
Qu’est-ce que le masquage des données ?
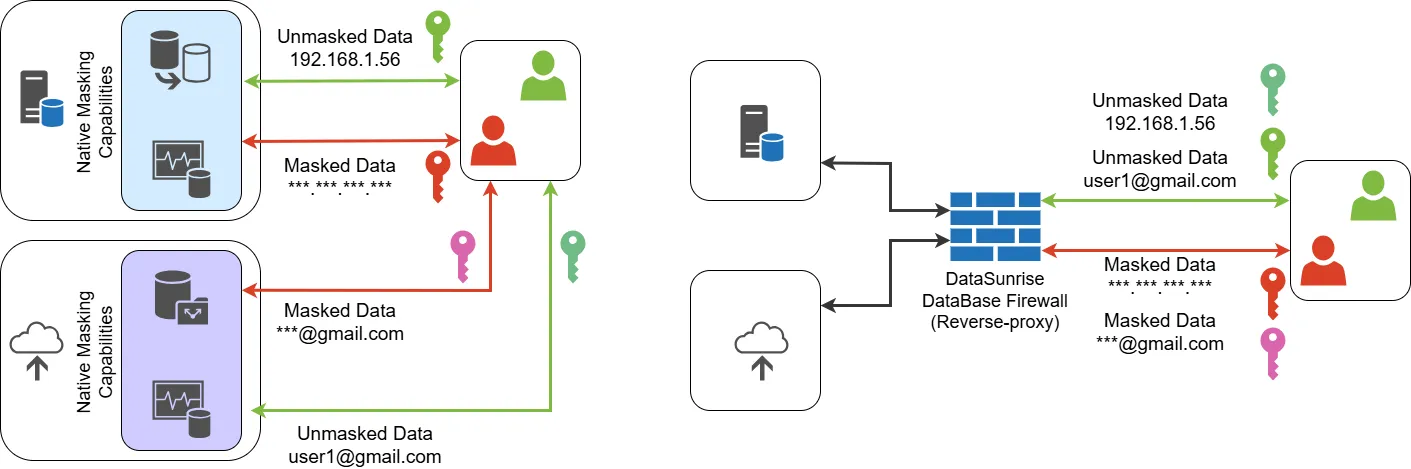
Qu’est-ce que le masquage des données ?
Pour comprendre le masquage des données, il est important de le considérer dans le contexte plus large de l’augmentation des violations de données et des réglementations sur la confidentialité de plus en plus strictes. Les organisations doivent aujourd’hui protéger les informations sensibles tout en les gardant utilisables pour des fonctions commerciales essentielles. Selon les récentes recherches de Gartner, le masquage des données est devenu un élément fondamental des technologies modernes d’amélioration de la confidentialité, en particulier dans les environnements où les données sont partagées entre équipes internes, partenaires externes et plateformes cloud.
Le masquage des données remplace les valeurs réelles par des versions réalistes mais fabriquées. Cela garantit que les informations sensibles restent protégées contre toute exposition non autorisée tout en permettant une utilisation sécurisée des données pour le développement, les tests, l’analytique et la collaboration avec des tiers.
Pour répondre aux demandes croissantes en matière de confidentialité et se conformer à des cadres tels que le RGPD, HIPAA et le PCI DSS, les organisations ont besoin de solutions de masquage évolutives et pilotées par des politiques. DataSunrise propose à la fois un masquage statique et dynamique, alimenté par des règles intelligentes qui s’ajustent automatiquement en fonction des rôles utilisateurs, du contexte et des permissions d’accès.
Lorsqu’il est mis en œuvre efficacement, le masquage des données transforme la gouvernance des informations sensibles — favorisant une collaboration sécurisée, réduisant les menaces internes et assurant la conformité dans des écosystèmes de données complexes et distribués.
Pourquoi le masquage des données est important dans les stratégies de sécurité modernes
La protection moderne des données va bien au-delà des approches traditionnelles de chiffrement. Le masquage des données joue un rôle crucial dans l’application du principe du moindre privilège, garantissant que les informations sensibles restent protégées même lorsqu’elles sont consultées par des utilisateurs autorisés qui ne nécessitent pas une visibilité complète des données.
Que ce soit sous le régime du RGPD en Europe, de la HIPAA dans le secteur médical ou du PCI DSS dans les services financiers, les organisations doivent démontrer des mesures proactive de protection des données. Grâce à des politiques de masquage complètes, les équipes peuvent traiter, analyser et tester des ensembles de données réalistes sans jamais exposer les valeurs sensibles originales à du personnel non autorisé.
Sans masquage, même des utilisateurs internes bien intentionnés peuvent avoir accès à des données confidentielles dont ils n’ont pas besoin — augmentant le risque de fuite, d’utilisation abusive ou de non-conformité réglementaire. En introduisant le masquage dans les flux de travail quotidiens, les organisations réduisent considérablement l’exposition à travers les chaînes de développement, les outils analytiques et les interactions avec les fournisseurs, sans compromettre la productivité ni la fidélité des données.
| Réglementation | Clause | Exigence de masquage |
|---|---|---|
| RGPD | Art. 32 | Pseudonymisation des données personnelles |
| PCI DSS 4.0 | 3.4 | Rendre le PAN illisible (tokenisation, masquage) |
| HIPAA | §164.514(b) | Désidentifier 18 identifiants PHI |
| DORA | Art. 9 | Protéger les ensembles de données utilisés dans les tests de résilience |
Le masquage dynamique permet un accès sécurisé aux systèmes de production en temps réel, tandis que le masquage statique crée des ensembles de données assainis parfaits pour les environnements de formation, les collaborations avec des fournisseurs ou les tests d’assurance qualité. DataSunrise simplifie ces deux méthodes via des interfaces de configuration intuitives et un support robuste des schémas de base de données complexes et des déploiements en clouds hybrides.
Masquage des données — Résumé, étapes et vérifications rapides
Résumé
- Objectif : limiter l’exposition des valeurs sensibles tout en conservant l’utilité du jeu de données.
- Modes : dynamique (au moment de la requête), statique (copies assainies), in situ (jeux de données non productifs).
- Alignement : conforme à la pseudonymisation RGPD, la désidentification HIPAA, et le masquage PCI DSS.
Étapes de mise en œuvre
- Découvrir et classifier les champs (PII/PHI/PCI) dans toutes les sources.
- Définir les rôles et les niveaux de visibilité requis.
- Sélectionner le mode selon le cas d’usage (dynamique pour la production ; statique pour le développement/test/fournisseur).
- Choisir les algorithmes (rédaction, substitution, FPE, tokenisation) selon le type de colonne.
- Configurer les règles au niveau du schéma/table/colonne ; préserver l’intégrité référentielle.
- Valider en environnement de staging ; confirmer le comportement des applications et la précision des analyses.
- Surveiller les performances et ajuster la portée pour contrôler la latence.
- Documenter les politiques ; planifier des revues périodiques au fur et à mesure de l’évolution des schémas.
Sélection d’algorithme
| Type de données | Approche recommandée | Notes |
|---|---|---|
| PAN / données de carte | Masquer BIN + 4 derniers chiffres / tokenisation | Alignement avec PCI DSS Exigence 3.4 |
| Emails / noms d’utilisateur | Substitution préservant le format | Conserver la forme domaine/utilisateur pour UX |
| PII en texte libre | Substitution par dictionnaire/regex | Scanner logs, commentaires, blocs JSON |
| Dates / montants | Injection de bruit / regroupement | Préserver l’ordre/statistiques |
| IPs / localisations | Généralisation / randomisation | Maintenir la région si nécessaire |
Vérifications rapides
- Les colonnes masquées restent-elles valides pour la logique d’application et les rapports ?
- Les transformations sont-elles irréversibles pour les utilisateurs non privilégiés ?
- L’intégrité référentielle est-elle préservée entre les tables liées ?
- La latence ajoutée reste-t-elle dans les SLA fixés en charge maximale ?
Cas d’usage courants du masquage des données
Les organisations mettent en œuvre le masquage des données dans divers scénarios pour maintenir la sécurité tout en permettant les opérations commerciales :
- Collaboration avec des fournisseurs : Partager des ensembles de données avec des partenaires tiers tout en préservant la confidentialité des clients et les informations concurrentielles. Le masquage des données garantit que les fournisseurs externes, sous-traitants et prestataires de services peuvent accomplir leurs tâches efficacement sans accéder aux données sensibles brutes, réduisant ainsi le risque de violation dans des environnements externes moins contrôlés.
- Prévention des erreurs : Protection contre les expositions accidentelles résultant d’erreurs d’opérateur, d’erreurs administratives ou de mauvaises configurations système. Le masquage sert de couche de sécurité supplémentaire, garantissant que même si des données privilégiées sont exportées, enregistrées ou consultées incorrectement, les champs sensibles restent illisibles et l’impact de l’erreur humaine est minimisé.
- Développement et tests : Fournir des ensembles de données réalistes pour les tests d’applications, la formation machine learning et l’optimisation des performances sans risques pour la confidentialité. Le masquage permet aux équipes de travailler avec des données structurellement exactes, proches de la production, soutenant le débogage, les tests de charge, la formation de modèles et les contrôles d’intégration tout en empêchant l’utilisation des vraies identités clients ou champs réglementés.
- Analytique et rapports : Permettre aux data scientists et analystes de travailler avec des données proches de la production tout en respectant la conformité aux réglementations sur la confidentialité. Les jeux de données masqués conservent les propriétés statistiques et relations critiques, permettant des analyses de qualité, tableaux de bord et prévisions sans exposer de données personnelles ou violer des normes telles que RGPD, HIPAA ou PCI DSS.
Exemples de données masquées
Les stratégies de masquage varient significativement selon les exigences de classification, les niveaux d’autorisation utilisateur et les politiques de conformité spécifiques. Certains systèmes exigent une rédaction complète, tandis que d’autres autorisent une substitution préservant le format qui maintient l’utilité des données. DataSunrise prend en charge ces deux approches sur des bases de données structurées et dans des référentiels de données non structurées.
-- Avant masquage : 4024-0071-8423-6700 -- Après masquage : XXXX-XXXX-XXXX-6700
| Méthode de masquage | Données originales | Données masquées |
|---|---|---|
| Masquage de carte de crédit | 4111 1111 1111 1111 | 4111 **** **** 1111 |
| Masquage d’email | [email protected] | j***e@e*****e.com |
| Masquage d’URL | https://www.example.com/user/profile | https://www.******.com/****/****** |
| Masquage de numéro de téléphone | +1 (555) 123-4567 | +1 (***) ***-4567 |
| Randomisation d’adresse IP | 192.168.1.1 | 203.45.169.78 |
| Randomisation de date avec conservation de l’année | 2023-05-15 | 2023-11-28 |
| Masquage par fonction personnalisée | Secret123! | S****t1**! |
| Substitution basée sur dictionnaire | John Smith, Software Engineer, New York | Ahmet Yılmaz, Data Analyst, Chicago |
Étapes de mise en œuvre du masquage des données
La mise en œuvre réussie du masquage des données nécessite une planification systématique et une exécution sur plusieurs phases :
- Découverte et classification des données : Localiser les champs sensibles dans toute votre infrastructure en utilisant des outils de découverte automatisée qui identifient les PII, les données financières et les informations réglementées dans les bases et applications.
- Cartographie des politiques et définition des rôles : Établir des politiques complètes de masquage basées sur les rôles utilisateurs, classifications de sensibilité des données et exigences réglementaires spécifiques à votre industrie et votre implantation géographique.
- Configuration des règles et tests : Définir des règles de masquage granulaires au niveau schéma, table, colonne ou type de données, en assurant que les données masquées conservent l’intégrité référentielle et la cohérence de la logique métier.
- Validation et déploiement : Tester minutieusement la fonction de masquage dans des environnements de staging avant déploiement en production, validant que les applications continuent à fonctionner correctement avec les jeux de données masqués.
- Surveillance et maintenance : Établir une surveillance continue pour assurer que les politiques de masquage restent efficaces au fur et à mesure de l’évolution des structures de données et de l’introduction de nouveaux types de données sensibles.
Types de masquage des données
| Algorithme | Conserve le format ? | Risque de ré-identification | Idéal pour |
|---|---|---|---|
| Rédaction | Non | Faible | Logs, captures d’écran |
| Tokenisation | Oui | Très faible* | Jetons de paiement |
| Randomisation | Optionnel | Faible | Jeux de données PII |
| Chiffrement préservant le format (FPE) | Oui | Très faible | Applications héritées |
*Sous réserve de contrôles de détokénisation basés sur coffre-fort.
Masquage dynamique
Le masquage dynamique applique l’obfuscation des données lors de l’exécution des requêtes sans modifier définitivement les données sources. Cette approche offre un contrôle d’accès en temps réel idéal dans les systèmes multi-utilisateurs en production où la visibilité des données doit varier dynamiquement selon les rôles et le contexte d’accès.
CREATE VIEW masked_customers AS
SELECT
id,
name,
CASE
WHEN current_user = 'admin_user' THEN credit_card
ELSE regexp_replace(credit_card, '^\d{4}-\d{4}-\d{4}-(\d{4})$', 'XXXX-XXXX-XXXX-\1')
END AS credit_card
FROM customers;
Masquage statique
Le masquage statique crée des copies assainies permanentes des bases de production, permettant un partage et une distribution sécurisés des données sans risques permanents pour la confidentialité. Ces ensembles masqués peuvent être exportés, partagés avec des partenaires externes ou utilisés pour des projets analytiques à long terme sans enfreindre les réglementations sur la confidentialité. Cette approche est particulièrement utile pour la conformité ISO 27001 et la préparation aux audits réglementaires.
Masquage in situ
Le masquage in situ transforme les données directement au sein des bases non productives existantes, notamment pendant les cycles de tests pré-release ou la préparation des environnements sandbox. Cette méthode élimine le besoin de duplication de l’infrastructure de stockage tout en assurant que les équipes de développement travaillent avec des données réalistes mais protégées.
Exigences essentielles pour le masquage
Les implémentations efficaces de masquage des données doivent satisfaire plusieurs exigences critiques pour garantir à la fois sécurité et utilité opérationnelle :
- Préservation de données réalistes : Les données masquées doivent ressembler et se comporter comme des données réelles pour assurer une intégration fluide avec les systèmes existants. Les valeurs substituées doivent conserver la même structure, format et distribution statistique que les originales — par exemple, les numéros de cartes masqués doivent passer la validation par somme de contrôle, et les dates masquées doivent rester dans des intervalles logiques. Ce réalisme permet aux applications, à l’analyse et aux environnements de test de fonctionner normalement sans risquer d’exposer des informations sensibles.
- Transformation irréversible : Le processus de masquage doit être conçu de sorte qu’il soit mathématiquement impossible de récupérer les données originales. Une forte randomisation et des algorithmes cryptographiques empêchent toute ingénierie inverse ou ré-identification par motifs. Cette transformation unidirectionnelle est une pierre angulaire de la conformité avec des réglementations telles que le RGPD et la HIPAA, qui exigent que les données anonymisées ne puissent pas être reliées aux individus.
- Comportement cohérent : Pour maintenir l’intégrité des données, la logique de masquage doit produire des résultats identiques pour une même entrée à travers tous les systèmes et périodes. Par exemple, si un identifiant client ou numéro employé apparaît dans plusieurs tables, il doit être masqué de la même manière partout afin de préserver la précision relationnelle. Cette cohérence soutient des tests, des rapports et des audits fiables sans compromettre la sécurité.
- Optimisation des performances : Le masquage efficace doit équilibrer sécurité et efficacité. Le processus doit introduire une surcharge minimale et ne pas ralentir les systèmes de production ou les requêtes analytiques. Des algorithmes optimisés et des techniques de traitement parallèle permettent de protéger rapidement de grands ensembles de données — assurant un contrôle de sécurité fort sans affecter la performance opérationnelle ni l’expérience utilisateur.
Masquage des données dans les cadres de conformité
Les régulateurs définissent le masquage des données comme pseudonymisation, désidentification ou minimisation des données. Voici comment les principaux cadres décrivent ces exigences et comment le masquage y répond :
| Cadre | Exigence | Alignement via le masquage |
|---|---|---|
| RGPD | Art. 32 — pseudonymiser ou anonymiser les données personnelles | Le masquage dynamique empêche l’exposition des PII bruts aux utilisateurs non privilégiés. |
| HIPAA | §164.514 — désidentifier 18 identifiants PHI | Le masquage statique crée des jeux de données sans PHI pour tests, formation et recherche. |
| PCI DSS | Exigence 3.4 — rendre le PAN illisible sauf BIN + 4 derniers chiffres | Le masquage préservant le format assure la conformité pour les données de carte de paiement. |
| SOX | Maintenir l’intégrité des données de reporting financier | Le masquage des copies de test empêche la fuite de données financières sensibles. |
En alignant les politiques de masquage avec les mandats de conformité, DataSunrise permet aux entreprises de protéger les informations sensibles tout en produisant des preuves prêtes pour les audits à travers bases, clouds et environnements hybrides.
Résultats commerciaux du masquage des données
- Réduction de l’exposition aux violations : Jusqu’à 60 % de champs sensibles en moins visibles aux utilisateurs non autorisés
- Efficacité de conformité : Preuves d’audit générées en heures, pas en semaines
- Vitesse opérationnelle : Cycles QA et tests accélérés de ~30 % grâce à des jeux de données sécurisés et proches de la production
- Réduction des risques juridiques : Alignement direct avec les clauses RGPD, HIPAA, PCI DSS
Applications sectorielles
- Finance : Masquage des PAN et PII pour la conformité PCI DSS et SOX
- Santé : Désidentification des PHI pour respecter les règles de confidentialité HIPAA
- SaaS & Cloud : Masquage multi-locataires pour garantir la séparation des données conforme au RGPD
- Commerce de détail : Protection des données clients dans les pipelines analytiques sans perte d’informations
Extraits natifs de masquage des données selon les plateformes
La plupart des bases de données offrent un support natif du masquage limité, souvent nécessitant du code personnalisé ou des extensions. Voici des exemples pour SQL Server et Oracle :
SQL Server : Masquage dynamique intégré
-- Masquer la colonne carte de crédit avec exposition partielle
CREATE TABLE Customers (
Id INT IDENTITY PRIMARY KEY,
FullName NVARCHAR(100),
CreditCard VARCHAR(19) MASKED WITH (FUNCTION = 'partial(0,"XXXX-XXXX-XXXX-",4)')
);
-- Résultat: 4111-2222-3333-4444 → XXXX-XXXX-XXXX-4444
Oracle : Politique de base de données privée virtuelle (VPD)
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'HR',
object_name => 'EMPLOYEES',
policy_name => 'mask_ssn_policy',
function_schema => 'SEC_ADMIN',
policy_function => 'mask_ssn_fn',
statement_types => 'SELECT'
);
END;
/
Les deux exemples démontrent un masquage natif à la plateforme, mais manquent de flexibilité pour appliquer des règles conscientes des rôles sur plusieurs bases simultanément.
Masquage dans le contexte de conformité
Les différentes réglementations qualifient le masquage soit de pseudonymisation, désidentification ou minimisation des données. Une exigence typique est d’assurer une transformation irréversible tout en maintenant l’utilisabilité. Voici un rapide tableau de conformité :
| Cadre | Objectif du masquage | Limite native |
|---|---|---|
| RGPD | Pseudonymiser les données personnelles | Pas de masquage basé sur les rôles cohérent |
| HIPAA | Désidentifier les identifiants PHI | Pas d’application des politiques au niveau champ |
| PCI DSS | Masquer le PAN sauf BIN et 4 derniers chiffres | Spécifique à la plateforme, pas unifié |
Le masquage natif satisfait les clauses basiques, mais les plateformes unifiées comme DataSunrise offrent une couverture multi-réglementaire prête à l’emploi.
Masquage des données avec DataSunrise
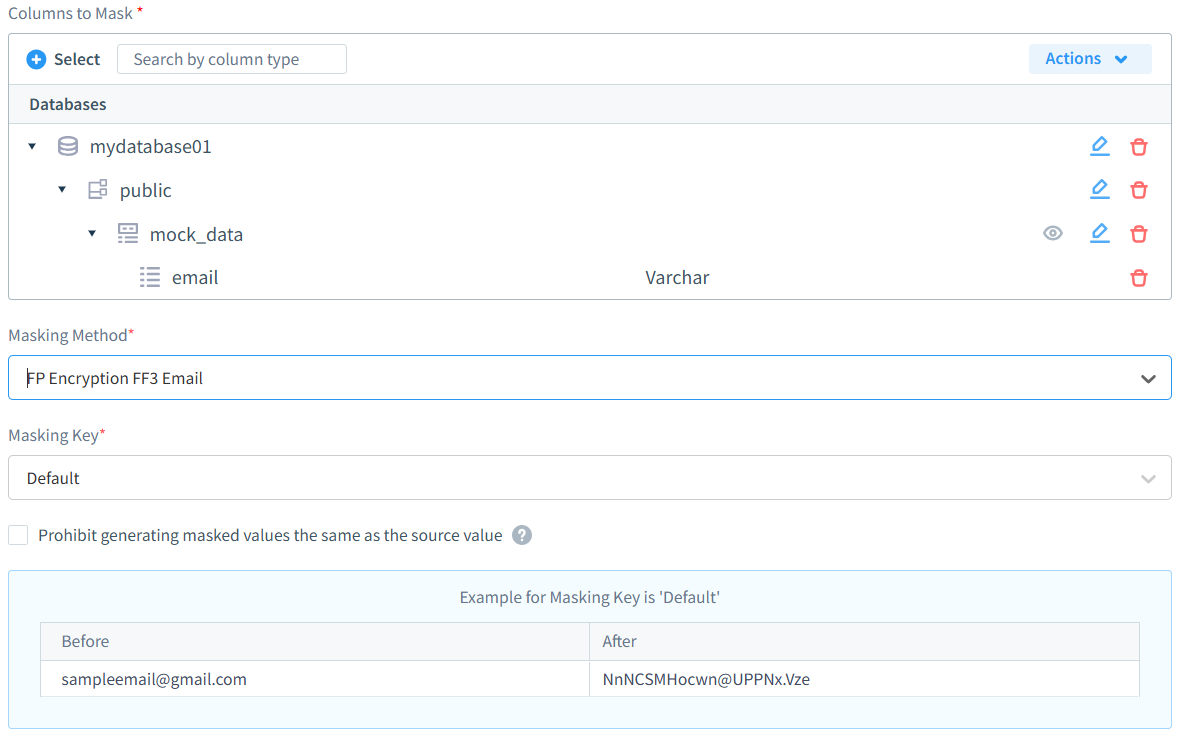
DataSunrise fournit des capacités de masquage de niveau entreprise conçues pour les exigences modernes de protection des données :
- Modes de masquage flexibles : Prise en charge complète des techniques de masquage dynamique en temps réel et statique hors-ligne, permettant aux organisations de choisir l’approche optimale selon les cas d’usage.
- Contrôles d’accès intelligents : Politiques de masquage sensibles aux rôles utilisateur et algorithmes préservant le format qui maintiennent l’utilité des données tout en appliquant des protections strictes de confidentialité.
- Intégrations d’entreprise : Intégration transparente avec les systèmes IAM existants, plateformes SIEM et moteurs d’application de politiques pour rationaliser les opérations de sécurité et les rapports de conformité.
- Automatisation de la conformité : Fonctionnalités intégrées de journalisation d’audit et de reporting spécialement conçues pour les exigences RGPD, PCI DSS, HIPAA et SOX.
- Architecture évolutive : Support pour environnements cloud natifs, hybrides et legacy avec impact minimal sur les performances et haute disponibilité.
Mise à l’échelle du masquage des données dans des environnements complexes
À mesure que les architectures évoluent, le masquage des données doit s’adapter aux clouds hybrides, microservices distribués et charges de travail mixtes. Les organisations rencontrent souvent des difficultés à maintenir une logique de masquage cohérente à travers bases relationnelles, magasins NoSQL et même référentiels non structurés comme le stockage d’objets ou les logs.
- Application uniforme des politiques multi-plateformes : Appliquer les règles de masquage de manière homogène sur PostgreSQL, Oracle, SQL Server, MongoDB et Amazon S3 — garantissant un comportement cohérent et conforme quelle que soit la technologie backend.
- Support des données non structurées et semi-structurées : Masquer les valeurs sensibles intégrées dans JSON, XML, fichiers log et contenus générés par les utilisateurs en utilisant des règles basées sur regex ou dictionnaires.
- Automatisation CI/CD du masquage : Intégrer la validation du masquage dans les pipelines DevOps via l’intégration des règles DataSunrise dans les workflows pré-déploiement. Empêcher la fuite de champs sensibles non masqués vers les environnements staging ou test.
- Cadres de validation et QA : Exécuter des contrôles automatisés de cohérence pour assurer que les règles de masquage ne perturbent pas l’analyse downstream, les tableaux de bord ou la logique applicative.
- Versioning et retour arrière des politiques : Maintenir des politiques de masquage versionnées pouvant être restaurées ou mises à jour sans interruption — crucial pour les environnements agiles et l’adaptation aux évolutions réglementaires.
Avec ces capacités, le masquage des données évolue d’un contrôle isolé à une couche dynamique et centralisée de protection des données. Plutôt que de dépendre de scripts ad hoc ou de correctifs isolés, les équipes disposent d’un moteur d’application unifié capable de s’adapter à tout environnement — cloud natif, legacy, ou hybride.
FAQ sur le masquage des données
Quel est l’objectif du masquage des données ?
Le masquage des données substitue des valeurs sensibles par des surrogats réalistes pour empêcher l’accès non autorisé. Il permet une utilisation sécurisée des jeux de données dans les tests, l’analytique et le partage avec les fournisseurs sans exposer les informations originales.
En quoi le masquage des données diffère-t-il de la tokenisation ?
Le masquage crée des surrogats non réversibles pour la confidentialité et la conformité, tandis que la tokenisation remplace les valeurs par des jetons stockés dans un coffre-fort. La tokenisation supporte la récupération réversible, la rendant idéale pour le traitement des paiements sous PCI DSS.
Quels cadres de conformité exigent le masquage des données ?
Des cadres tels que le RGPD (pseudonymisation), la HIPAA (désidentification), et le PCI DSS (masquage des données de titulaires de carte) mentionnent explicitement le masquage ou les contrôles équivalents pour protéger les champs sensibles.
Quand utiliser le masquage dynamique ou statique ?
- Masquage dynamique : Obfuscation en temps réel lors de l’exécution des requêtes ; idéal pour les bases de production avec accès basé sur les rôles.
- Masquage statique : Création de copies de base de données assainies ; préférable pour le développement, les tests et la collaboration avec les fournisseurs.
Quelles sont les exigences essentielles pour un masquage efficace ?
- Préserver des formats réalistes et la logique métier.
- Garantir que les transformations soient irréversibles.
- Appliquer des règles cohérentes et répétables à travers les environnements.
- Maintenir une faible latence en production.
Quels outils simplifient le masquage à l’échelle entreprise ?
DataSunrise fournit un masquage statique et dynamique centralisé avec des politiques conscientes des rôles, génération de rapports réglementaires et intégration dans les pipelines DevOps — éliminant les scripts ad hoc et solutions isolées.
L’avenir du masquage des données
Le masquage des données a largement dépassé sa fonction originale de dissimulation des numéros de cartes de crédit ou des identifiants clients dans les environnements de test. Aujourd’hui, il représente une couche dynamique et intelligente de la sécurité des entreprises. Les innovations émergentes transforment la manière dont le masquage est découvert, déployé et maintenu à grande échelle. La découverte automatisée assistée par IA permet désormais aux systèmes de détecter et classifier automatiquement les informations sensibles à travers sources structurées et non structurées, tandis que l’approche « policy-as-code » permet aux organisations de versionner, auditer et appliquer les règles de masquage de manière cohérente à travers les pipelines CI/CD et les workflows DevOps.
Les principaux fournisseurs cloud et analytiques intègrent également des capacités de masquage natives directement dans leurs écosystèmes, garantissant que les données sensibles restent protégées pendant l’ingestion, la transformation et les requêtes analytiques. Cela inclut l’application automatique du masquage lors des mouvements de données entre environnements — par exemple entre production, tests et pipelines de formation IA — réduisant ainsi les risques d’exposition lors de traitement à grande échelle.
Dans le cadre d’une stratégie unifiée de protection des données, les technologies avancées de masquage s’intègrent désormais parfaitement à la supervision des activités des bases de données, à l’automatisation de la conformité et à la découverte des données sensibles. Ensemble, elles forment un tissu de sécurité adaptatif capable de répondre aux menaces évolutives, aux exigences réglementaires et aux besoins métiers. Dans les années à venir, le masquage ne sera plus seulement perçu comme un contrôle de confidentialité, mais comme une protection proactive, pilotée par IA, au cœur de la gouvernance moderne des données et de la transformation numérique sécurisée.
Masquage natif vs DataSunrise
| Capacité | Masquage natif en base de données | DataSunrise |
|---|---|---|
| Couverture multi-bases | Limitée (SQL Server, Oracle uniquement) | Oui — Oracle, PostgreSQL, MySQL, MongoDB, SQL Server, bases cloud |
| Options dynamique vs statique | Un seul ou l’autre selon le moteur | Les deux, configurés centralement |
| Application des politiques | Manuel, spécifique à la BD | Conscient des rôles, politique-as-code, versionné |
| Rapports de conformité | Non intégré | Rapports préconçus RGPD, HIPAA, PCI DSS, SOX |
| Intégration | Minimale | IAM, SIEM, CI/CD, pipelines cloud natifs |
Le masquage natif offre un point de départ, mais DataSunrise fournit des contrôles cross-plateformes de niveau entreprise.
Conclusion
Alors que les organisations continuent de gérer des volumes de données en rapide expansion à travers des systèmes et architectures divers, la protection des informations sensibles est devenue à la fois une priorité stratégique et une exigence réglementaire. Le masquage des données s’est imposé comme l’une des méthodes les plus fiables pour prévenir l’accès non autorisé aux champs sensibles, garantissant que les informations personnelles et confidentielles restent occultées tout en permettant aux ensembles de données de rester pleinement fonctionnels pour un usage légitime. Cela permet aux équipes d’effectuer des analyses, de collaborer avec des fournisseurs externes et de mener des activités de développement ou de test sans exposer de données réelles — préservant la confidentialité, soutenant la conformité et maintenant l’efficacité opérationnelle.
DataSunrise simplifie et automatise le masquage à l’échelle entreprise sur infrastructures on-premises, hybrides et multi-cloud. Sa plateforme unifiée prend en charge le cycle complet de protection des données — incluant la découverte des données sensibles, la classification automatisée, le masquage dynamique et statique, la gestion granulaire des politiques et les rapports prêts pour les audits. Des fonctionnalités telles que le masquage statique des données fournissent un moyen sécurisé et cohérent de préparer des jeux de données sûrs pour le développement, l’analytique et la collaboration externe. Avec une automatisation intelligente, un faible impact sur la performance et une large compatibilité avec les technologies majeures de base de données, DataSunrise permet aux organisations d’appliquer des contrôles stricts de confidentialité, de se conformer aux réglementations mondiales et d’alimenter en toute sécurité l’innovation pilotée par les données. Dans un monde où les risques d’exposition des données continuent de croître, une stratégie moderne et automatisée de masquage s’impose comme essentielle à la sécurité et à la résilience à long terme.
Suivant
