist
Die Architektur von Vertica ist auf analytischen Durchsatz optimiert. Spaltenspeicherung, ROS/WOS-Schichten und projektionsbasierte Ausführung ermöglichen eine schnelle Verarbeitung großer Datensätze. Gleichzeitig erschweren diese Merkmale den Einsatz fein granularer Datenschutzmaßnahmen mit traditionellen Methoden.
In der Praxis erhöhen verschiedene Situationen den Bedarf an Verschleierung:
- Analytische Tabellen, die Kennzahlen mit personenbezogenen Daten (PII) oder Zahlungsinformationen kombinieren.
- Geteilte Vertica-Cluster, die von Analysten, Anwendungen und Automatisierungen genutzt werden.
- Explorative SQL-Abfragen, die mehr Daten offenlegen als beabsichtigt.
- Nachgelagerte Exporte oder Berichte, die direkt aus rohen Abfrageergebnissen erstellt werden.
Das native rollenbasierte Zugriffskontrollsystem von Vertica legt fest, wer eine Tabelle abfragen darf. Es schränkt jedoch nicht ein, welche Spaltenwerte im Ergebnis erscheinen. Nach Ausführung einer Abfrage liefert Vertica alle ausgewählten Daten in Klartext zurück. Datenverschleierung schließt daher diese Lücke, indem sensible Werte vor Erreichen des Clients transformiert werden, und ergänzt damit fortschrittliche Zugriffskontrollen.
Hintergrundinformationen zum Ausführungsmodell von Vertica finden Sie in der offiziellen Vertica Architektur-Dokumentation.
Zentrale Verschleierungsarchitektur für Vertica
Organisationen implementieren Datenverschleierung in Vertica typischerweise mit einem zentralisierten Gateway-Modell. In dieser Architektur verbinden sich Client-Anwendungen über eine Zwischenschicht und nicht direkt mit der Datenbank. Diese Schicht überprüft SQL-Abfragen, bewertet Schutzregeln und wendet die Verschleierung einheitlich an.
Viele Teams verwenden DataSunrise Data Compliance zur Umsetzung dieses Modells. DataSunrise agiert als transparenter Proxy vor Vertica und setzt Verschleierungsregeln durch, ohne Schemata, Projektionen oder Anwendungslogik zu verändern. Zudem wird eine Integration mit Datenbankaktivitätsüberwachung geboten, die kontinuierliche Transparenz ermöglicht.
Durch diesen Ansatz werden folgende Vorteile erreicht:
- Einheitliche Verschleierung über BI-Tools, Skripte und Dienste hinweg.
- Richtlinienbasierte Kontrolle basierend auf Benutzer, Rolle oder Anwendungskontext.
- Zentrale Konfiguration mit konsistenter Durchsetzung.
- Auditierung mit minimaler Auswirkung auf die Vertica-Leistung.
Dynamisches Maskieren als Verschleierungstechnik
Dynamisches Datenmaskieren dient als primäre Technik zur Datenverschleierung in Vertica. Anstatt gespeicherte Daten dauerhaft zu verändern, werden zur Laufzeit sensible Werte in Abfrageergebnissen umgeschrieben. Intern speichert und verarbeitet Vertica weiterhin die Originalwerte.
DataSunrise bietet integrierte Fähigkeiten zum dynamischen Datenmaskieren, welche jede Abfrage anhand von Richtlinienregeln bewerten. Diese Regeln können unter anderem berücksichtigen:
- Den Datenbankbenutzer oder die Rolle.
- Die Client-Anwendung oder den Verbindungstyp.
- Die Umgebung, etwa Produktion oder Analyse.
- Die Sensitivitätsklassifizierung einzelner Spalten.
Da die Verschleierung nur auf Ergebnisebene erfolgt, bleibt die analytische Korrektheit erhalten. Aggregationen, Joins, Filter und Berechnungen operieren intern weiterhin auf Originaldaten, während maskierte Darstellungen an den Benutzer zurückgegeben werden. Dieser Ansatz stimmt mit umfassenderen Datensicherheits-Strategien überein.
Konfiguration von Verschleierungsregeln in Vertica
Der erste Schritt bei der Anwendung von Datenverschleierung ist das Definieren einer Regel, die die Vertica-Instanz anspricht und bestimmt, welche Daten transformiert werden sollen. Administratoren geben dabei die zu schützenden Schemata oder Tabellen an und wählen die zu verschleierenden Spalten aus.
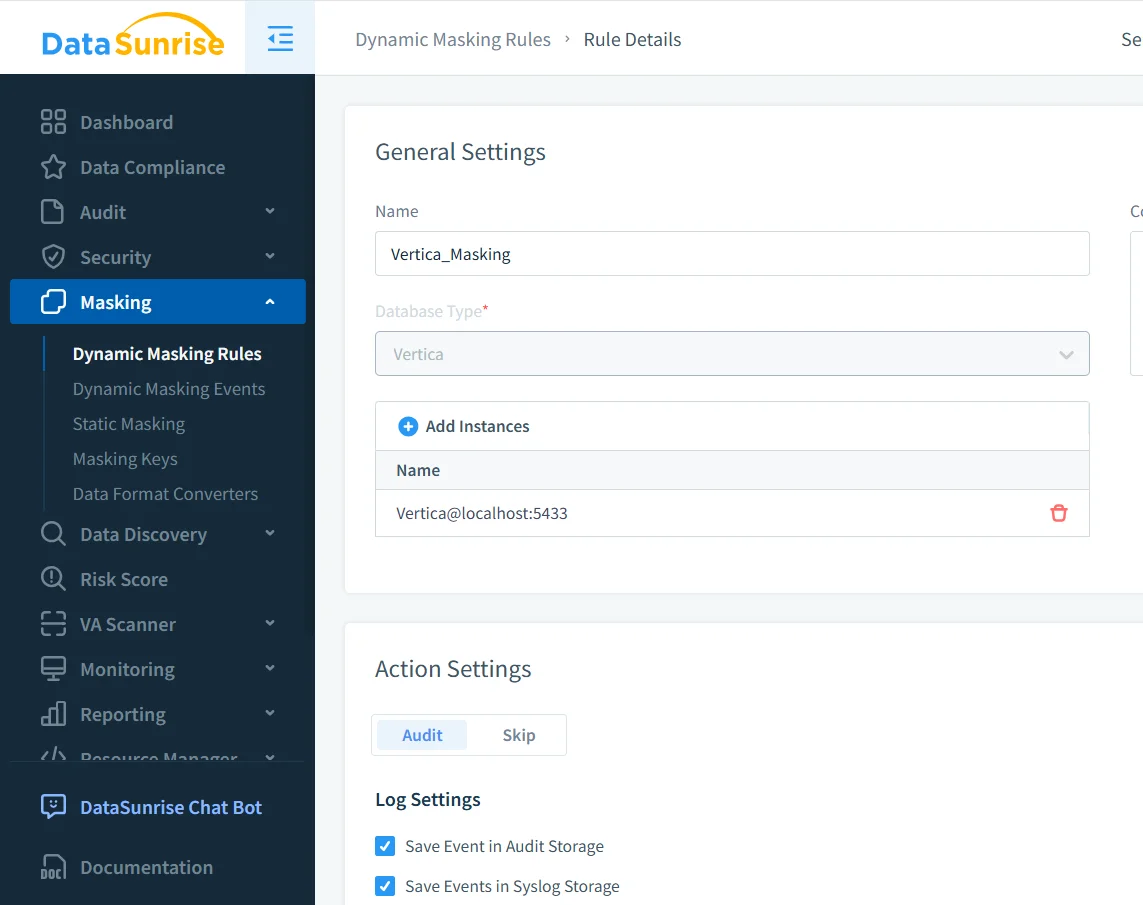
In diesem Schritt aktivieren Administratoren zudem die Auditierung von Verschleierungsereignissen. So zeichnet das System jede Transformation zur Einhaltung von Compliance und Fehlersuche auf und integriert sich mit Audit-Protokollen.
Sobald die Regel existiert, definieren Administratoren, welche Spalten verschleiert und wie dies geschehen soll. Je nach Anwendungsfall kommen unterschiedliche Formate zum Einsatz, wie Teilmaskierung, Token-Ersetzung oder vollständige Anonymisierung, unterstützt durch Datenmaskierungstechniken.
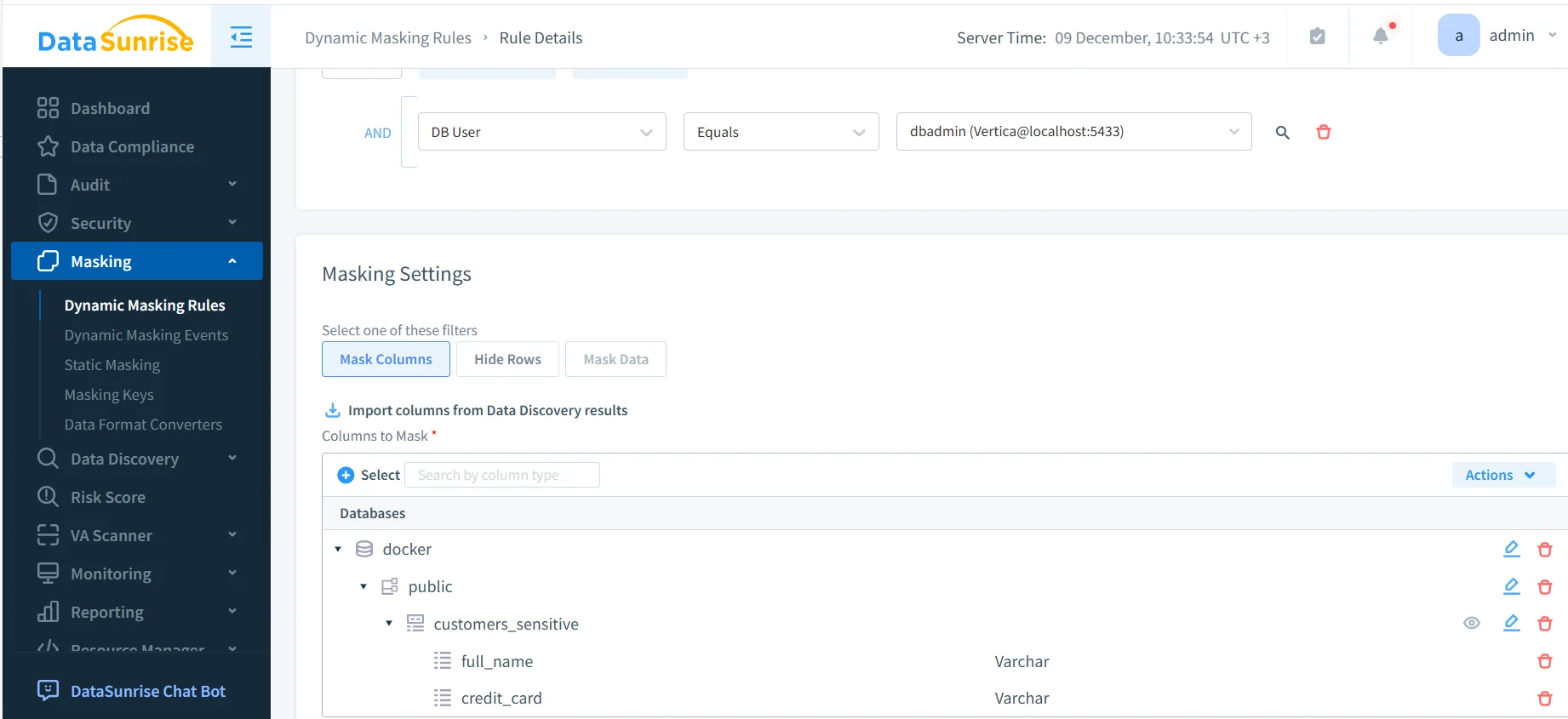
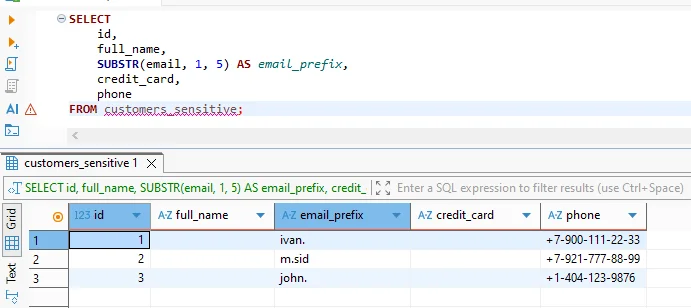
Verschleierte Ergebnisse in analytischen Abfragen
Aus der Perspektive von Analysten und Anwendungen bleibt die Datenverschleierung transparent. Abfragen werden mit Standard-SQL formuliert und von Vertica normal ausgeführt. Die zurückgegebenen Werte spiegeln jedoch die Verschleierungsrichtlinie wider.
Verschleierte Ergebnisse unterstützen weiterhin Joins, Filter, Aggregationen und Gruppierungen. Daher eignet sich die Technik für BI-Dashboards, explorative Analysen und Machine Learning Feature Engineering Workflows, die durch Daten-Governance-Regeln gesteuert werden.
Da die Richtlinien dem Benutzer und dem Ausführungskontext folgen, entfällt für Teams die Notwendigkeit, separate Datensätze zu pflegen oder Berichte umzuschreiben. Stattdessen bedienen dieselben Vertica-Tabellen sicher verschiedene Zielgruppen mit unterschiedlichen Sichtbarkeitsstufen.
Auditierung des Zugriffs auf verschleierte Daten
Effektive Datenverschleierung erfordert Transparenz. Organisationen müssen nachweisen können, wann sensible Werte transformiert wurden und wer auf die Daten zugegriffen hat.
DataSunrise zeichnet automatisch Audit-Events für jede verschleierte Abfrage auf, einschließlich:
- Des Datenbankbenutzers und der Client-Anwendung.
- Der ausgeführten SQL-Anweisung.
- Der angewandten Verschleierungsregel.
- Zeitstempel und Kontext der Ausführung.
Diese Audit-Daten integrieren sich in Database Activity Monitoring und unterstützen die Einhaltung von Vorschriften wie DSGVO, HIPAA und SOX. Sie fließen zudem in Compliance Manager-Workflows ein.
Vergleich von Datenverschleierungstechniken in Vertica
| Technik | Beschreibung | Eignung für Vertica |
|---|---|---|
| Statische Verschleierung | Erstellung dauerhaft verschleierter Datensätze | Hoher Wartungsaufwand, begrenzte Flexibilität |
| View-basierte Verschleierung | Anwendung von Transformationen über SQL Views | Leicht durch direkten Zugriff umgehbar |
| Anwendungsschicht-Verschleierung | Verschleierungslogik in BI-Tools oder Anwendungen | Inkonsequente Durchsetzung |
| Dynamische Verschleierung | Umschreiben der Ergebnisse zur Abfragezeit | Zentralisiert und skalierbar |
Best Practices für Datenverschleierung in Vertica
- Identifikation sensibler Spalten mit automatisierter Entdeckung.
- Anwendung der Verschleierung auf Abfrageebene statt Datenkopie.
- Testen von Regeln mit realen analytischen Workloads.
- Regelmäßige Überprüfung von Audit-Protokollen auf unerwartete Zugriffe.
- Abstimmung der Verschleierungsrichtlinien mit umfassenderen Datensicherheits-Strategien.
Fazit
Datenverschleierung in Vertica bietet eine flexible und skalierbare Möglichkeit, sensible Informationen in analytischen Umgebungen zu schützen. Durch die dynamische Transformation zur Abfragezeit verringern Organisationen das Risiko der Datenexposition, ohne Leistung oder Nutzbarkeit einzubüßen.
Mit DataSunrise als zentralisierter Durchsetzungsschicht bleibt Vertica eine leistungsstarke Analyseplattform, während sensible Daten in Dashboards, Skripten und Machine-Learning-Pipelines geschützt bleiben.
