
Mejorando la Seguridad con Enmascaramiento de Datos Estático para Amazon Redshift

Introducción
La era digital está en pleno auge, con 67% de la población mundial utilizando internet. Esta adopción generalizada ha catalizado un cambio significativo, trasladando innumerables procesos y servicios en línea y transformando nuestra forma de vivir, trabajar e interactuar. Las organizaciones deben equilibrar la utilidad de los datos con el cumplimiento regulatorio y las preocupaciones sobre privacidad. Una solución efectiva es el enmascaramiento de datos estático para Amazon Redshift. Esta técnica ayuda a proteger los datos confidenciales al mismo tiempo que mantiene su utilidad para el desarrollo y las pruebas.
Exploremos cómo el enmascaramiento de datos estático puede ayudar a asegurar tu entorno de Amazon Redshift.
Entendiendo el Enmascaramiento de Datos Estático
¿Qué es el Enmascaramiento de Datos Estático?
El enmascaramiento de datos estático es un proceso que crea una copia separada y enmascarada de los datos sensibles. Este enfoque garantiza que los datos originales permanezcan inalterados mientras se proporciona una versión segura para entornos no productivos.
¿Por Qué Usar Enmascaramiento de Datos Estático?
- Cumplimiento regulatorio
- Reducción del riesgo de violaciones de datos
- Entornos de desarrollo y prueba más seguros
- Mantenimiento de la integridad de los datos
Capacidades de Amazon Redshift para el Enmascaramiento de Datos Estático
Amazon Redshift ofrece funciones integradas y funciones definidas por el usuario (UDF) para implementar el enmascaramiento de datos. Veamos algunas capacidades clave.
Los ejemplos proporcionados arriba demuestran técnicas de enmascaramiento de datos, pero no crean tablas separadas con datos enmascarados. Estos métodos son similares a los utilizados en el enmascaramiento de datos dinámico nativo. Para crear tablas permanentemente ofuscadas, consulta la sección ‘Implementando Enmascaramiento de Datos Estático’ a continuación.
Funciones Integradas
Redshift ofrece varias funciones integradas para operaciones básicas de enmascaramiento. Una función comúnmente usada es REGEXP_REPLACE.
Ejemplo:
SELECT REGEXP_REPLACE(email, '(.*)@', '****@') AS masked_email FROM users;
Esta consulta enmascara la parte local de las direcciones de correo electrónico, reemplazándola con asteriscos.
Funciones Definidas por el Usuario (UDF)
Para requerimientos de enmascaramiento más complejos, Redshift permite crear UDF usando Python. Aquí está un ejemplo de una UDF que enmascara direcciones de correo electrónico:
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;
Para usar esta función:
SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
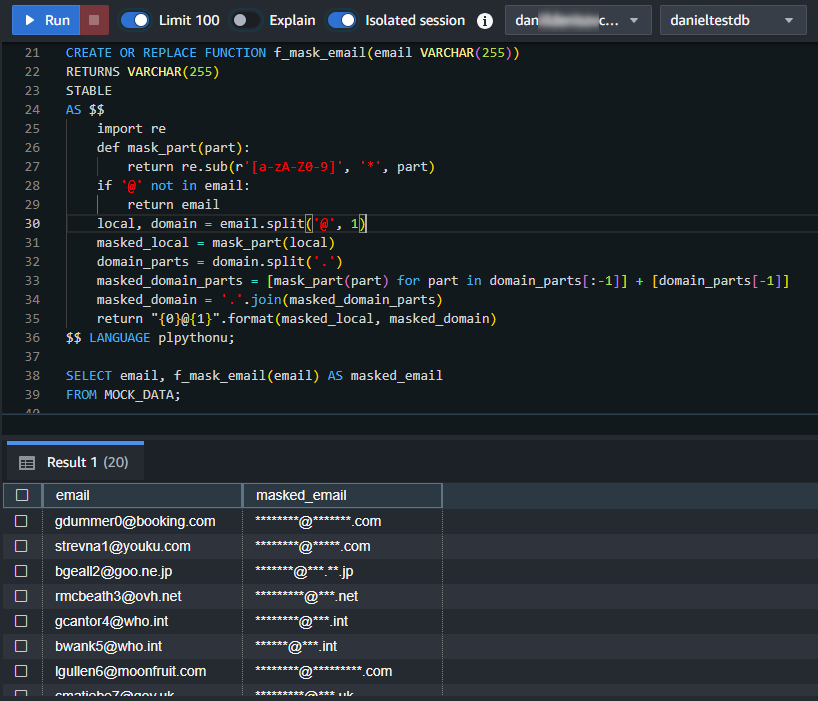
Las funciones en Python mejoran considerablemente las capacidades de enmascaramiento y procesamiento de datos de Redshift. Permiten implementar cifrado preservado de formato y procedimientos de enmascaramiento complejos. Con Python, puedes crear algoritmos de enmascaramiento personalizados adaptados a tus necesidades específicas.
Implementando Enmascaramiento de Datos Estático en Redshift
Ahora que entendemos los conceptos básicos, vamos a ver cómo implementar el enmascaramiento de datos estático en Redshift.
Paso 1: Identificar los Datos Sensibles
Primero, identifica qué columnas contienen información sensible que requiere enmascaramiento. Esto puede incluir:
- Información Personalmente Identificable (PII)
- Datos financieros
- Registros de salud
Paso 2: Crear Funciones de Enmascaramiento
Desarrolla funciones de enmascaramiento para cada tipo de datos que necesites proteger. Ya hemos visto un ejemplo para direcciones de correo electrónico.
Paso 3: Crear una Tabla Enmascarada
Crea una nueva tabla con datos enmascarados:
CREATE TABLE masked_mock_data AS SELECT id, f_mask_email(email) AS email, first_name, last_name FROM Mock_data;
Paso 4: Verificar los Datos Enmascarados
Revisa los resultados para asegurar un enmascaramiento adecuado:
SELECT * FROM masked_mock_data;
Enmascaramiento de Datos Estático con DataSunrise
Para usar DataSunrise para el enmascaramiento estático:
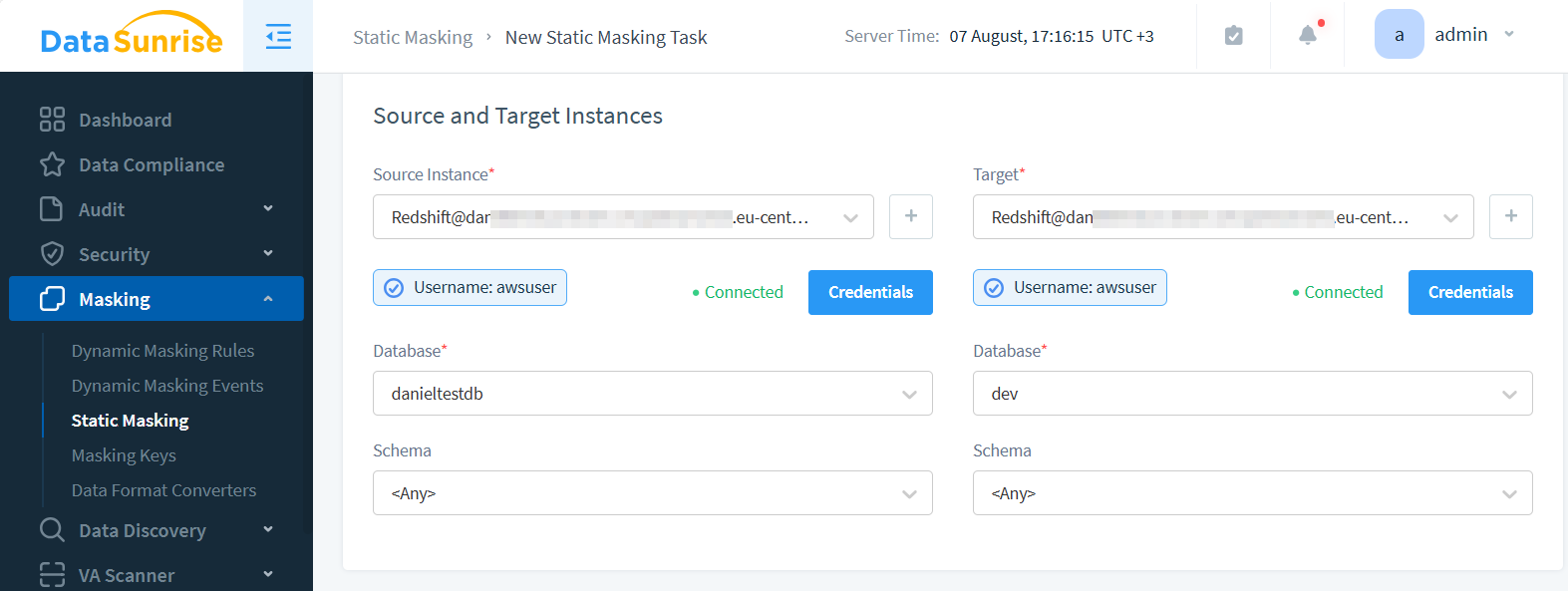
- Configura una conexión a tu clúster de Redshift
- Crea una Tarea de enmascaramiento en la Web-UI
- Selecciona las bases de datos fuente y destino.
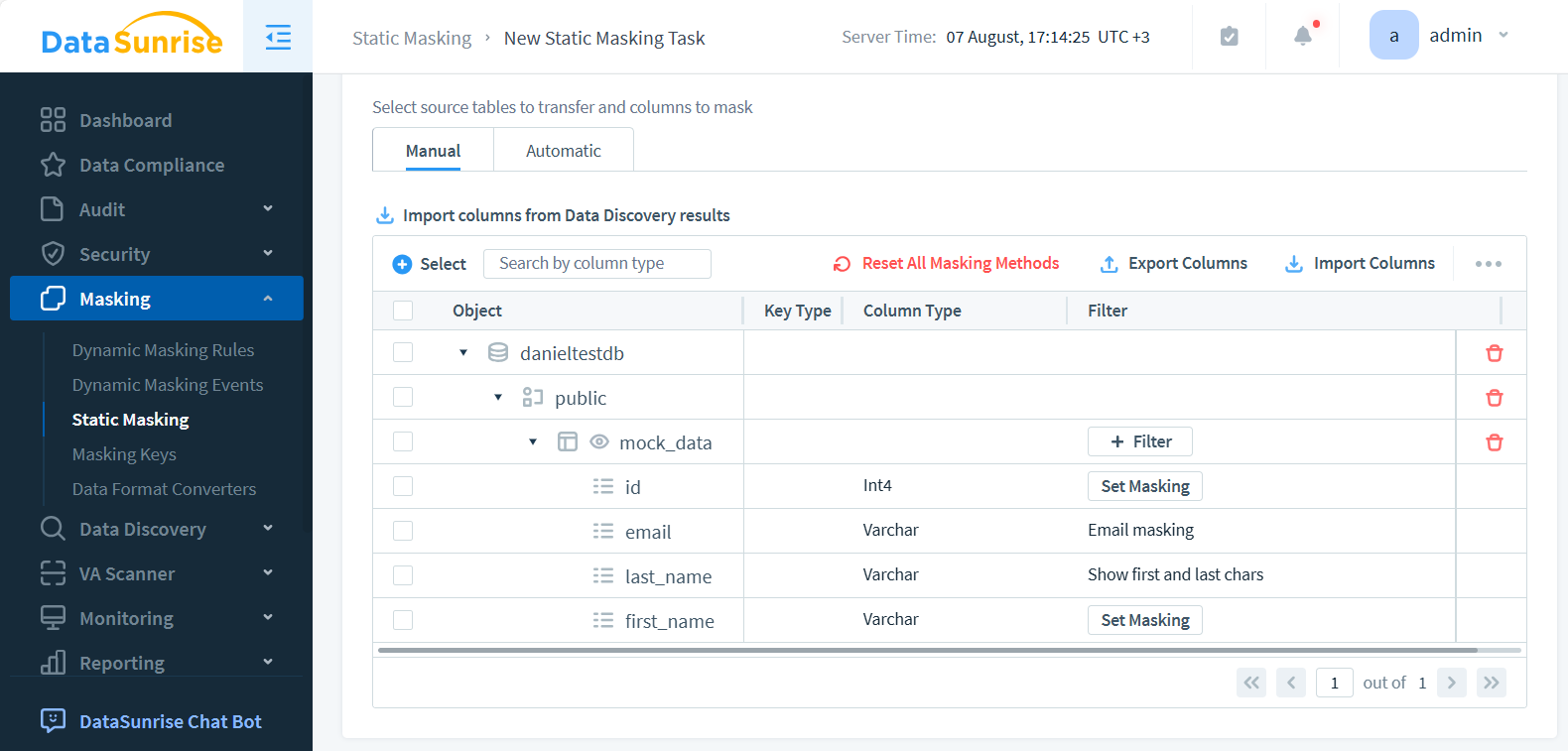
- Selecciona los objetos de la base de datos destino que deseas enmascarar
- Guarda y comienza la Tarea
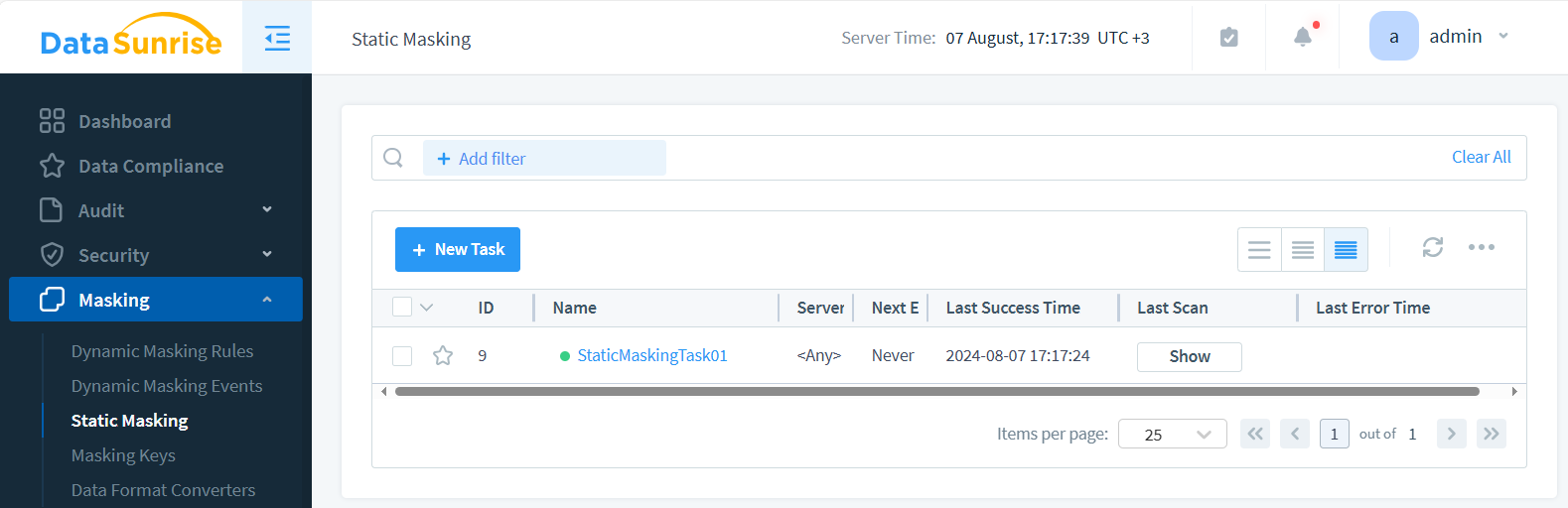
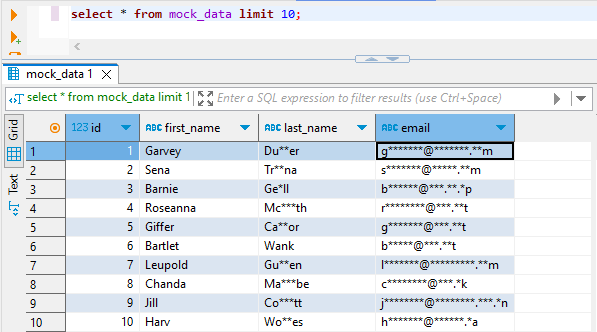
El resultado en la tabla destino puede verse como sigue (consultado en DBeaver):
Métodos de Enmascaramiento de DataSunrise
DataSunrise proporciona una suite comprensiva de técnicas de enmascaramiento de datos. Vamos a explorar algunos de los métodos más poderosos y comúnmente utilizados:
- Encriptación Preservada de Formato mantiene el formato original de los datos mientras los encripta, asegurando que los datos continúen siendo utilizables después de la encriptación. Esto significa que los valores encriptados se verán similares a los datos originales, haciendo que sea más fácil trabajar con ellos y analizarlos. Esto es especialmente útil en situaciones donde el formato de los datos es importante para los procesos o propósitos de visualización.
- Valor de Cadena Fija es una técnica utilizada para reemplazar datos sensibles con una cadena predefinida. Esto puede ser útil para enmascarar información sensible como números de tarjetas de crédito o números de seguridad social. Al reemplazar los datos reales con una cadena fija, se protege la información sensible contra el acceso o visualización no autorizada.
- Valor Nulo es otro método de protección de datos sensibles al reemplazarlos con un valor NULL. Esto elimina la información sensible del conjunto de datos, de modo que nadie pueda acceder o recuperar los datos originales. Este método puede no mantener el formato de los datos como la Encriptación Preservada de Formato, pero mantiene efectiva la seguridad de la información sensible.
DataSunrise ofrece una amplia gama de métodos de enmascaramiento, brindándote opciones flexibles para proteger tus datos sin sacrificar la utilidad. Con más de 20 técnicas distintas disponibles, puedes ajustar tu estrategia de protección de datos para satisfacer necesidades específicas.
Beneficios del Enmascaramiento de Datos Estático para Amazon Redshift
Implementar el enmascaramiento de datos estático en Redshift ofrece varias ventajas:
- Mejora de la seguridad de los datos
- Facilitación del cumplimiento normativo
- Reducción del riesgo de exposición accidental de datos
- Mejora de los procesos de desarrollo y prueba
- Mantenimiento de la utilidad de los datos
Al enmascarar datos sensibles, puedes compartir información con confianza en toda tu organización sin comprometer la seguridad.
Desafíos y Consideraciones
Aunque el enmascaramiento de datos estático es beneficioso, hay algunos desafíos a considerar:
- Impacto en el rendimiento durante el proceso de enmascaramiento
- Mantenimiento de la integridad referencial en los datos enmascarados
- Garantía de enmascaramiento consistente en tablas relacionadas
- Equilibrio entre la usabilidad de los datos y los requisitos de seguridad
Abordar estos desafíos requiere una planificación e implementación cuidadosa.
Conclusión
El enmascaramiento de datos estático para Amazon Redshift es una herramienta poderosa para proteger datos sensibles. Las organizaciones pueden usar funciones integradas y personalizadas. Estas funciones ayudan a crear copias seguras y ocultas de sus datos. Esto es útil para pruebas y propósitos de desarrollo.
Recuerda, la protección de datos es un proceso continuo. Revisa y actualiza regularmente tus estrategias de enmascaramiento para adelantarte a las amenazas y requisitos normativos en evolución.
Para aquellos que buscan una protección más avanzada y en tiempo real, soluciones como DataSunrise ofrecen capacidades de enmascaramiento de datos. DataSunrise proporciona herramientas fáciles de usar y de vanguardia para la seguridad de bases de datos, incluyendo características de auditoría y descubrimiento de datos. Para conocer más sobre cómo DataSunrise puede mejorar tu estrategia de protección de datos, visita nuestro sitio web para una demostración en línea.
Siguiente
