NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica
NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica werden immer wichtiger, da Unternehmen ihre Einführung von generativer KI, retrieval-augmented generation (RAG), Feature Engineering und prädiktiver Analytik beschleunigen. Vertica dient häufig als leistungsstarker analytischer Backend für Machine-Learning-Pipelines, großskalige Datenaufbereitung und KI-gesteuerte Anwendungen. Allerdings erhöhen diese selben Workflows das Risiko, regulierte oder vertrauliche Informationen unbeabsichtigt an Modelle, Prompts und nachgelagerte Nutzer offenzulegen. Deshalb müssen Organisationen automatisierte Compliance-Tools einsetzen, die in der Lage sind, den KI-unterstützten Zugriff auf Vertica-Daten zu überwachen, zu maskieren und zu kontrollieren.
Moderne KI-Systeme bringen neue Expositionsmuster mit sich. Große Sprachmodelle, autonome Agenten und Machine-Learning-Workloads generieren oft unvorhersehbare SQL-Abfragen, extrahieren zu umfassende Datensätze oder verarbeiten sensible Felder als Trainingsmaterial. Wenn sie ungeschützt sind, könnten LLMs oder ML-Engines private Informationen in Antworten, Einbettungen oder abgeleiteten Modellartefakten offenlegen – was zu möglichen Verstößen gegen DSGVO (GDPR), HIPAA, PCI DSS oder NIST 800-53 führen kann. Da Vertica von Haus aus keine LLM-bewussten Zugriffskontrollen, dynamische Maskierung, kontextuelle Durchsetzung oder pipeline-übergreifende Prüfungen bietet, müssen Organisationen eine spezialisierte Compliance-Schicht integrieren, die proaktiv agiert, bevor Daten das Modell- oder Pipeline-Layer erreichen.
DataSunrise stellt diese Fähigkeiten bereit. Die Plattform fungiert als zentralisiertes Compliance-Gateway für Vertica, indem sie Sensitive-Data-Discovery, dynamische Maskierung, SQL-Durchsetzung und automatisierte Prüfungen anbietet. Zusammen bilden diese Funktionen die Grundlage der NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica.
Warum Vertica LLM-Bewusste Compliance-Automatisierung Erfordert
KI-gesteuerte Workloads bringen Compliance-Herausforderungen mit sich, die traditionelle Governance-Systeme nicht adressieren können. Beispielsweise kann von einem LLM generiertes SQL unbeabsichtigt übermäßige Mengen sensibler Daten anfordern. Zudem extrahieren ETL-Pipelines Trainingskorpora aus Vertica, ohne zu überprüfen, ob die zugrundeliegenden Felder PII (personenbezogene Daten) oder PHI (geschützte Gesundheitsinformationen) enthalten. Gleichzeitig vektorisieren RAG-Architekturen oft Textspalten – darunter auch mit persönlichen Identifikatoren – in Einbettungen, was das Nachverfolgen der Datenherkunft extrem erschwert.
Darüber hinaus verstärken die Architektur von Vertica diese Risiken. Funktionen wie Projektionen, ROS/WOS-Speicher und breite analytische Schemata verteilen sensible Werte über mehrere physische Strukturen. Da Vertica als leistungsstarke analytische Plattform für eine Vielzahl von Workloads dient – von BI-Dashboards bis hin zu ML-Frameworks wie VerticaPy – können Compliance-Lücken schnell auf mehrere Teams und Systeme übergreifen.
Um Compliance-Verstöße zu vermeiden, benötigen Organisationen NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica, die automatisieren:
- die Erkennung sensibler Vertica-Spalten vor ML-Training oder RAG-Einspielung,
- dynamische Maskierung von hochriskanten Attributen für NLP- und LLM-Workloads,
- SQL-Kontext-Durchsetzung, um unsafe oder übermäßige durch KI generierte Abfragen zu verhindern,
- automatisierte Prüfungen aller KI-generierten Zugriffe auf Vertica,
- Überwachung zur Minimierung des Risikos von LLM-Halluzinationen, die private Werte offenlegen.
Folglich können ohne automatisierte Kontrollen KI-Pipelines unbeabsichtigt unmaskierte Daten aufnehmen oder während der Inferenz vertrauliche Felder preisgeben.
NLP-, LLM- & ML-Daten-Compliance-Architektur für Vertica
Das untenstehende Diagramm veranschaulicht, wie NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica als Sicherheits- und Transformationsebene zwischen Vertica und KI-Workloads fungieren. Jede LLM-, ML-, NLP- und ETL-Anfrage fließt durch diese Durchsetzungsschicht und gewährleistet konsistente Maskierung, Prüfung und SQL-Inspektion.

Diese Architektur unterstützt:
- LLM-Assistenten, die SQL dynamisch erzeugen,
- RAG-Pipelines, die Vertica-Tabellen für Retrieval abfragen,
- Feature-Engineering-Prozesse, die sensible Spalten lesen,
- Batch-ML-Training, das Datensätze direkt aus Vertica zieht.
Da sämtliche Durchsetzungen erfolgen, bevor Vertica-Daten KI-Systeme erreichen, behalten Organisationen vollständige Transparenz, Konsistenz und Governance über jeden NLP-, LLM- und ML-Workflow.
Erkennung sensibler Daten in Vertica AI-Pipelines
Effektive Automatisierung beginnt mit der Erkennung. NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica müssen alle sensiblen Felder identifizieren, die Trainingsdaten, Vektor-Einbettungen, Prompts oder Inferenz-Ausgaben beeinflussen könnten. DataSunrises Sensitive Data Discovery scannt Vertica-Tabellen und erkennt automatisch PII, PHI, finanzielle Werte, Authentifizierungstokens und Freitextspalten mit regulierten Inhalten.
Dieser proaktive Erkennungsmechanismus verhindert eine Kontamination der Trainingsdaten mit sensiblen Informationen. Darüber hinaus integrieren sich die Erkennungsergebnisse direkt in Maskierungs- und SQL-Durchsetzungs-Module, sodass neu entdeckte Felder automatisch die erforderlichen Compliance-Schutzmaßnahmen übernehmen.
Dynamische Maskierung für NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica
Dynamische Maskierung ist eines der Kern-Features der NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica. Wenn KI-Systeme SQL generieren, spezifizieren sie selten, welche Spalten geschützt bleiben müssen. Aufgrund dieser Unvorhersehbarkeit muss die Maskierung automatisch – basierend auf Richtlinien – erfolgen und nicht auf Anwendungsebene.
Der folgende Screenshot zeigt, wie Administratoren die dynamische Maskierung für Vertica-Felder konfigurieren, die häufig von ML- und NLP-Pipelines genutzt werden:
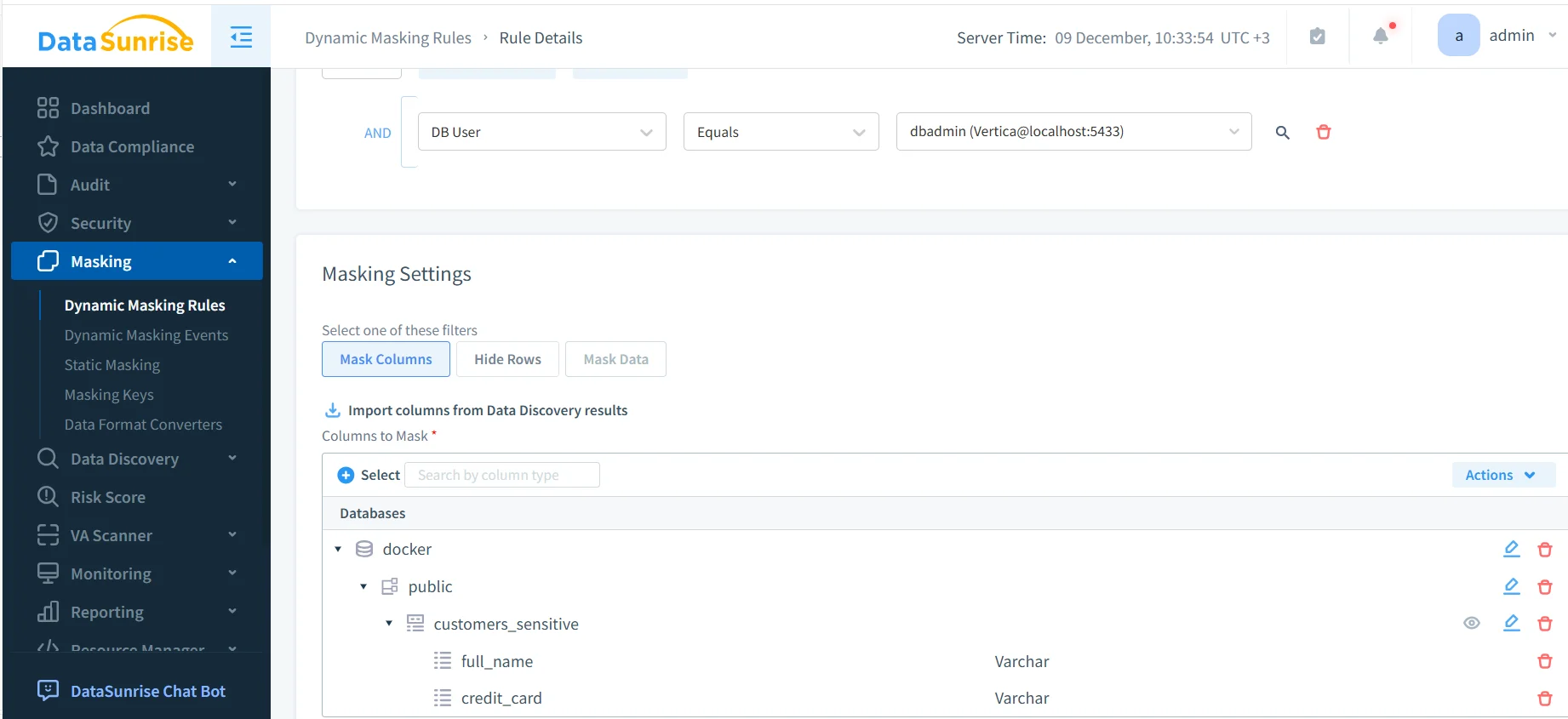
Diese automatisierte Maskierung schützt sensible Attribute während:
- der Prompt-Generierung für LLM-Anwendungen,
- RAG-basierten Abruf-Workflows, die Vektorspeicher befüllen,
- ETL-Extraktionen für ML Feature Stores,
- der Konstruktion von Trainingsdatensätzen,
- der Datenexploration von Data Scientists in Notebooks.
Außerdem verhindert die Maskierung, dass KI-Modelle Originalwerte in Antworten, Einbettungen oder Trainingsartefakten leaken – konform mit den DSGVO-Pseudonymisierungsregeln und PCI DSS-Anforderungen.
SQL-Durchsetzung für NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica
Von KI generiertes SQL kann erhebliche Risiken bergen. LLMs erzeugen häufig Abfragen mit uneingeschränkten JOINs, SELECT *-Scans oder schemabezogenen Extraktionen. Außerdem können KI-Agenten versehentlich Änderungsbefehle wie DROP TABLE oder ALTER TABLE generieren. Um diese Herausforderungen zu meistern, setzen NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica kontextbezogene SQL-Regeln durch, bevor die Abfrage Vertica erreicht.
Diese Durchsetzung verhindert:
- Prompt-Injection-Angriffe, die sensible oder eingeschränkte Tabellen extrahieren wollen,
- hohe Scan-Volumina, die komplette Datensätze einem LLM zugänglich machen,
- Schemaveränderungen, die durch autonome Agenten ausgelöst werden,
- übermäßige Datenabfragen während des ML-Feature-Engineering.
Mit dieser Automatisierung gewinnen Organisationen Sicherheit, dass LLM-generiertes SQL die Richtliniengrenzen nicht überschreiten kann.
Automatisierte Prüfung für NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica
Umfassende Prüfung ist essentiell für verantwortungsvolle KI-Governance. NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica müssen vollständige Einblicke darin bieten, wie KI-Agenten, Pipelines und Anwendungen mit sensiblen Vertica-Daten interagieren. Manuelles Logging genügt nicht, da KI-Workloads autonom Tausende Abfragen erzeugen.
DataSunrise erfasst automatisch SQL-Aktivitäten, Sitzungswechsel, Maskierungsergebnisse und Regel-Auslöser. Der folgende Screenshot zeigt eine einheitliche Prüfspur, die sowohl für operative Reviews als auch für regulatorische Nachweise geeignet ist.
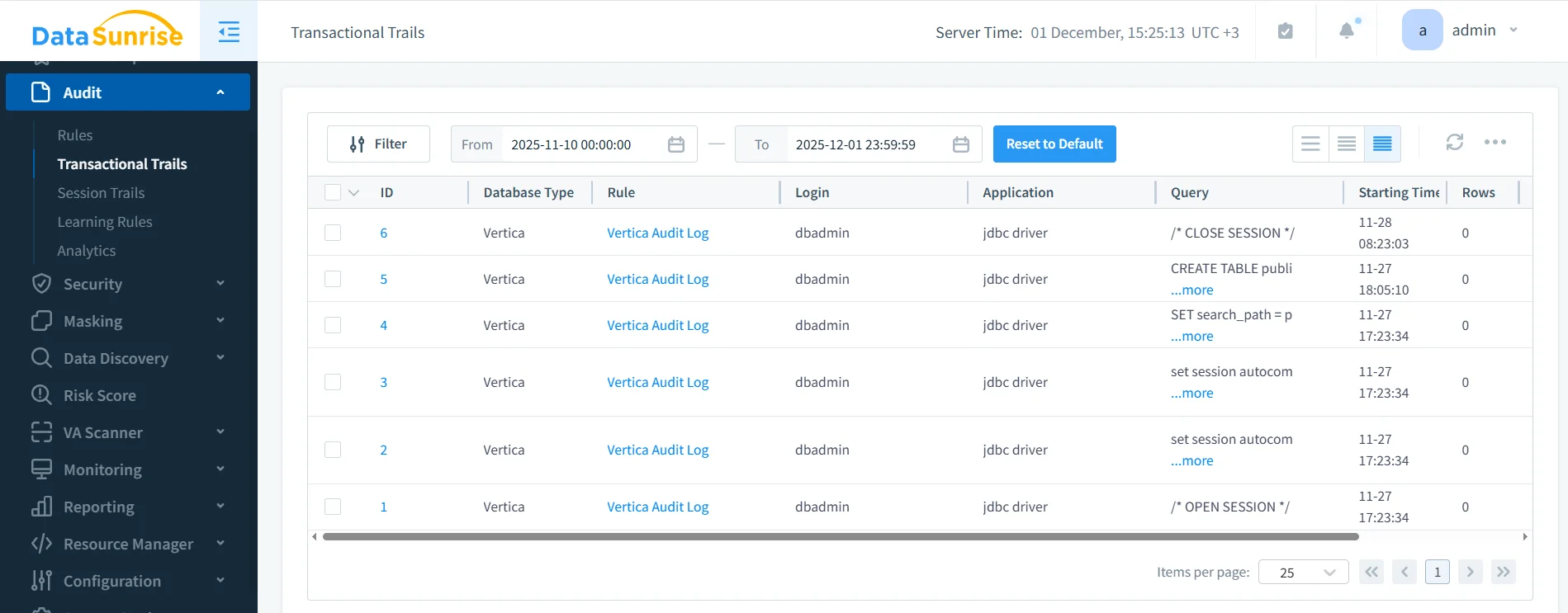
Diese Protokolle ermöglichen es Compliance-Teams:
- nachzuvollziehen, wie ein von einem LLM erstellter Datensatz generiert wurde,
- zu validieren, dass sensible Felder während der Aufnahme maskiert waren,
- anormales oder risikoreiches Modellverhalten zu untersuchen,
- Erklärbarkeitsnachweise für regulierte KI-Implementierungen zu erzeugen.
Da die Prüfdaten zentralisiert sind, behalten Organisationen konsistente Kontrolle über alle LLM-, NLP-, ETL- und ML-Interaktionen.
Vergleich: Vertica vs. NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica
| AI-Compliance-Anforderung | Vertica Native Fähigkeiten | NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica |
|---|---|---|
| PII/PHI-Erkennung vor Training | Manuelle Überprüfung | Automatisierte Sensitive Data Discovery |
| Dynamische Maskierung für KI-Abfragen | Nicht verfügbar | Echtzeit-Maskierung |
| LLM SQL-Durchsetzung | Nur RBAC | Regelbasierte SQL-Filterung |
| Zentrale Prüflogs | Verteilte Logs | Einheitliche Prüfspur |
| Trainingsdaten-Herleitbarkeit | Manuelle Nachverfolgung | Automatisierte KI-bewusste Korrelation |
Fazit
NLP-, LLM- & ML-Daten-Compliance-Tools für Vertica ermöglichen es Organisationen, KI-Technologien sicher und verantwortungsvoll einzusetzen. Dynamische Maskierung verhindert die Offenlegung sensibler Werte. SQL-Durchsetzung schützt vor unsicheren oder unbeabsichtigten Abfragen, die von autonomen Systemen generiert werden. Automatisierte Prüfungen sorgen für vollständige Transparenz und Nachweise bei regulatorischen Überprüfungen. Zusammen bilden diese Kontrollen einen End-to-End-Compliance-Automatisierungsrahmen, der Vertica-Daten in allen NLP-, LLM- und ML-Workloads schützt.
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen