Apprentissage Automatique Antagoniste
À mesure que l’intelligence artificielle s’intègre dans les flux de travail essentiels aux entreprises, environ 91 % des banques américaines utilisent désormais l’IA pour la détection des fraudes, selon Elastic Insights (2025).
Alors que la plupart des organisations investissent massivement dans la sécurité des bases de données et les contrôles d’infrastructure, l’apprentissage automatique antagoniste (AML) expose une menace nouvelle et plus subtile — une menace qui cible les algorithmes eux-mêmes plutôt que les systèmes environnants.
Cet article explore le fonctionnement des attaques antagonistes, leurs dangers pour les pipelines d’IA, et comment des technologies telles que l’approche de sécurité inspirée des données de DataSunrise peuvent renforcer l’intégrité des modèles depuis l’entraînement jusqu’au déploiement.
Comprendre l’Apprentissage Automatique Antagoniste
L’apprentissage automatique antagoniste consiste à créer intentionnellement des entrées qui poussent les modèles d’IA à faire des erreurs — depuis la mauvaise classification d’images jusqu’à la génération de prédictions fausses. En essence, c’est la science qui transforme l’intelligence d’un modèle en une faiblesse.
Contrairement aux menaces classiques de cybersécurité qui exploitent des failles logicielles, les attaques antagonistes ciblent le cœur statistique même de l’apprentissage automatique. Quelques octets d’entrées perturbées peuvent manipuler la sortie du modèle sans changement visible pour les humains. C’est pourquoi défendre les systèmes d’IA nécessite une fusion de surveillance en temps réel, de détection d’anomalies et de suivi de provenance des données à toutes les étapes de l’apprentissage.
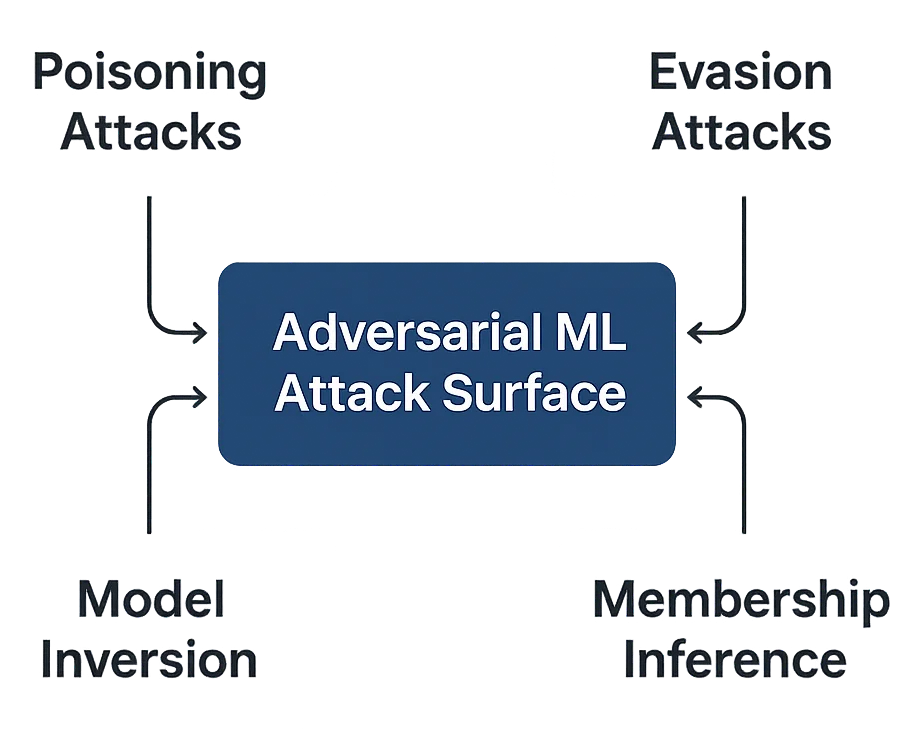
Les Menaces Clés de l’Apprentissage Antagoniste
L’AML peut se présenter sous plusieurs formes selon le moment et la manière dont les attaquants interviennent :
- Attaques par Empoisonnement – Corrompre les jeux de données d’entraînement avec des exemples malveillants. Même une pollution mineure des données peut biaiser les modèles et saboter des prédictions critiques pour la conformité.
- Attaques d’Évasion – Créer des entrées qui contournent la détection par le modèle. Courantes dans la reconnaissance faciale, les filtres anti-spam et la détection de fraude.
- Inversion de Modèle – Reconstituer des données d’entraînement sensibles à partir des sorties du modèle, menaçant l’exposition des informations personnelles identifiables (PII).
- Inférence d’Appartenance – Deviner si un enregistrement particulier faisait partie du jeu de données d’entraînement, compromettant les garanties de confidentialité des données.
Détecter les Comportements Antagonistes en Temps Réel
Les outils de surveillance traditionnels ne reconnaissent pas facilement une entrée antagoniste. Un léger changement dans un tableau de pixels ou un encodage textuel peut sembler normal mais dérégler complètement le comportement du modèle. Pour répondre à cela, les équipes de sécurité s’appuient sur des détecteurs basés sur ML qui signalent les anomalies dans le comportement des gradients, la variance des caractéristiques ou l’entropie des sorties.
Voici un exemple simplifié d’un tel détecteur :
import numpy as np
class AdversarialDetector:
"""Détecte les perturbations antagonistes basées sur l’analyse de la déviation des caractéristiques."""
def __init__(self, baseline_vector: np.ndarray, threshold: float = 0.15):
self.baseline = baseline_vector
self.threshold = threshold
def detect(self, input_vector: np.ndarray) -> dict:
delta = np.linalg.norm(input_vector - self.baseline) / len(input_vector)
is_adversarial = delta > self.threshold
return {
"threat_detected": is_adversarial,
"risk_score": float(delta * 100),
"severity": "ÉLEVÉ" if is_adversarial else "FAIBLE",
"recommendations": ["Re-former avec des données vérifiées"] if is_adversarial else []
}
Cette routine compare les nouvelles entrées à une référence de distributions de données fiables, fournissant à la fois des indicateurs quantitatifs et qualitatifs pour l’analyse comportementale en aval.
Renforcer les Modèles par un Entraînement Défensif
Au-delà de la détection, les organisations doivent renforcer leurs modèles contre les manipulations futures. Une technique efficace est l’entraînement antagoniste — exposer délibérément le modèle à des échantillons modifiés durant l’apprentissage pour qu’il apprenne à y résister.
class RobustTrainer:
"""Réalise un entraînement antagoniste pour améliorer la résilience du modèle."""
def __init__(self, model, epsilon: float = 0.1):
self.model = model
self.epsilon = epsilon
def perturb(self, x):
noise = np.random.uniform(-self.epsilon, self.epsilon, x.shape)
return np.clip(x + noise, 0, 1)
def train(self, data, labels):
adv_data = self.perturb(data)
combined = np.vstack((data, adv_data))
combined_labels = np.concatenate((labels, labels))
self.model.fit(combined, combined_labels)
return {"status": "Modèle entraîné avec robustesse antagoniste"}
Meilleures Pratiques pour la Sécurité de l’Apprentissage Antagoniste
Pour les Organisations
- Sécuriser le Cycle de Vie des Données – Mettre en place un suivi continu de l’historique des activités pour repérer tôt les anomalies.
- Établir une Gouvernance des Modèles – Définir la propriété et les politiques qui respectent les cadres réglementaires tels que le RGPD et HIPAA.
- Auditer Tout – Activer des traces d’audit unifiées pour vérifier la lignée des modèles et l’intégrité de l’entraînement.
- Former les Parties Prenantes – S’assurer que les data scientists comprennent les implications de sécurité du bruit antagoniste.
Pour les Équipes Techniques
- Utiliser des Outils d’IA Explicable – Interpréter les sorties des modèles et tracer les anomalies via des tableaux de bord de sécurité.
- Intégrer une Validation Continue – Automatiser les contrôles dans les pipelines via des contrôles de proxy inverse pour filtrer les requêtes.
- Appliquer un Accès Basé sur les Rôles – Restreindre l’accès à l’entraînement et à l’inférence des modèles avec RBAC.
- Chiffrer les Jeux de Données – Utiliser le chiffrement au niveau des champs pour empêcher la récupération non autorisée des données.
DataSunrise : Protection Complète Contre l’Apprentissage Antagoniste
DataSunrise étend la protection au-delà de l’infrastructure — intégrant la résilience directement dans le flux de travail de l’IA. Sa plateforme offre une Orchestration de Sécurité Zero-Touch avec une Protection Contextuelle et une Détection Autonome des Menaces sur plus de 50 plateformes supportées.
Capacités clés
- Détection d’Anomalies alimentée par ML – Corrèle les comportements anormaux de gradients et de caractéristiques.
- Suivi de la Provenance des Données – Assure que chaque enregistrement utilisé dans l’entraînement est vérifiable.
- Autopilote de Conformité – Cartographie les opérations des modèles et des données aux contrôles réglementaires.
- Cadre d’Audit Unifié – Relie les journaux, événements et activités utilisateur dans un unique tableau de bord.
- Moteur de Masquage Adaptatif – Cache dynamiquement les caractéristiques à haut risque durant l’évaluation des modèles.
Ensemble, ces modules garantissent la conformité par défaut de l’IA — prévenant les manipulations antagonistes intentionnelles ou accidentelles au sein des environnements d’entreprise.
Conclusion : Construire des Modèles d’IA Fiables
L’apprentissage automatique antagoniste nous rappelle que les systèmes intelligents peuvent être trompés aussi facilement que les humains — et que leur protection nécessite une intelligence défensive égale.
En combinant des contrôles forts sur les données, des modèles explicables, et une application continue des pare-feu pour bases de données, les organisations peuvent transformer la vulnérabilité en vigilance.
