
Dynamische Datenmaskierung für Apache Hive

Einleitung
In der heutigen datengesteuerten Welt ist der Schutz persönlicher und sensibler Informationen für Organisationen, die versuchen, Vorschriften wie die DSGVO und CCPA einzuhalten, von größter Bedeutung. Dynamische Datenmaskierung für Apache Hive (und andere Datenbanken) bietet eine robuste Lösung, um Ihre Daten zu sichern, ohne dabei die Zugänglichkeit oder Leistung zu beeinträchtigen.
Um die Bedeutung der Implementierung angemessener Datenbanksicherheitsmaßnahmen – wie etwa Datenmaskierung – zu unterstreichen, bedenken Sie diese alarmierende Statistik: Die National Vulnerability Database (NVD) hat über 279.000 Sicherheitslücken registriert und die Zahl steigt weiter. Diese wachsende Zahl unterstreicht den dringenden Bedarf an starken Datenschutzstrategien, bei denen die dynamische Datenmaskierung eine entscheidende Rolle beim Schutz sensibler Informationen spielt.
Angesichts zunehmender Bedrohungen ist es wichtiger denn je, Ihre sensiblen Daten in den Datenbanken und in den Apache Hive-Umgebungen zu schützen. In diesem Artikel werden wir untersuchen, wie dynamische Datenmaskierung Ihre Sicherheitsstrategie für Hive-Daten verbessern kann.
Verständnis der Datenmaskierungsfunktionen von Hive
Hive bietet grundlegende Datenmaskierungsfunktionen durch seine SQL-Funktionen, die als erste Schutzschicht dienen können. Diese nativen Optionen besitzen jedoch möglicherweise nicht die Tiefe und Flexibilität, die für eine umfassende Sicherheit erforderlich ist.
Beispieldaten (zum Testen)
Um die integrierten Maskierungsfunktionen zu testen, können Sie eine kleine Tabelle mit Beispieldaten wie folgt erstellen:
CREATE TABLE SAMPLE_DATA (
id INT,
first_name STRING,
last_name STRING,
email STRING
);
INSERT INTO TABLE SAMPLE_DATA
VALUES
(9, 'Natalia', 'Chen', '[email protected]'),
(10, 'Rafael', 'Anderson', '[email protected]'),
(11, 'Lucas', 'Garcia', '[email protected]');
1. Verwendung von regexp_replace
Die Funktion regexp_replace von Hive ermöglicht eine einfache Datenmaskierung, indem Teile eines Strings basierend auf einem Regex-Muster ersetzt werden.
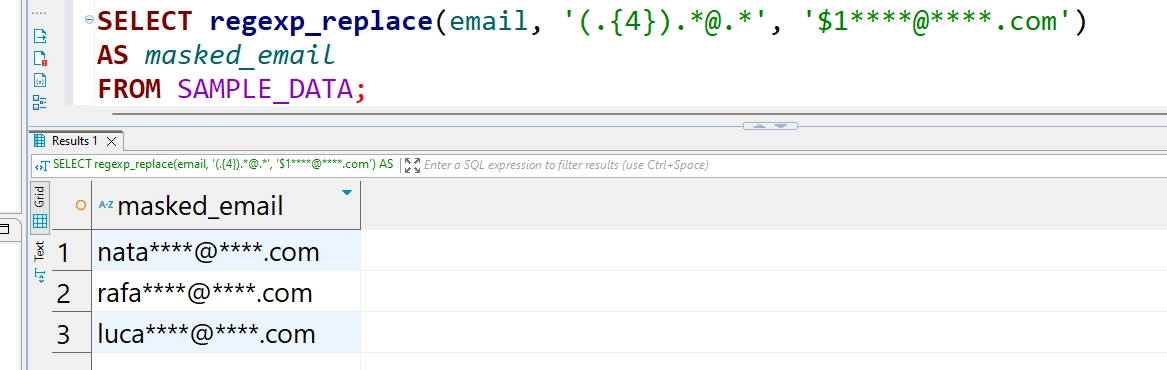
SELECT regexp_replace(email, '(.{4}).*@.*', '$1****@****.com') AS masked_email
FROM SAMPLE_DATA;
Diese Abfrage maskiert die E-Mail-Adressen, sodass nur die ersten vier Zeichen und die Domain-Erweiterung sichtbar bleiben.
2. Erstellen maskierter Ansichten
In Hive können Sie Ansichten erstellen, um maskierte Daten anzuzeigen, ohne die Originaltabellen zu verändern.
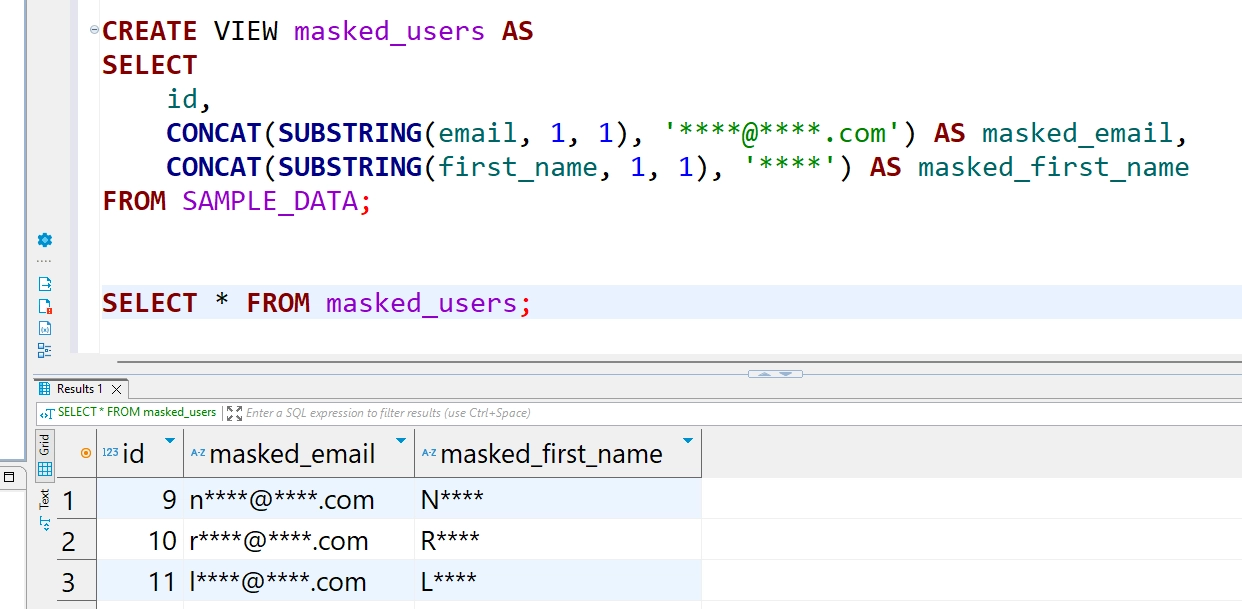
CREATE VIEW masked_users AS
SELECT
id,
CONCAT(SUBSTRING(email, 1, 1), '****@****.com') AS masked_email,
CONCAT(SUBSTRING(first_name, 1, 1), '****') AS masked_first_name
FROM SAMPLE_DATA;
Sie können diese Ansicht abfragen, um zu überprüfen, wie die Maskierung angewendet wurde:
SELECT * FROM masked_users;
Das Abfragen dieser Ansicht maskiert die E-Mail-Adressen und Namen, indem nur der erste Buchstabe der E-Mail und Vornamen angezeigt und der Rest durch Sternchen ersetzt wird, während die Domain-Erweiterung der E-Mails sichtbar bleibt.
3. Verwendung von Hives integrierten UDF-Funktionen für die Datenmaskierung
Hive unterstützt mehrere integrierte UDF-Funktionen zur Datenmaskierung, die eine einfache Möglichkeit bieten, sensible Daten zu schützen, ohne benutzerdefinierte Funktionen implementieren zu müssen.
- E-Mail maskieren (Ersten Buchstaben sichtbar lassen):
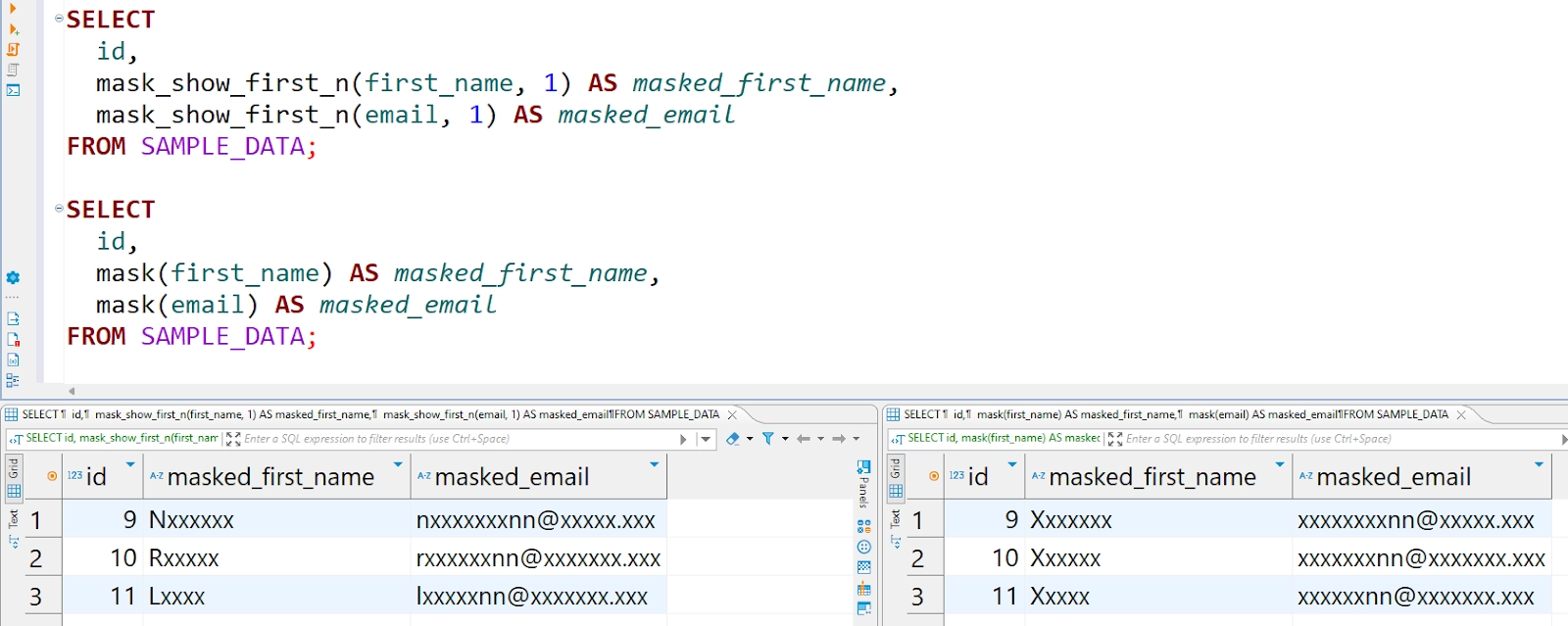
SELECT
id,
mask_show_first_n(first_name, 1) AS masked_first_name,
mask_show_first_n(email, 1) AS masked_email
FROM SAMPLE_DATA;
Hier wird mask_show_first_n() verwendet, um den ersten Buchstaben von sowohl first_name als auch email anzuzeigen, während der Rest maskiert wird.
- Komplettmaskierung der Daten:
SELECT
id,
mask(first_name) AS masked_first_name,
mask(email) AS masked_email
FROM SAMPLE_DATA;
Hier maskiert mask() die Daten vollständig und ersetzt Zeichen gemäß den Standardregeln (Großbuchstaben als X, Kleinbuchstaben als x und Zahlen als n).
Nachstehend sehen Sie Beispiele der resultierenden Ausgaben für beide Abfragen.
Sie können auch eigene UDF-Funktionen zur Datenmaskierung implementieren. Um mehr über dieses Thema zu erfahren, besuchen Sie die UDF-Dokumentationsseite von Apache Hive.
Einschränkungen der integrierten Maskierung in Hive
Obwohl Hive einfache Optionen zur Datenmaskierung bietet, gehen diese mit inherenten Einschränkungen einher:
-
Statische Datenmaskierung: Die Maskierung in Hive ist statisch und passt sich nicht an Benutzerrollen oder den Kontext an. Funktionen wie
mask(),mask_show_first_n()undregexp_replace()wenden dieselbe Transformation für alle Benutzer an, im Gegensatz zur dynamischen Datenmaskierung (DDM), die sich basierend auf Zugangskontrollen anpasst. -
Keine rollenbasierte Maskierung: Die integrierten Methoden von Hive wenden dieselbe Maskierung für alle Benutzer an, was bedeutet, dass auch privilegierte Benutzer maskierte Daten sehen, sofern keine separaten Zugangskontrollen implementiert sind.
-
Begrenzte Anpassungsmöglichkeiten: Die Maskierungsfunktionen folgen vordefinierten Mustern (
X,x,n), undregexp_replace()unterstützt nur statische Mustererkennung. Eine fortschrittlichere Maskierung – wie bedingte oder rollenbasierte Transformationen – erfordert benutzerdefinierte UDFs oder externe Tools.
Für fortgeschrittene Maskierungsanforderungen sollten Sie die Integration dynamischer Datenmaskierungslösungen oder die Implementierung benutzerdefinierter UDFs in Betracht ziehen, die auf Ihre spezifischen Anforderungen zugeschnitten sind.
Dynamische Datenmaskierung für Apache Hive mit DataSunrise
Um die Einschränkungen der integrierten Maskierung in Hive zu überwinden, bietet DataSunrise eine umfassende dynamische Datenmaskierung (DDM), die den Echtzeitschutz sensibler Daten basierend auf Benutzerrollen und Kontext ermöglicht. Im Gegensatz zu den statischen Methoden von Hive steuert DataSunrise die Datenzugänglichkeit dynamisch über vordefinierte Sicherheitsregeln.
Wesentliche Vorteile der dynamischen Datenmaskierung von DataSunrise für Apache Hive
- Rollenbasierte Sicherheit – Wendet die Maskierung basierend auf Benutzerrollen und Zugriffsrechten an
- Kontextabhängiger Schutz – Passt die Maskierung basierend auf dem Abfragekontext und Benutzerattributen an
- Nicht-invasive Implementierung – Maskiert Daten in Echtzeit, ohne die Originaldaten zu verändern
- Flexible Maskierungsoptionen – Unterstützt verschiedene Techniken, von der vollständigen Verschleierung bis hin zur formatbewahrenden Maskierung
- Hive-Integration – Arbeitet nahtlos mit bestehenden Hive-Implementierungen
Implementierung der dynamischen Datenmaskierung in DataSunrise für Hive
Mit DataSunrise kann die dynamische Datenmaskierung mithilfe vordefinierter Regeln und Richtlinien eingerichtet werden. Der typische Ablauf umfasst:
- Definition von Maskierungsrichtlinien – Legen Sie fest, welche Spalten maskiert werden sollen und unter welchen Bedingungen.
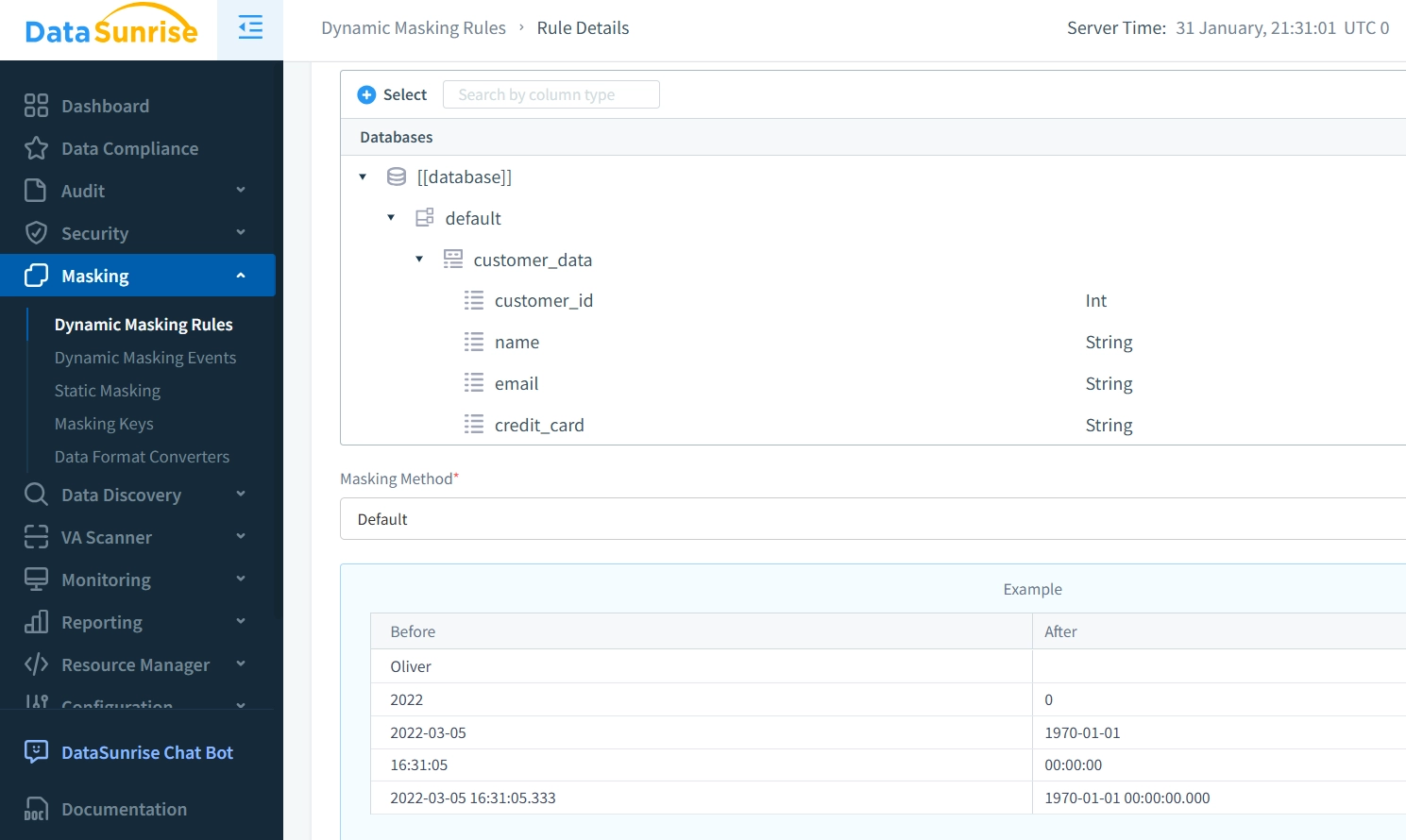
- Konfiguration von Benutzerrollen und Berechtigungen – Weisen Sie unterschiedliche Maskierungsstufen basierend auf Benutzerrollen zu.
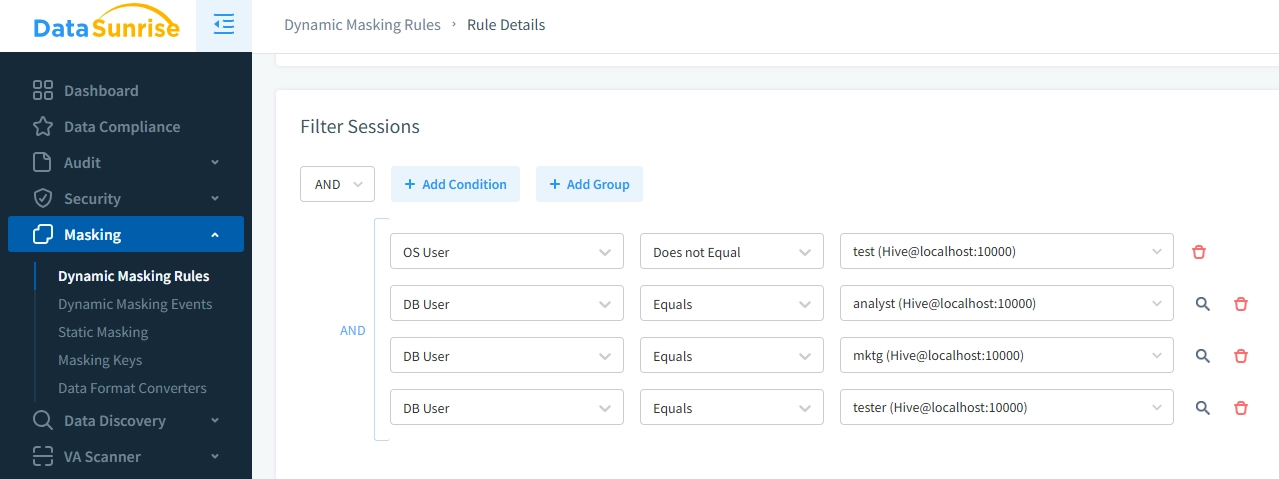
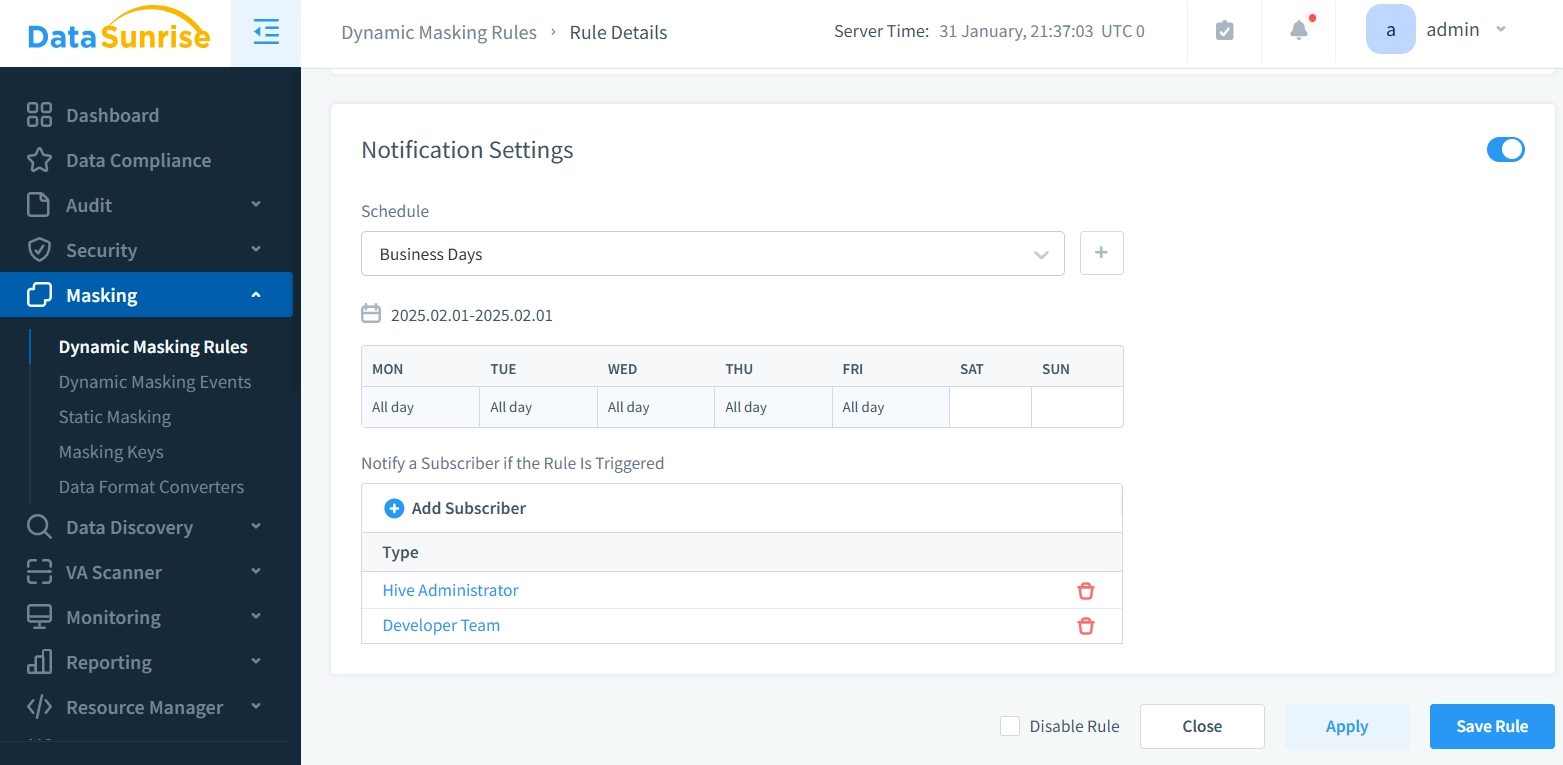
- Konfiguration von Planung und Benachrichtigungen – Richten Sie Echtzeitwarnungen für Sicherheitsereignisse ein und legen Sie fest, wer wie und wann benachrichtigt wird.
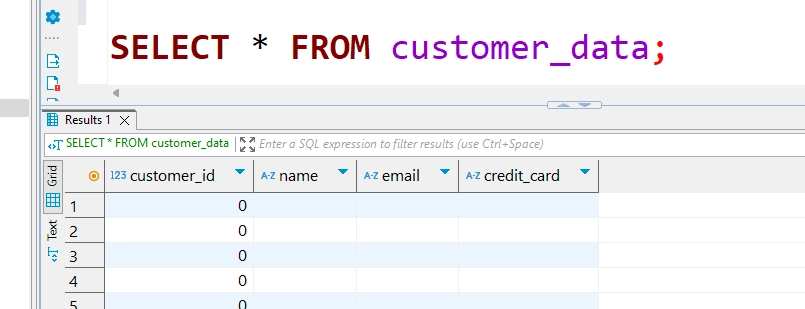
- Testen der dynamischen Datenmaskierungsregel – Die Daten werden dynamisch maskiert, basierend auf den aktiven Sicherheitsrichtlinien, sobald eine Abfrage ausgeführt wird.
Fazit
Die dynamische Datenmaskierung für Apache Hive ist ein wichtiger Bestandteil moderner Datenschutzstrategien. Durch den Einsatz von Tools wie DataSunrise können Organisationen sensible Daten schützen, die Einhaltung gesetzlicher Bestimmungen sicherstellen und das Risiko von Datenpannen reduzieren, ohne die Nutzbarkeit der Daten zu beeinträchtigen.
Die dynamische Datenmaskierung von DataSunrise für Apache Hive bietet eine robuste Lösung für moderne Herausforderungen im Datenschutz. Organisationen können umfassende Datensicherheit nahtlos implementieren und die Einhaltung gesetzlicher Vorschriften (z. B. DSGVO, HIPAA) sicherstellen, während sie die volle Funktionalität der Daten beibehalten.
Erleben Sie die Leistungsfähigkeit fortschrittlicher Datensicherheit in unserer Online-Demo und entdecken Sie, wie DataSunrise Ihre Datensicherheitsstrategie stärken kann.
