
Datenschutz‑verbesserung mit statischer Datenmaskierung für Amazon Aurora

Einleitung
Da Unternehmen zunehmend auf Cloud-Datenbanken wie Amazon Aurora angewiesen sind, wächst der Bedarf an robusten Datensicherheitsmaßnahmen. Eine wesentliche Technik in diesem Bereich ist die statische Datenmaskierung. Dieser Prozess hilft Organisationen, vertrauliche Daten zu schützen und gleichzeitig realistische Testumgebungen bereitzustellen. Wussten Sie, dass laut einer aktuellen Studie von Verizon 64% aller kompromittierten Daten persönliche Informationen sind? Diese erschreckende Statistik unterstreicht die Bedeutung der Implementierung starker Datensicherheitsmaßnahmen, einschließlich der statischen Datenmaskierung.
Was ist statische Datenmaskierung?
Statische Datenmaskierung ist eine Datensicherheitstechnik, die eine Kopie einer Produktionsdatenbank erstellt, wobei sensible Informationen durch realistische, aber fiktive Daten ersetzt werden. Dieser Ansatz ermöglicht es Organisationen, maskierte Daten für Tests, Entwicklungen und Analysen zu verwenden, ohne tatsächliche vertrauliche Informationen preiszugeben.
Zentrale Vorteile der statischen Datenmaskierung sind:
- Verbesserte Datensicherheit
- Einhaltung von Datenschutzvorschriften
- Reduziertes Risiko von Datenpannen
- Verbesserte Testgenauigkeit
Amazon Aurora-Funktionen für Datenmaskierung
Testdaten
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50), phone VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email, phone) values (1, 'Alica', 'Collyer', '[email protected]', '676-612-4979'); … insert into MOCK_DATA (id, first_name, last_name, email, phone) values (10, 'Nevsa', 'Justun', '[email protected]', '997-928-5900');
Amazon Aurora selbst verfügt nicht über eingebaute Transformations- oder Maskierungsregeln. Stattdessen müssen Sie die Maskierungslogik mithilfe von SQL-Abfragen oder Funktionen implementieren. Hier sind einige praktische Ansätze (sowohl dynamische als auch statische Maskierung):
SQL-Abfragen
Verwenden Sie SQL, um maskierte Versionen Ihrer Daten zu erstellen. Zum Beispiel:
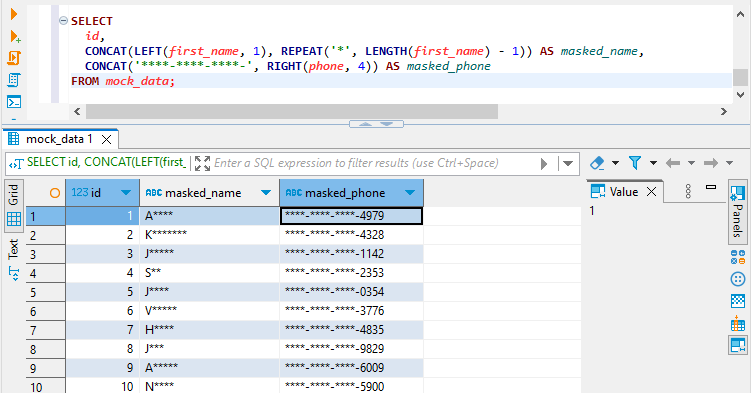
SELECT
id,
CONCAT(LEFT(first_name, 1), REPEAT('*', LENGTH(first_name) - 1)) AS masked_name,
CONCAT('****-****-****-', RIGHT(phone, 4)) AS masked_phone
FROM mock_data;
Benutzerdefinierte Funktionen
Erstellen Sie benutzerdefinierte Funktionen für komplexere Maskierungen oder um diese in der statischen Tabelle einzufügen:
CREATE OR REPLACE FUNCTION mask_email(email VARCHAR(255))
RETURNS VARCHAR(255) AS $$
BEGIN
RETURN CONCAT(LEFT(email, 1), '***', SUBSTRING(email FROM POSITION('@' IN email)));
END;
$$ LANGUAGE plpgsql;
SELECT mask_email('[email protected]') AS masked_email;
SELECT id, mask_email(email) AS masked_email
FROM MOCK_DATA
LIMIT 5;
Diese Methoden ermöglichen es Ihnen, dynamische Datenmaskierung direkt innerhalb von Aurora zu implementieren, ohne auf externe Transformationsregeln angewiesen zu sein. Sie sind unkomplizierter und direkt auf Aurora-Datenbanken anwendbar.
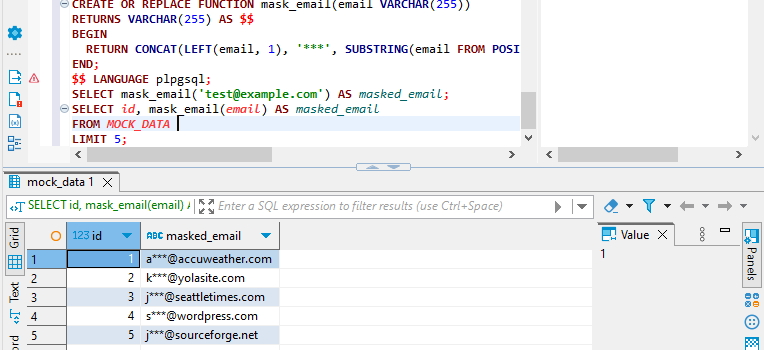
Tabelle kopieren
Um die statische Datenmaskierung in Aurora PostgreSQL umzusetzen, können Sie die Daten einfach kopieren:
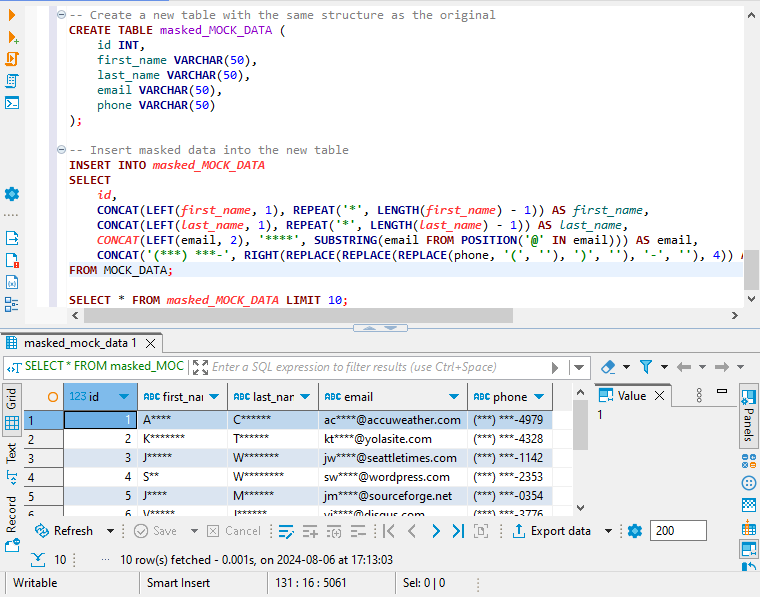
-- Erstellen Sie eine neue Tabelle mit derselben Struktur wie die Originaltabelle
CREATE TABLE masked_MOCK_DATA (
id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50),
phone VARCHAR(50)
);
-- Fügen Sie maskierte Daten in die neue Tabelle ein
INSERT INTO masked_MOCK_DATA
SELECT
id,
CONCAT(LEFT(first_name, 1), REPEAT('*', LENGTH(first_name) - 1)) AS first_name,
CONCAT(LEFT(last_name, 1), REPEAT('*', LENGTH(last_name) - 1)) AS last_name,
CONCAT(LEFT(email, 2), '****', SUBSTRING(email FROM POSITION('@' IN email))) AS email,
CONCAT('(***) ***-', RIGHT(REPLACE(REPLACE(REPLACE(phone, '(', ''), ')', ''), '-', ''), 4)) AS phone
FROM MOCK_DATA;
Um eine Vorschau der neu maskierten Daten anzuzeigen, führen Sie die folgende Abfrage aus:
SELECT * FROM masked_MOCK_DATA LIMIT 10;
Für fortgeschrittene oder automatisierte Maskierung sollten Sie den Einsatz von Drittanbieter-Tools wie DataSunrise in Erwägung ziehen, die sich in Aurora integrieren und zusätzliche Maskierungsfunktionen bereitstellen.
Einrichtung statischer Maskierungsaufgaben in DataSunrise
DataSunrise bietet eine benutzerfreundliche Oberfläche zur Einrichtung statischer Datenmaskierungsaufgaben für Amazon Aurora. Hier ist eine Schritt-für-Schritt-Anleitung:
- Erstellen Sie eine Aurora-Instanz in DataSunrise
- Navigieren Sie zum Modul Datenmaskierung
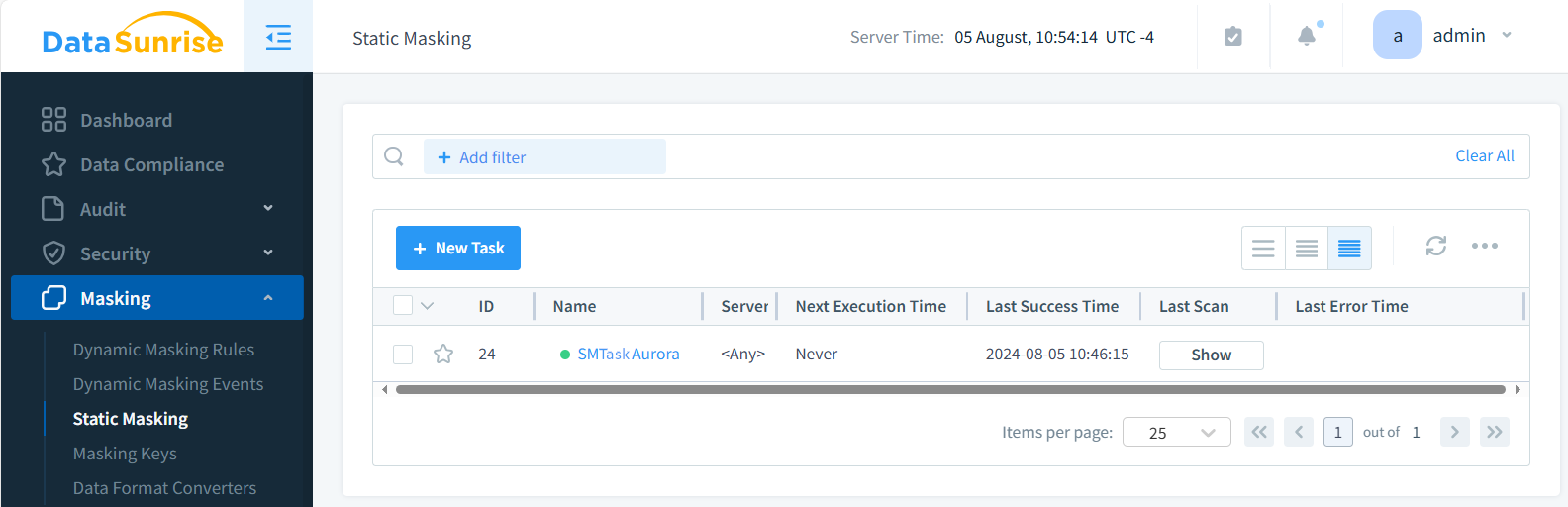
- Erstellen Sie eine neue statische Maskierungsaufgabe (SMTaskAurora im Bild unten)
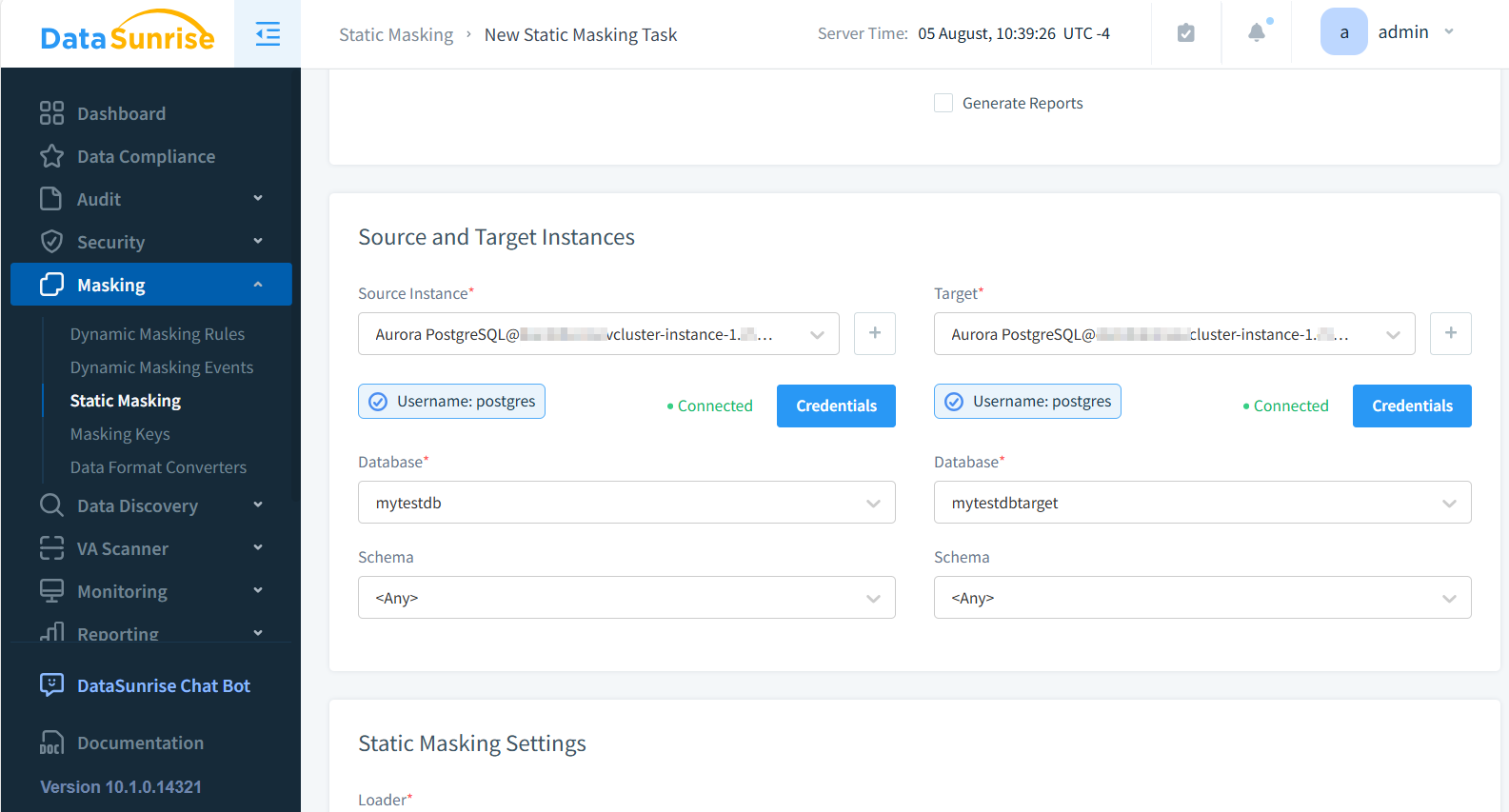
- Wählen Sie die Quell- und Zieldatenbanken aus
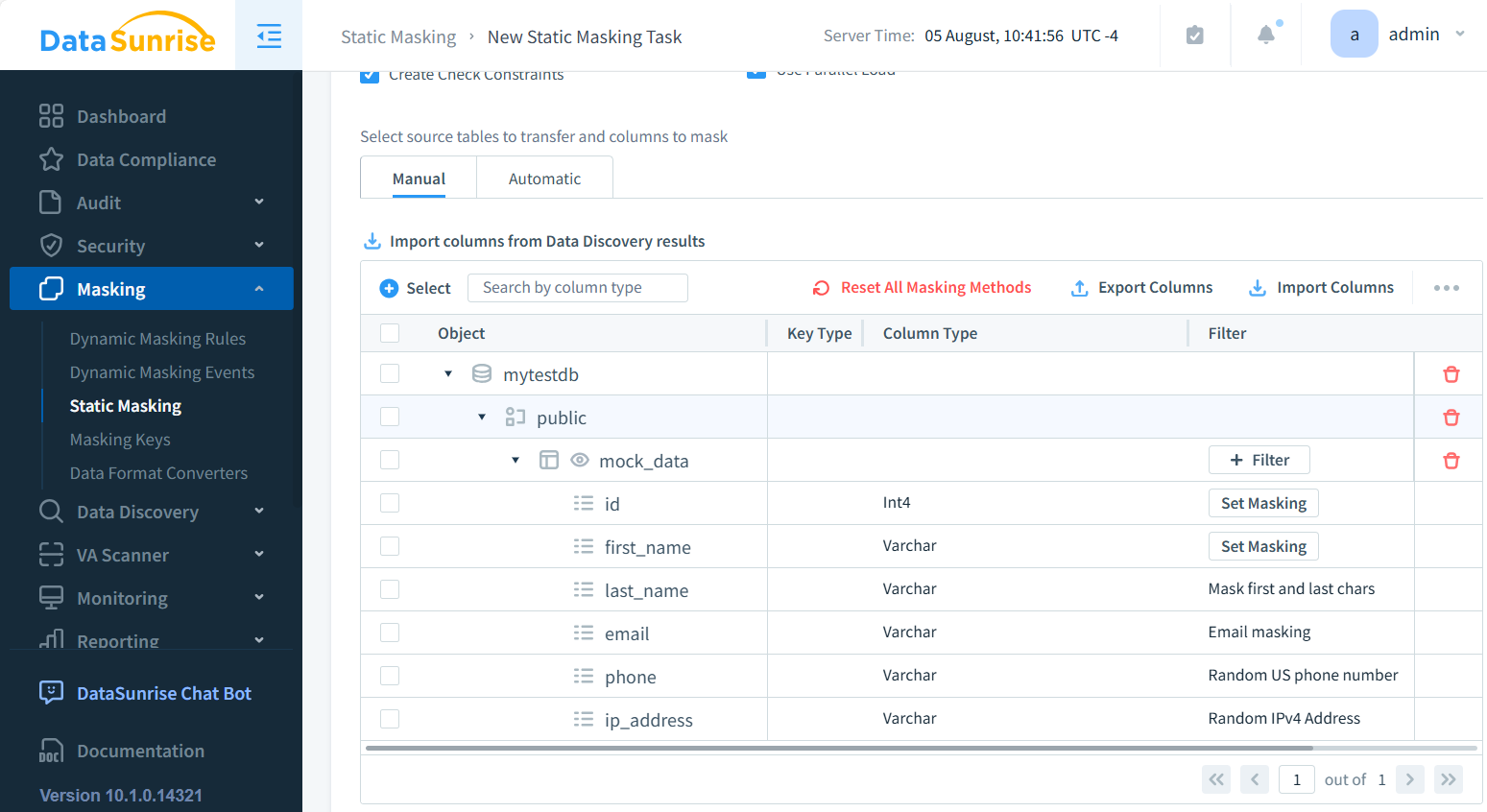
- Wählen Sie die Tabellen (im Beispiel mock_data) und die zu maskierenden Spalten (last_name, email, phone und ip_address) aus
- Wenden Sie die Maskierungsmethode an (z. B. Substitution, Mischen, formatwahrende Verschlüsselung)
- Planen Sie die Aufgabenausführung (standardmäßig manuell)
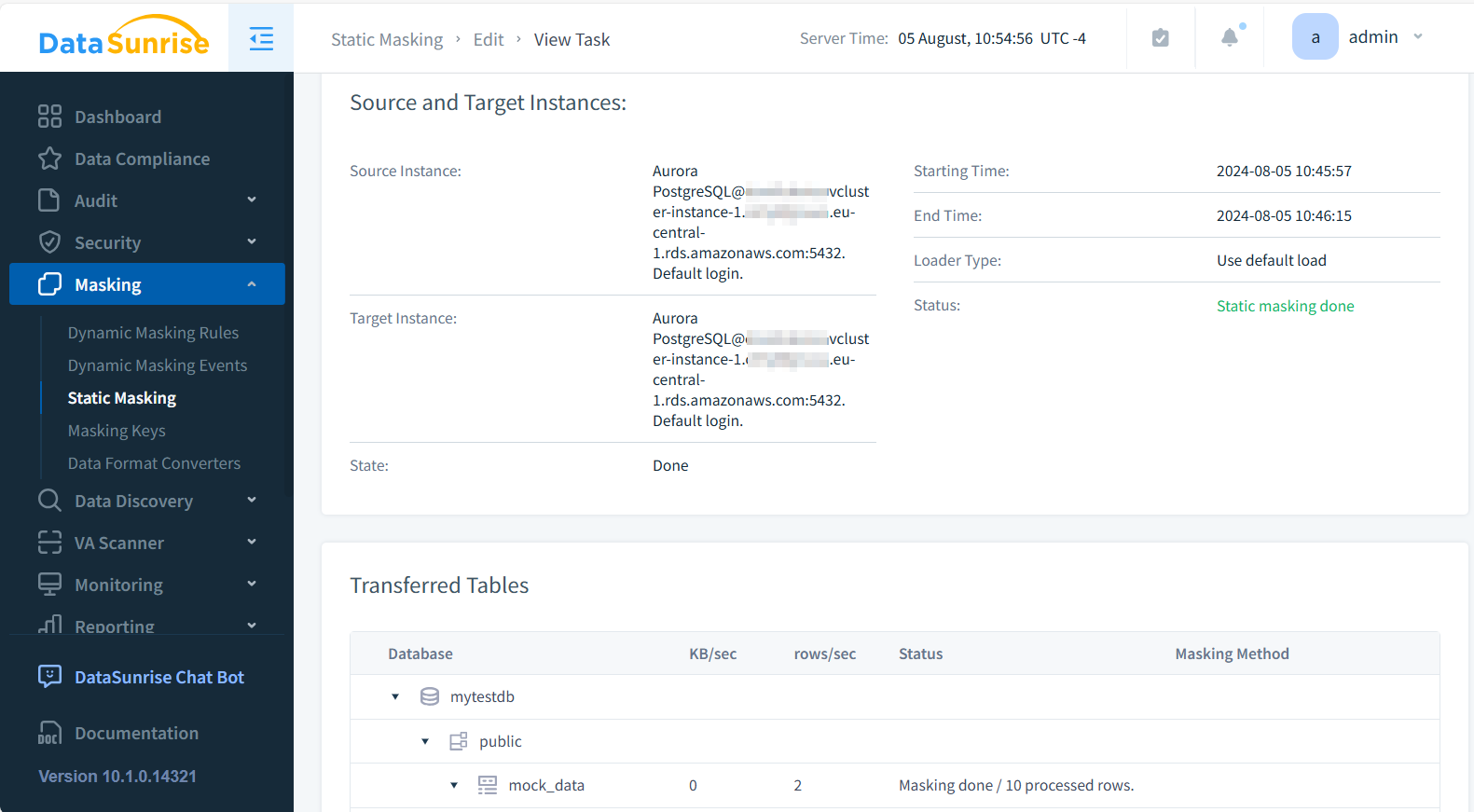
- Führen Sie die Aufgabe aus und überprüfen Sie die Ergebnisse
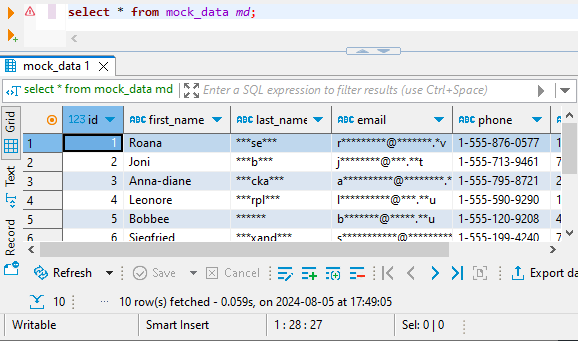
In DBeaver können Sie nun die maskierten Daten aus der Zieldatenbank abfragen:
Nachverfolgung der Ausführungsergebnisse
Nach der Einrichtung einer statischen Maskierungsaufgabe ist es entscheidend, deren Ausführung zu überwachen und die Ergebnisse zu überprüfen. DataSunrise bietet hierfür umfassende Protokollierungs- und Berichtsfunktionen:
- Überprüfen Sie den Ausführungsstatus der Aufgabe im DataSunrise-Dashboard
- Sehen Sie sich detaillierte Protokolle zu Fehlern oder Warnungen an
- Vergleichen Sie Beispieldaten aus Quell- und Zieldatenbanken
- Erstellen Sie Berichte über maskierte Spalten und Datenverteilung
Datengetriebene Ansätze für Anwendungstests
Beim datengetriebenen Anwendungstest stehen zwei Hauptansätze zur Verfügung:
1. Testen mit maskierten Daten
Dieser Ansatz nutzt die statische Datenmaskierung, um eine realistische Testumgebung mit anonymisierten Produktionsdaten zu schaffen. Er ist ideal, um Datenbeziehungen und -verteilungen aufrechtzuerhalten und gleichzeitig sensible Informationen zu schützen.
2. Testen mit synthetischen Daten
Synthetische Daten werden künstlich erzeugt, um die Eigenschaften realer Daten zu imitieren. Dieser Ansatz bietet mehr Flexibilität, stellt jedoch möglicherweise nicht alle Randfälle dar, die in Produktionsdaten vorhanden sind.
Beide Methoden haben ihre Vorzüge; die Wahl hängt von den spezifischen Testanforderungen und dem Datenschutzniveau ab.
Best Practices für statische Datenmaskierung in Amazon Aurora
Um die Effektivität der statischen Datenmaskierung für Amazon Aurora zu maximieren, sollten Sie folgende Best Practices berücksichtigen:
- Identifizieren Sie alle sensiblen Datenelemente in Ihrer Datenbank
- Wählen Sie geeignete Maskierungstechniken für jeden Datentyp
- Stellen Sie Datenkonsistenz über zusammenhängende Tabellen sicher
- Aktualisieren Sie Maskierungsregeln regelmäßig, um auf neue Datentypen oder Vorschriften zu reagieren
- Kombinieren Sie statische Maskierung mit dynamischer Maskierung für einen umfassenden Schutz
- Implementieren Sie strenge Zugriffskontrollen für maskierte Datenbanken
Fazit
Die statische Datenmaskierung für Amazon Aurora ist eine wesentliche Technik, um sensible Daten zu schützen und gleichzeitig effektive Test- und Entwicklungsprozesse zu ermöglichen. Durch den Einsatz von Tools wie DataSunrise können Organisationen robuste Maskierungsstrategien implementieren, die den Spagat zwischen Datenverfügbarkeit, Sicherheit und Compliance meistern.
Da Datenpannen weiterhin erhebliche Risiken darstellen, ist die Umsetzung starker Datenschutzmaßnahmen – einschließlich der statischen Datenmaskierung – nicht mehr optional, sondern eine Notwendigkeit für ein verantwortungsbewusstes Datenmanagement.
DataSunrise bietet modernste Tools für die Datenbanksicherheit, einschließlich Audit, Datenerkennung und fortschrittlicher Maskierungsfunktionen. Unsere benutzerfreundliche Oberfläche ermöglicht es Ihnen, umfassende Datenschutzstrategien für Amazon Aurora und andere Datenbankplattformen umzusetzen. Besuchen Sie unsere Website für eine Online-Demo und erfahren Sie, wie wir helfen können, Ihre wertvollen Datenbestände zu schützen.
