
¿Qué es el Enmascaramiento de Datos?
¿Qué es el Enmascaramiento de Datos?
Para comprender el enmascaramiento de datos, es importante considerarlo dentro del panorama más amplio del aumento de las brechas de datos y las normativas de privacidad cada vez más estrictas. Las organizaciones hoy en día deben proteger la información sensible mientras la mantienen usable para funciones empresariales esenciales. Según investigaciones recientes de Gartner, el enmascaramiento de datos se ha convertido en un elemento fundamental de las tecnologías modernas que mejoran la privacidad, especialmente en entornos donde los datos se comparten entre equipos internos, socios externos y plataformas en la nube.
El enmascaramiento de datos reemplaza los valores reales con versiones realistas pero fabricadas. Esto asegura que la información sensible permanezca protegida contra exposiciones no autorizadas, mientras permite un uso seguro de los datos para desarrollo, pruebas, análisis y colaboración con terceros.
Para cumplir con las crecientes demandas de privacidad y cumplir con marcos como GDPR, HIPAA y PCI DSS, las organizaciones requieren soluciones escalables y gobernadas por políticas para el enmascaramiento. DataSunrise ofrece tanto enmascaramiento estático como dinámico, impulsado por reglas inteligentes que se ajustan automáticamente según los roles de usuario, el contexto y los permisos de acceso.
Cuando se implementa eficazmente, el enmascaramiento de datos transforma la forma en que se gestiona la información sensible—apoyando la colaboración segura, reduciendo amenazas internas y asegurando el cumplimiento en ecosistemas de datos distribuidos y complejos.
Por qué el Enmascaramiento de Datos es Importante en las Estrategias Modernas de Seguridad
La protección moderna de datos va mucho más allá de los enfoques tradicionales de encriptación. El enmascaramiento de datos desempeña un papel crucial en la aplicación del principio de mínimos privilegios, garantizando que la información sensible permanezca protegida incluso cuando la accedan usuarios autorizados que no necesitan visibilidad completa de los datos.
Ya sea bajo GDPR en Europa, HIPAA en atención médica, o PCI DSS en servicios financieros, las organizaciones deben demostrar medidas proactivas de protección de datos. Con políticas de enmascaramiento integrales, los equipos pueden procesar, analizar y probar con conjuntos de datos realistas sin exponer los valores sensibles originales a personal no autorizado.
Sin enmascaramiento, incluso usuarios internos bienintencionados pueden obtener visibilidad de datos confidenciales que no necesitan—lo que incrementa el riesgo de filtración, uso indebido o incumplimiento normativo. Al introducir el enmascaramiento en los flujos cotidianos, las organizaciones reducen dramáticamente la exposición a lo largo de las cadenas de desarrollo, herramientas analíticas e interacciones con proveedores, sin comprometer la productividad o la fidelidad de los datos.
| Regulación | Cláusula | Requisito de Enmascaramiento |
|---|---|---|
| GDPR | Art. 32 | Seudonimización de datos personales |
| PCI DSS 4.0 | 3.4 | Hacer ilegible el PAN (tokenizar, enmascarar) |
| HIPAA | §164.514(b) | Desidentificar 18 identificadores PHI |
| DORA | Art. 9 | Proteger conjuntos de datos usados en pruebas de resiliencia |
El enmascaramiento dinámico permite acceso seguro a sistemas de producción en vivo, mientras que el enmascaramiento estático crea conjuntos de datos saneados perfectos para ambientes de capacitación, colaboración con proveedores o pruebas de aseguramiento de calidad. DataSunrise agiliza ambas metodologías mediante interfaces intuitivas de configuración y soporte robusto para esquemas complejos de base de datos y despliegues híbridos en la nube.
Enmascaramiento de Datos — Resumen, Pasos y Verificaciones Rápidas
Resumen
- Propósito: limitar la exposición de valores sensibles mientras se preserva la utilidad del conjunto de datos.
- Modos: dinámico (al ejecutar consulta), estático (copias saneadas), en sitio (conjuntos no productivos).
- Alineación: cumpliendo seudonimización GDPR, desidentificación HIPAA, enmascaramiento PCI DSS.
Pasos de Implementación
- Descubrir y clasificar campos (PII/PHI/PCI) en diversas fuentes.
- Definir roles y niveles de visibilidad requeridos.
- Seleccionar modo según caso de uso (dinámico para producción; estático para dev/prueba/proveedor).
- Elegir algoritmos (redacción, sustitución, FPE, tokenización) según tipo de columna.
- Configurar reglas a nivel esquema/tabla/columna; preservar integridad referencial.
- Validar en entorno staging; confirmar comportamiento de aplicaciones y precisión analítica.
- Monitorear rendimiento y ajustar alcance para controlar latencia.
- Documentar políticas; programar revisiones periódicas conforme evolucionen los esquemas.
Selección de Algoritmo
| Tipo de Datos | Enfoque Recomendado | Notas |
|---|---|---|
| PAN / datos de tarjeta | Enmascarar BIN + últimos 4 / tokenización | Alineación con Requisito PCI DSS 3.4 |
| Emails / nombres de usuario | Sustitución que preserva formato | Mantener forma dominio/usuario para UX |
| PII en texto libre | Sustitución con diccionario/regex | Escanear logs, comentarios, blobs JSON |
| Fechas / montos | Inyección de ruido / agrupamiento | Preservar orden/estadísticas |
| IPs / ubicaciones | Generalización / aleatorización | Mantener región si es necesario |
Verificaciones Rápidas
- ¿Las columnas enmascaradas siguen siendo válidas para la lógica de la aplicación e informes?
- ¿Las transformaciones son irreversibles para usuarios sin privilegios?
- ¿Se preserva la integridad referencial entre tablas relacionadas?
- ¿La latencia añadida está dentro de los SLOs objetivo bajo carga máxima?
Casos de Uso Comunes para el Enmascaramiento de Datos
Las organizaciones implementan el enmascaramiento de datos en diversos escenarios para mantener la seguridad mientras habilitan operaciones de negocio:
- Colaboración con proveedores: Compartir conjuntos de datos con socios externos protegiendo la confidencialidad de clientes e información competitiva. El enmascaramiento asegura que proveedores, contratistas y prestadores de servicios externos puedan realizar sus tareas efectivamente sin acceder a datos sensibles crudos, reduciendo el riesgo de brechas en entornos externos menos controlados.
- Prevención de errores: Protección contra exposiciones accidentales derivadas de errores operativos, administrativos o configuraciones incorrectas del sistema. El enmascaramiento funciona como una capa adicional de seguridad, asegurando que incluso si datos privilegiados son exportados, registrados o accedidos erróneamente, los campos sensibles permanezcan ilegibles y se minimice el impacto del error humano.
- Desarrollo y pruebas: Proveer conjuntos realistas para pruebas de aplicaciones, entrenamiento de modelos de machine learning y optimización de rendimiento sin riesgos de privacidad. El enmascaramiento permite a los equipos trabajar con datos estructuralmente precisos y similares a producción, apoyando la depuración, pruebas de carga, entrenamiento de modelos y validaciones de integración sin usar identidades reales ni campos regulados.
- Análisis y reportes: Permitir que científicos de datos y analistas trabajen con datos parecidos a producción manteniendo el cumplimiento normativo. Los conjuntos enmascarados preservan propiedades estadísticas críticas y relaciones, facilitando insights de alta calidad, dashboards y pronósticos sin exponer PII ni violar estándares como GDPR, HIPAA o PCI DSS.
Ejemplos de Datos Enmascarados
Las estrategias de enmascaramiento varían significativamente según requisitos de clasificación, niveles de permisos de usuario y políticas específicas de cumplimiento. Algunos sistemas requieren una redacción completa, mientras otros permiten sustituciones que preservan el formato manteniendo la utilidad. DataSunrise admite ambos enfoques en bases de datos estructuradas y repositorios de datos no estructurados.
-- Antes del enmascaramiento: 4024-0071-8423-6700 -- Después del enmascaramiento: XXXX-XXXX-XXXX-6700
| Método de Enmascaramiento | Datos Originales | Datos Enmascarados |
|---|---|---|
| Enmascaramiento de tarjeta de crédito | 4111 1111 1111 1111 | 4111 **** **** 1111 |
| Enmascaramiento de email | [email protected] | j***e@e*****e.com |
| Enmascaramiento de URL | https://www.example.com/user/profile | https://www.******.com/****/****** |
| Enmascaramiento de número telefónico | +1 (555) 123-4567 | +1 (***) ***-4567 |
| Aleatorización de dirección IP | 192.168.1.1 | 203.45.169.78 |
| Aleatorización de fecha preservando año | 2023-05-15 | 2023-11-28 |
| Enmascaramiento con función personalizada | Secret123! | S****t1**! |
| Sustitución basada en diccionario | John Smith, Software Engineer, New York | Ahmet Yılmaz, Data Analyst, Chicago |
Pasos para la Implementación del Enmascaramiento de Datos
La implementación exitosa del enmascaramiento de datos requiere una planificación y ejecución sistemática a lo largo de varias fases:
- Descubrimiento y clasificación de datos: Localiza campos sensibles en toda tu infraestructura utilizando herramientas de descubrimiento automatizado que identifican PII, datos financieros e información regulada en bases de datos y aplicaciones.
- Mapeo de políticas y definición de roles: Establece políticas de enmascaramiento integrales basadas en roles de usuario, clasificaciones de sensibilidad de datos y requisitos regulatorios específicos de tu industria y ubicación geográfica.
- Configuración de reglas y pruebas: Define reglas granulares de enmascaramiento a nivel de esquema, tabla, columna o tipo de dato, asegurando que los datos enmascarados mantengan integridad referencial y consistencia lógica de negocio.
- Validación y despliegue: Prueba a fondo la funcionalidad de enmascaramiento en entornos de staging antes de su despliegue en producción, validando que las aplicaciones continúen funcionando correctamente con conjuntos de datos enmascarados.
- Monitoreo y mantenimiento: Establece monitoreo continuo para asegurar que las políticas de enmascaramiento sigan siendo efectivas conforme evolucionan las estructuras de datos y se introducen nuevos tipos de datos sensibles.
Tipos de Enmascaramiento de Datos
| Algoritmo | ¿Preserva Formato? | Riesgo de Re-ID | Ideal para |
|---|---|---|---|
| Redacción | No | El más bajo | Logs, capturas de pantalla |
| Tokenización | Sí | Muy bajo* | Tokens de pago |
| Aleatorización | Opcional | Bajo | Conjuntos PII |
| Encriptación que preserva formato (FPE) | Sí | Muy bajo | Aplicaciones legadas |
*Asumiendo controles de detokenización basados en bóveda.
Enmascaramiento Dinámico
El enmascaramiento dinámico aplica ofuscación de datos durante la ejecución de consultas sin alterar permanentemente los datos origen. Este enfoque provee controles de acceso en tiempo real ideales para sistemas productivos multiusuario donde la visibilidad debe variar dinámicamente según roles de usuario y contexto de acceso.
CREATE VIEW masked_customers AS
SELECT
id,
name,
CASE
WHEN current_user = 'admin_user' THEN credit_card
ELSE regexp_replace(credit_card, '^\d{4}-\d{4}-\d{4}-(\d{4})$', 'XXXX-XXXX-XXXX-\1')
END AS credit_card
FROM customers;
Enmascaramiento Estático
El enmascaramiento estático crea copias permanentemente saneadas de bases de datos de producción, permitiendo el compartimiento seguro y distribución sin preocupaciones continuas de privacidad. Estos conjuntos pueden exportarse, compartirse con socios externos o usarse en proyectos analíticos a largo plazo sin violar normativas de privacidad. Este enfoque es especialmente valioso para el cumplimiento de ISO 27001 y preparación de auditorías regulatorias.
Enmascaramiento In-Situ
El enmascaramiento in-situ transforma los datos directamente dentro de bases no productivas existentes, particularmente durante ciclos de pruebas pre-lanzamiento o preparación de entornos sandbox. Este enfoque elimina la necesidad de infraestructuras de almacenamiento duplicadas mientras asegura que los equipos de desarrollo trabajen con conjuntos realistas pero protegidos.
Requisitos Esenciales para el Enmascaramiento
Las implementaciones efectivas de enmascaramiento deben cumplir varios requisitos críticos para mantener tanto seguridad como utilidad operacional:
- Preservación realista de datos: Los datos enmascarados deben lucir y comportarse como reales para asegurar integración fluida con sistemas existentes. Los valores sustituidos deberían mantener la misma estructura, formato y distribución estadística que los originales — por ejemplo, números de tarjeta enmascarados deberían pasar validaciones de checksum y fechas enmascaradas deberían permanecer dentro de rangos lógicos. Este realismo permite que aplicaciones, análisis y entornos de prueba operen normalmente sin riesgo de exponer información sensible.
- Transformación irreversible: El proceso debe estar diseñado para que recuperar los datos originales sea matemáticamente imposible. Fuertes algoritmos de aleatorización y criptografía previenen cualquier posibilidad de ingeniería inversa o re-identificación basada en patrones. Esta transformación irreversible es fundamental para cumplir regulaciones como GDPR y HIPAA, que exigen que los datos anonimizados no puedan vincularse a individuos.
- Comportamiento consistente: Para mantener la integridad, la lógica de enmascaramiento debe producir resultados enmascarados idénticos para la misma entrada a través de todos los sistemas y periodos. Por ejemplo, un ID de cliente o número de empleado que aparezca en varias tablas debe enmascararse igual en todos lados para preservar precisión relacional. Esta consistencia soporta pruebas, reportes y auditorías confiables sin comprometer la seguridad.
- Optimización de rendimiento: El enmascaramiento efectivo debe balancear seguridad y eficiencia. El proceso debe introducir mínima sobrecarga y evitar ralentizar sistemas productivos o consultas analíticas. Algoritmos optimizados y técnicas de procesamiento paralelo permiten proteger grandes conjuntos de datos rápidamente — asegurando fuertes controles de seguridad sin afectar rendimiento operativo o experiencia de usuario.
El Enmascaramiento de Datos en Marcos de Cumplimiento
Los reguladores clasifican el enmascaramiento de datos como seudonimización, desidentificación o minimización de datos. A continuación se muestra cómo los principales marcos describen sus requisitos y cómo el enmascaramiento los aborda:
| Marco | Requisito | Alineación con Enmascaramiento |
|---|---|---|
| GDPR | Art. 32 — seudonimizar o anonimizar datos personales | El enmascaramiento dinámico evita la exposición de PII cruda a usuarios sin privilegios. |
| HIPAA | §164.514 — desidentificar 18 identificadores PHI | El enmascaramiento estático genera conjuntos sin PHI para pruebas, capacitación e investigación. |
| PCI DSS | Req. 3.4 — hacer ilegible el PAN excepto BIN + últimos 4 dígitos | El enmascaramiento que preserva formato asegura cumplimiento para datos de tarjeta de pago. |
| SOX | Mantener integridad de datos financieros para reportes | Las copias de prueba enmascaradas previenen fugas de registros financieros sensibles. |
Alineando políticas de enmascaramiento con requisitos regulatorios, DataSunrise permite a las empresas proteger información sensible mientras generan evidencia lista para auditorías en bases de datos, nubes y ambientes híbridos.
Resultados Empresariales del Enmascaramiento de Datos
- Reducción de exposición a brechas: Hasta 60% menos campos sensibles visibles para usuarios no autorizados
- Eficiencia en cumplimiento: Evidencia para auditorías generada en horas, no semanas
- Velocidad operativa: Ciclos de QA y pruebas acelerados ~30% con conjuntos seguros y similares a producción
- Menor riesgo legal: Alineación directa con cláusulas de GDPR, HIPAA, PCI DSS
Aplicaciones en Industrias
- Finanzas: Enmascaramiento de PAN y PII para PCI DSS y reportes SOX
- Salud: Desidentificación de PHI para cumplir reglas de privacidad HIPAA
- SaaS y Nube: Enmascaramiento multitenant para garantizar separación conforme a GDPR
- Retail: Protección de datos clientes en pipelines analíticos sin perder insights
Fragmentos Nativos de Enmascaramiento de Datos en Plataformas
La mayoría de bases de datos ofrecen soporte nativo limitado de enmascaramiento, que a menudo requiere código personalizado o extensiones. A continuación ejemplos en SQL Server y Oracle:
SQL Server: Enmascaramiento Dinámico Incorporado
-- Enmascarar columna de tarjeta de crédito con exposición parcial
CREATE TABLE Customers (
Id INT IDENTITY PRIMARY KEY,
FullName NVARCHAR(100),
CreditCard VARCHAR(19) MASKED WITH (FUNCTION = 'partial(0,"XXXX-XXXX-XXXX-",4)')
);
-- Resultado: 4111-2222-3333-4444 → XXXX-XXXX-XXXX-4444
Oracle: Política de Base de Datos Privada Virtual (VPD)
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'HR',
object_name => 'EMPLOYEES',
policy_name => 'mask_ssn_policy',
function_schema => 'SEC_ADMIN',
policy_function => 'mask_ssn_fn',
statement_types => 'SELECT'
);
END;
/
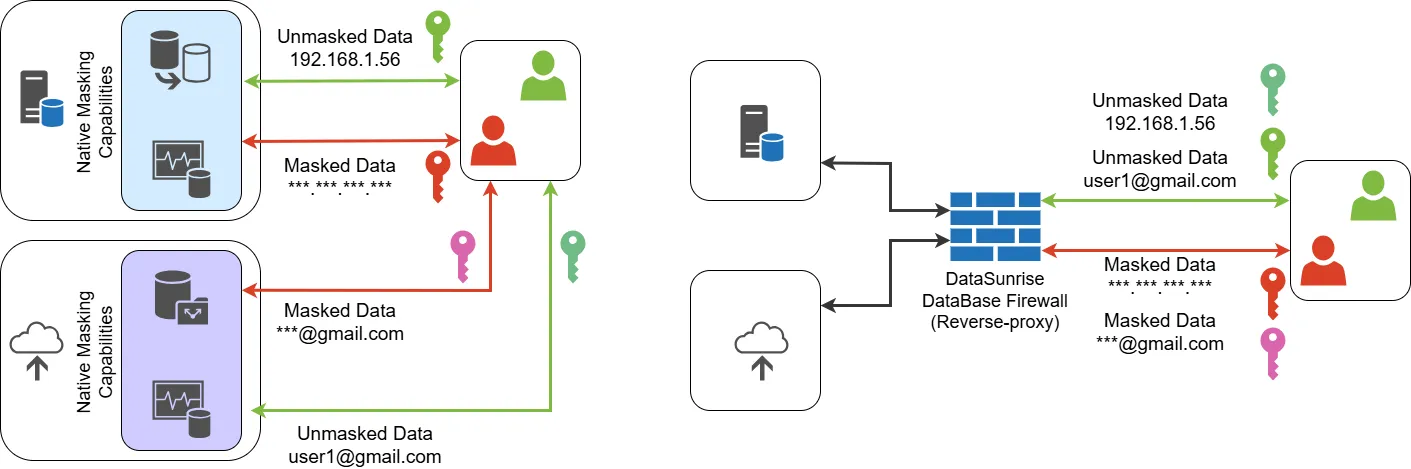
Ambos ejemplos demuestran enmascaramiento nativo de plataforma, pero carecen de la flexibilidad para aplicar reglas conscientes del rol a través de múltiples bases simultáneamente.
Enmascaramiento en Contexto de Cumplimiento
Diferentes regulaciones consideran el enmascaramiento como seudonimización, desidentificación o minimización. Un requisito típico es garantizar transformación irreversible mientras se mantiene la usabilidad. A continuación un mapa rápido de cumplimiento:
| Marco | Objetivo del Enmascaramiento | Limitación Nativa |
|---|---|---|
| GDPR | Seudonimizar datos personales | Falta enmascaramiento consistente basado en roles |
| HIPAA | Desidentificar identificadores PHI | Sin aplicación de política a nivel de campo |
| PCI DSS | Enmascarar PAN excepto BIN y últimos 4 dígitos | Específico de plataforma, no unificado |
El enmascaramiento nativo satisface cláusulas básicas, pero plataformas unificadas como DataSunrise proveen cobertura cruzada regulatoria desde el primer momento.
Enmascaramiento de Datos con DataSunrise
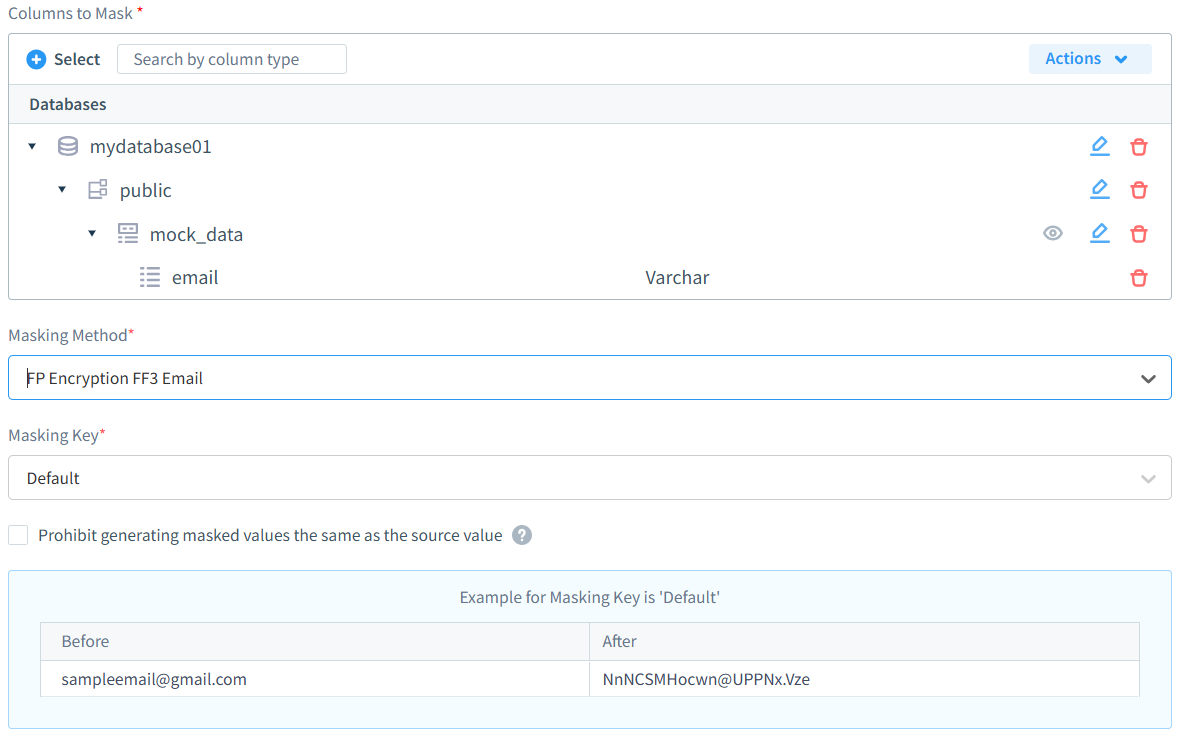
DataSunrise proporciona capacidades de enmascaramiento a nivel empresarial diseñadas para los requisitos modernos de protección de datos:
- Modos de enmascaramiento flexibles: Soporte completo para enmascaramiento dinámico en tiempo real y técnicas estáticas offline, permitiendo que las organizaciones elijan enfoques óptimos según casos de uso.
- Controles de acceso inteligentes: Políticas de enmascaramiento conscientes de roles y algoritmos que preservan el formato manteniendo la utilidad de datos mientras aplican estrictas protecciones de privacidad.
- Integraciones empresariales: Integración fluida con sistemas IAM existentes, plataformas SIEM y motores de aplicación de políticas para agilizar operaciones de seguridad y reportes de cumplimiento.
- Automatización de cumplimiento: Capacidades integradas de registro y reporte para auditorías, específicamente diseñadas para GDPR, PCI DSS, HIPAA y SOX.
- Arquitectura escalable: Soporte para entornos en la nube nativa, híbridos y legados con impacto mínimo en rendimiento y alta disponibilidad.
Escalando el Enmascaramiento de Datos en Entornos Complejos
A medida que las arquitecturas evolucionan, el enmascaramiento debe escalar a través de nubes híbridas, microservicios distribuidos y cargas de trabajo mixtas. Las organizaciones frecuentemente enfrentan dificultades para mantener lógica de enmascaramiento consistente a través de bases relacionales, almacenes NoSQL e incluso repositorios no estructurados como almacenamiento de objetos o logs.
- Aplicación de políticas multiplataforma: Aplicar reglas de enmascaramiento uniformemente en PostgreSQL, Oracle, SQL Server, MongoDB y Amazon S3 — asegurando comportamiento y cumplimiento coherentes sin importar la tecnología backend.
- Soporte para datos no estructurados y semiestructurados: Enmascarar valores sensibles incrustados en JSON, XML, archivos de logs y contenido generado por usuarios usando reglas basadas en expresiones regulares o diccionarios.
- Automatización en CI/CD para enmascaramiento: Incrustar validación de enmascaramiento en pipelines DevOps integrando las reglas de DataSunrise en flujos previos al despliegue. Prevenir que campos sensibles sin enmascarar se filtren a entornos de staging o pruebas.
- Validación y marcos de QA: Ejecutar comprobaciones automatizadas para asegurar que las reglas de enmascaramiento no rompan análisis posteriores, dashboards o lógica de aplicaciones.
- Versionado y reversión de políticas: Mantener políticas de enmascaramiento versionadas que puedan revertirse o actualizarse sin interrupciones — crítico para entornos ágiles y adaptaciones a cambios regulatorios.
Con estas capacidades, el enmascaramiento de datos evoluciona de ser un control aislado a una capa dinámica y centralizada de protección. En lugar de depender de scripts ad hoc o parches de seguridad aislados, los equipos cuentan con un motor de aplicación unificado capaz de adaptarse a cualquier entorno — ya sea nube nativa, legado o híbrido.
Preguntas Frecuentes sobre Enmascaramiento de Datos
¿Cuál es el propósito del enmascaramiento de datos?
El enmascaramiento sustituye valores sensibles con equivalentes realistas para prevenir accesos no autorizados. Permite el uso seguro de conjuntos de datos en pruebas, análisis y compartición con proveedores sin exponer la información original.
¿En qué se diferencia el enmascaramiento de la tokenización?
El enmascaramiento crea sustitutos no reversibles para privacidad y cumplimiento, mientras la tokenización reemplaza valores con tokens almacenados en una bóveda. La tokenización soporta recuperación reversible, haciéndola ideal para procesamiento de pagos bajo PCI DSS.
¿Qué marcos de cumplimiento requieren enmascaramiento de datos?
Marcos como GDPR (seudonimización), HIPAA (desidentificación) y PCI DSS (enmascaramiento de datos de titulares de tarjeta) establecen explícitamente controles de enmascaramiento o equivalentes para proteger campos sensibles.
¿Cuándo se debe usar enmascaramiento dinámico vs estático?
- Enmascaramiento dinámico: Ofuscación en tiempo real durante la ejecución de consultas; ideal para bases productivas con acceso basado en roles.
- Enmascaramiento estático: Crea copias saneadas de bases de datos; mejor para desarrollo, pruebas y colaboración con proveedores.
¿Cuáles son los requisitos esenciales para un enmascaramiento efectivo?
- Preservar formatos realistas y lógica de negocio.
- Asegurar transformaciones irreversibles.
- Aplicar reglas consistentes y repetibles en todos los entornos.
- Mantener baja latencia en sistemas productivos.
¿Qué herramientas simplifican el enmascaramiento a nivel empresarial?
DataSunrise ofrece enmascaramiento estático y dinámico centralizado con políticas conscientes de roles, generación de reportes regulatorios e integración en pipelines DevOps, eliminando scripts aislados y soluciones fragmentadas.
El Futuro del Enmascaramiento de Datos
El enmascaramiento de datos ha evolucionado mucho más allá de su propósito original de ocultar números de tarjeta de crédito o identificadores de clientes en entornos de prueba. Hoy representa una capa dinámica e inteligente de seguridad empresarial. Las innovaciones emergentes están transformando cómo se descubre, despliega y mantiene el enmascaramiento a escala. El descubrimiento asistido por IA ahora permite que los sistemas detecten y clasifiquen automáticamente información sensible en fuentes estructuradas y no estructuradas, mientras que los enfoques de políticas como código permiten a las organizaciones versionar, auditar y aplicar reglas de enmascaramiento de manera consistente a través de pipelines CI/CD y flujos DevOps.
Los principales proveedores de nube y analítica también están integrando capacidades nativas de enmascaramiento directamente en sus ecosistemas, asegurando que los datos sensibles permanezcan protegidos durante la ingestión, transformación y consultas analíticas. Esto incluye la aplicación automática del enmascaramiento durante la transferencia de datos entre entornos—como entre producción, pruebas y pipelines de entrenamiento de IA—reduciendo la probabilidad de exposición durante procesos a gran escala.
Como parte de una estrategia unificada de protección de datos, las tecnologías avanzadas de enmascaramiento ahora se integran sin problemas con monitoreo de actividad de bases de datos, automatización de cumplimiento y descubrimiento de datos sensibles. En conjunto, forman un tejido de seguridad adaptable capaz de responder a amenazas, requisitos regulatorios y demandas comerciales en evolución. En los próximos años, el enmascaramiento dejará de ser visto solo como un control de privacidad, para convertirse en una salvaguardia proactiva, impulsada por IA y central para la gobernanza moderna de datos y la transformación digital segura.
Enmascaramiento Nativo vs DataSunrise
| Capacidad | Enmascaramiento Nativo en BD | DataSunrise |
|---|---|---|
| Cobertura Multibase | Limitada (solo SQL Server, Oracle) | Sí — Oracle, PostgreSQL, MySQL, MongoDB, SQL Server, bases en nube |
| Opciones Dinámico vs Estático | Uno u otro, según motor | Ambos, configurados centralmente |
| Aplicación de Políticas | Manual, específico de BD | Consciente de roles, pol. como código, versionado |
| Reporte de Cumplimiento | No incorporado | Reportes pre-construidos GDPR, HIPAA, PCI DSS, SOX |
| Integración | Mínima | IAM, SIEM, CI/CD, pipelines nube nativa |
El enmascaramiento nativo ofrece un punto de partida, pero DataSunrise provee controles empresariales, multiplataforma y escalables.
Conclusión
Mientras las organizaciones continúan manejando volúmenes de datos en rápida expansión a través de sistemas y arquitecturas diversas, proteger la información sensible se ha convertido en una prioridad estratégica y mandato regulatorio. El enmascaramiento de datos ha surgido como uno de los métodos más confiables para prevenir accesos no autorizados a campos sensibles, asegurando que la información personal y confidencial permanezca oculta mientras los conjuntos de datos conservan plena funcionalidad para usos legítimos. Esto permite a los equipos realizar análisis, colaborar con proveedores externos y llevar a cabo actividades de desarrollo o pruebas sin exponer datos reales—preservando la privacidad, apoyando el cumplimiento y manteniendo la eficiencia operativa.
DataSunrise simplifica y automatiza el enmascaramiento a nivel empresarial a través de infraestructuras on-premises, híbridas y multinube. Su plataforma unificada soporta el ciclo completo de protección de datos—incluyendo descubrimiento de datos sensibles, clasificación automática, enmascaramiento dinámico y estático, gestión granular de políticas y reportes listos para auditoría. Capacidades como Enmascaramiento Estático de Datos proveen un método seguro y consistente para preparar conjuntos de datos protegidos para desarrollo, análisis y colaboración externa. Con automatización inteligente, bajo impacto en rendimiento y amplia compatibilidad con tecnologías líderes en bases de datos, DataSunrise permite a las organizaciones aplicar controles de privacidad robustos, cumplir con normativas globales y potenciar la innovación impulsada por datos de forma segura. En un mundo donde los riesgos de exposición de datos continúan creciendo, una estrategia moderna y automatizada de enmascaramiento es esencial para la seguridad y resiliencia a largo plazo.
Siguiente
