
Qu’est-ce que la partition ?
À mesure que les bases de données augmentent en taille et en complexité, la performance et la maintenabilité en pâtissent souvent. Le partitionnement offre une solution en divisant de gros objets de la base de données — tels que les tables et les index — en segments plus petits et plus faciles à gérer. Cette technique est largement utilisée pour accélérer l’exécution des requêtes, réduire les coûts de stockage et simplifier la gestion du cycle de vie des données dans les systèmes d’entreprise et sur les plates-formes basées sur le cloud.
Les principaux avantages incluent une meilleure contrôlabilité, des performances accrues et une disponibilité améliorée. Cette approche permet aux administrateurs d’optimiser et de gérer indépendamment différentes parties de la base de données, améliorant ainsi l’efficacité des requêtes et la disponibilité du système tout en permettant des stratégies de gestion plus ciblées.
- Dans certains cas, cette méthode améliore les performances lors de l’accès aux tables partitionnées.
- Elle peut également définir des colonnes principales dans les index, réduisant ainsi la taille des index et augmentant l’efficacité de l’accès mémoire. Lorsque qu’une grande partie d’une section est utilisée dans l’ensemble des résultats, l’analyse de cette section est beaucoup plus rapide que celle de données dispersées.
- Un chargement massif et une suppression sont possibles en ajoutant ou en supprimant simplement des sections, ce qui améliore les performances.
- Les informations rarement consultées peuvent être déplacées vers des systèmes de stockage à moindre coût.
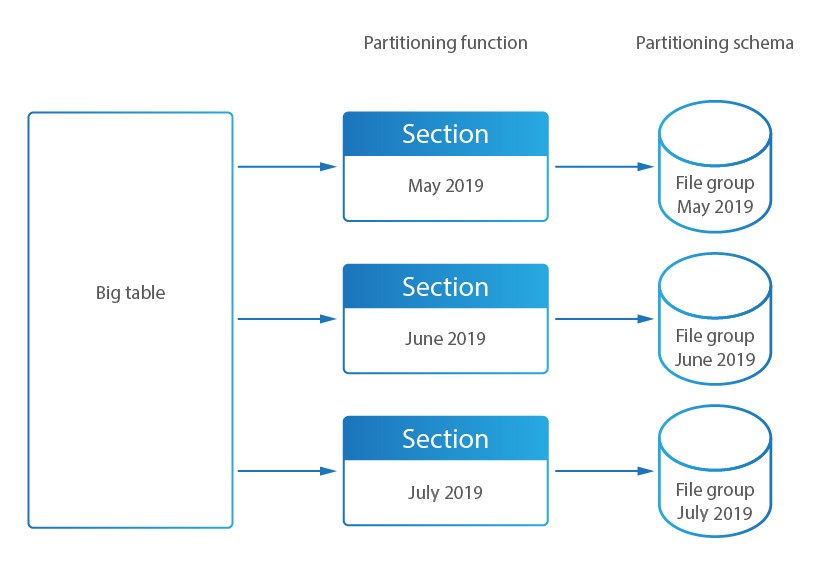
Chez DataSunrise, de grandes tables de stockage d’audit sont divisées en sections plus petites afin d’améliorer l’accès et les performances. La surveillance des activités de la base de données de DataSunrise stocke les résultats directement dans cette base de données interne.
- Les administrateurs peuvent gérer les données plus facilement en les divisant en segments basés sur le temps, qu’ils peuvent ensuite archiver ou exclure des requêtes.
- La vitesse de lecture/écriture s’améliore considérablement lors de l’interaction avec les tables de stockage.
- La suppression des anciens journaux d’audit devient plus rapide et plus efficace.
DataSunrise prend en charge cette technique pour les plates-formes de bases de données de stockage d’audit suivantes :
- PostgreSQL
- MySQL
- MS SQL Server
Paramètres de partitionnement
Ils se trouvent dans Paramètres système -> Paramètres supplémentaires.
- Longueur des partitions (jours) – Définit la durée de chaque section (ou minutes si AuditPartitionShort = 1). Situé dans Paramètres système -> Stockage d’audit. Le changement de ce paramètre réinitialise la structure : les sections existantes sont supprimées et remplacées par de nouvelles.
- AuditPartitionCountCreatedInAdvance – Nombre de partitions pré-creées pour le futur. Ces espaces vides permettent une écriture continue des données.
- AuditPartitionFirstEndDateTime – Spécifie la limite supérieure temporelle de la première section. Utile pour aligner les partitions sur un repère temporel clair (par exemple, lundi 00:00:00).
Partitionnement pour la conformité et la conservation
De nombreuses réglementations sur les données exigent la suppression ou l’archivage en temps voulu des données sensibles. Le partitionnement facilite la gestion des cycles de vie des données en isolant les enregistrements anciens dans des segments distincts. Cela permet une suppression plus rapide, un archivage facilité et une meilleure préparation aux audits — en particulier dans les industries soumises à des politiques de conservation strictes telles que la santé, la finance et les télécommunications.
Partitionnement dans les environnements de données modernes
Dans les environnements de big data, la segmentation des données est cruciale. De nombreuses plates-formes cloud offrent désormais des options de partitionnement automatique. AWS Redshift utilise des styles de distribution pour un agencement optimal des données. Azure Synapse emploie des méthodes de distribution pour améliorer la performance des requêtes. La logique basée sur le partitionnement fonctionne également très bien avec les data lakes traitant des pétaoctets d’informations. Elle permet des requêtes plus rapides dans les applications BI et supporte l’accès basé sur le temps aux données historiques ou archivées. Des stratégies appropriées contribuent à réduire les coûts de stockage et à s’aligner avec les politiques de conservation.
Stratégies efficaces de distribution des données
La création de stratégies efficaces de distribution des bases de données nécessite une planification minutieuse basée sur les modèles d’accès et les exigences métier. L’organisation par intervalle fonctionne mieux pour des valeurs séquentielles comme les dates, permettant aux équipes d’accéder rapidement aux données récentes tout en archivant les informations plus anciennes.
La distribution par hachage répartit uniformément les données sur des segments de stockage, idéale pour l’équilibrage de la charge dans des environnements à haute concurrence. Les approches basées sur des listes organisent les enregistrements par valeurs catégorielles spécifiques, les rendant parfaites pour une segmentation géographique ou départementale.
De nombreuses organisations mettent en œuvre des méthodes hybrides, combinant plusieurs techniques de distribution pour maximiser les bénéfices en termes de performance tout en minimisant les frais de maintenance. Une analyse régulière de l’élagage garantit que les requêtes ciblent systématiquement uniquement les segments de données nécessaires, offrant ainsi des performances optimales à mesure que les volumes de données augmentent.
Gestion des partitions dans DataSunrise
DataSunrise prend en charge la segmentation automatisée des données : elle crée les tables requises (pour PostgreSQL), maintient à jour les fonctions, schémas, groupes de fichiers et index (pour MS SQL), et ajuste les clés pour correspondre aux modèles de partitionnement natifs (pour MySQL). DataSunrise gère l’ensemble du cycle de vie des sections, de leur création à leur nettoyage.
Le système exécute des SELECT via la table principale, tandis qu’il dirige les INSERT/UPDATE vers des sections spécifiques (sauf pour MS SQL Server), améliorant ainsi les performances en écriture.
Noms des partitions et des tables
PostgreSQL crée des tables filles comme partitions en utilisant le format <nom_table>_p<datetime>, où <datetime> représente la limite supérieure au format AAAAMMJJhhmm.
MySQL utilise les mécanismes natifs pour le partitionnement. Il génère les noms de partition en utilisant le format p<datetime>, en suivant la même convention de timestamp.
MS SQL Server applique le partitionnement en utilisant une approche basée sur un schéma, plutôt qu’avec des tables filles.
