
Datenentdeckung
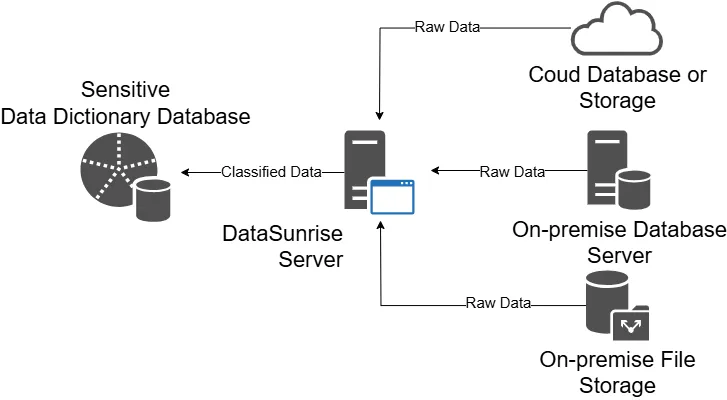
Haben Sie sich jemals gefragt, welche Kennzahlen in Ihren Daten verfügbar sind? Gibt es Kennzahlen für Churn Rate und Retention Rate? Oder vielleicht kämpfen Sie mit Compliance-Verfahren und fragen sich: ‘Bin ich in Gefahr eines sensiblen Datenlecks?’ Die Datenentdeckung ist ein entscheidender Prozess, der Unternehmen und Organisationen hilft, ihre umfangreichen Datenressourcen zu verstehen. Dazu gehört es, Daten aus verschiedenen Quellen zu betrachten, um Trends, Muster und Datentypen zu identifizieren.
Unternehmen können wichtige Erkenntnisse entdecken und die Business Intelligence verbessern, indem sie ihre Daten besser verstehen. Dies hilft auch bei der Datensicherheit, Governance und Datenschutz. Wenn die Datenpipeline ausfällt, hilft die Datenentdeckung dabei, herauszufinden, was mit den Daten nicht stimmt.
Die Macht der Datenentdeckung
Organisationen haben heute möglicherweise eine überwältigende Menge an Daten zu handhaben. Dies kann zu “dunklen Daten” führen, die ungenutzt bleiben. Dunkle Daten können potenziell rechtliche und sicherheitsrelevante Risiken schaffen. Es gibt mehrere Gründe, die Datenentdeckung zu implementieren.

Analysten können Datenkataloge und Wörterbücher verwenden, um verstreute Daten zu finden und zu organisieren. Anschließend können sie die Daten bereinigen und kombinieren, um wichtige Erkenntnisse zu entdecken.
Verbesserung der Datenentdeckung mit KI und maschinellem Lernen
DataSunrise nutzt ML-Tools hervorragend für die Datensicherheit. Künstliche Intelligenz (KI) transformiert die Prozesse der Datenentdeckung in der Daten-Governance. Durch die Nutzung von KI und maschinellem Lernen können Organisationen ihre Datenexplorationsbemühungen rationalisieren. Dies führt zu schnelleren Erkenntnissen und effizienteren Entscheidungsprozessen.
KI verbessert die Datenentdeckung in mehreren Schlüsselbereichen:
- Automatisierung der Datenklassifikation
- Identifizierung von Mustern und Anomalien
- Vorschlag relevanter Datenquellen
Maschinelle Lernalgorithmen übertreffen beim Kategorisieren großer Informationsmengen. Diese automatisierte Datenklassifikation spart Zeit und reduziert menschliche Fehler. Sie ist besonders nützlich im Umgang mit großen Datensätzen.
Datenentdeckung in der Data Science
Die Datenentdeckung bildet die Grundlage erfolgreicher Data-Science-Projekte. Es handelt sich um den Prozess des Findens und Verstehens verfügbarer Datenquellen. Durch diese Erkundung entdecken Datenwissenschaftler wertvolle Erkenntnisse und Muster. Effektive Datenentdeckung umfasst mehrere wichtige Schritte:
- Identifizierung relevanter Datenquellen
- Bewertung der Datenqualität und Vollständigkeit
- Durchführung einer ersten Datenanalyse
Die Datenklassifikation spielt in diesem Prozess eine entscheidende Rolle. Durch die Kategorisierung von Informationen können Wissenschaftler ihre Arbeit besser organisieren und priorisieren. Diese Klassifikation hilft beim sachgerechten Umgang mit sensiblen Daten.
DataSunrise bietet exzellente Unterstützung für Datenlager und -speicher, die häufig in der Datenwissenschaft verwendet werden, einschließlich Snowflake, Amazon Redshift und Athena, um nur einige zu nennen.
Da die Datenwissenschaft stark semi-strukturierte Daten nutzt, unterstützt DataSunrise die Datenentdeckung in Rohformaten (CSV, JSON), die sich in Speichern wie S3 oder in Ihrem Dateisystem befinden.
Stärkung der Business Intelligence durch Datenentdeckung
Die Datenentdeckung spielt eine entscheidende Rolle bei der Unterstützung von Business Intelligence-Initiativen.
Durch die Bereitstellung der richtigen Werkzeuge und Techniken für Analysten können Organisationen bessere Entscheidungen treffen, Prozesse verbessern und Wachstumschancen erkennen.
Die Dashboards können so angepasst werden, dass sie unterschiedlichen Gruppen von Menschen gerecht werden, wie z. B. Führungskräften und Frontline-Mitarbeitern. Auf diese Weise kann jeder leicht die Informationen finden, die er für Entscheidungen benötigt.
Datensicherheit und Compliance mit Python-basierter Datenentdeckung
Okay, Sie könnten sagen, es gibt Dutzende von Open-Source-Python-Tools auf dem Markt. Alles, was ich tun muss, ist, ein paar zu nehmen und meine eigene Datenentdeckungstoolchain zu erstellen.
Und das ist aus mehreren Gründen eine völlig gute Idee. Sie werden alles über Ihre Tools wissen und können in Zukunft jede gewünschte Datenentdeckung implementieren. Darüber hinaus sind die Gesamtkosten dieser einfachen Toolchain nur Ihre Zeit, um etwas Code zu schreiben.
Der mögliche Nachteil ist der folgende: Es kann eine Weile dauern, alle gewünschten Variationen zu implementieren. Sie könnten mit der Schwierigkeit der Skalierbarkeit und der Unterstützung Ihres Systems kämpfen, da neue Datenbanken veröffentlicht werden und ihr Treiberverhalten ändern.
Hier ist der Code, um E-Mails in einer PostgreSQL-Datenbank zu entdecken. Er sollte mit Ihren Datenbankverbindungsparametern funktionieren. Sie werden feststellen, dass es zwar keine Raketenwissenschaft ist, aber dennoch einige Kenntnisse über Infrastruktur und Python erfordert. Und dieser Code speichert die Suchergebnisse nicht.
import psycopg2
import re
# Verbindungsparameter definieren
db_params = {
'dbname': 'mydatabase01',
'user': 'postgres',
'password': 'pass',
'host': 'localhost'
}
# Verbindung zur Datenbank herstellen
try:
conn = psycopg2.connect(**db_params)
print("Mit der Datenbank verbunden")
except Exception as e:
print(f"Verbindung zur Datenbank nicht möglich: {e}")
exit()
# Funktion zur Suche nach E-Mail-Adressen in einem Schema
def find_emails_in_schema(schema):
try:
cursor = conn.cursor()
# Abfrage, um alle Tabellen im angegebenen Schema zu finden
cursor.execute(f"""
SELECT table_name
FROM information_schema.tables
WHERE table_schema = '{schema}'
""")
tables = cursor.fetchall()
email_pattern = re.compile(r'[\w\.-]+@[\w\.-]+')
for table in tables:
table_name = table[0]
# Abfrage, um alle Spalten der Tabelle auszuwählen
cursor.execute(f"""
SELECT column_name
FROM information_schema.columns
WHERE table_schema = '{schema}'
AND table_name = '{table_name}'
""")
columns = cursor.fetchall()
# Auswahl aller Daten aus der Tabelle
cursor.execute(f'SELECT * FROM {schema}.{table_name}')
rows = cursor.fetchall()
for row in rows:
for column, value in zip(columns, row):
if value and isinstance(value, str):
if email_pattern.search(value):
print(f'Gefundene E-Mail: {value} in Tabelle: {table_name}, Spalte: {column[0]}')
except Exception as e:
print(f"Fehler beim Finden von E-Mails: {e}")
finally:
cursor.close()
# Zu durchsuchendes Schema angeben
schema_name = 'public'
find_emails_in_schema(schema_name)
# Verbindung schließen
conn.close()
Der Code druckt Zeilen wie die folgenden:
Gefundene E-Mail: [email protected] in Tabelle: mock_data, Spalte: email
DataSunrise-Tools
DataSunrise umfasst alle Funktionen, die Sie für die Entdeckung sensibler (oder sonstiger) Daten benötigen. Im Folgenden bieten wir einige Beispiele aus der Benutzeroberfläche.
Im Folgenden finden Sie eine Auflistung von Informationstypen. Sie können so viele benutzerdefinierte Informationstypen erstellen, wie Sie möchten, jeder mit einem oder mehreren Attributen zur Entdeckung. Alternativ können Sie die Dutzenden von integrierten Typen verwenden, wenn Sie dies bevorzugen.
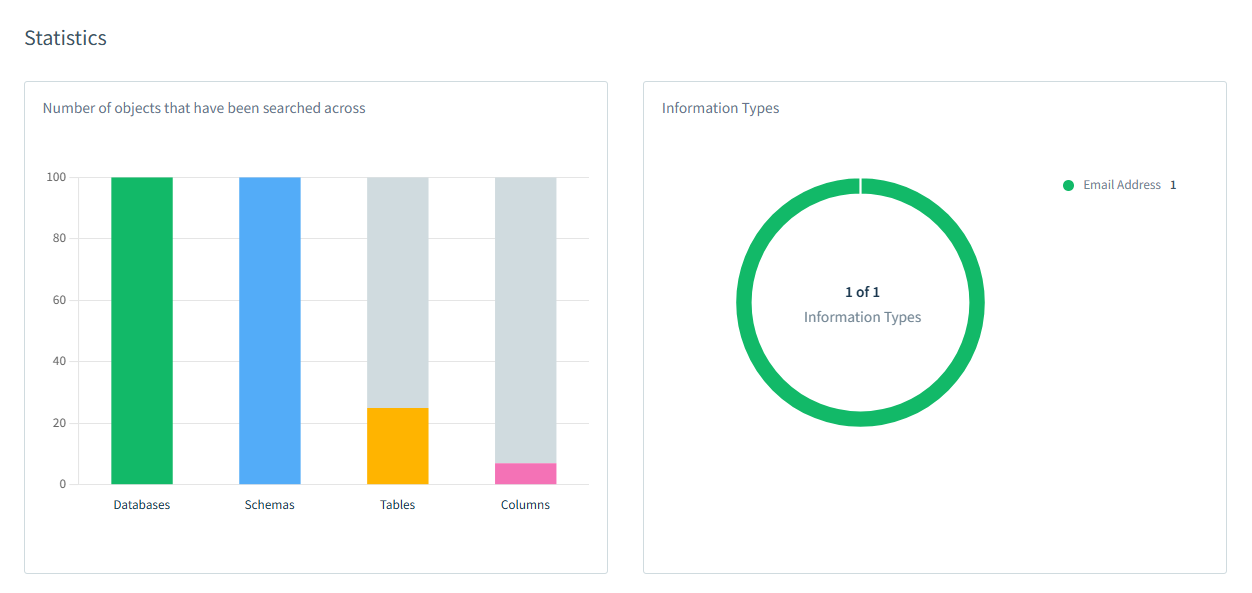
Nach Abschluss der Entdeckungsaufgabe können Sie detaillierte Informationen zu den Ergebnissen anzeigen. Zusätzlich können Sie die Menge der entdeckten Daten im Verhältnis zur Gesamtmenge in Ihren Schemata, Tabellen oder Spalten schätzen. Das untenstehende Bild zeigt, dass E-Mail-Adressen in 100 % der Ziel-Datenbanken, 100 % der Schemata, 22 % der Tabellen und weniger als 5 % der Spalten gefunden wurden.
Fazit
Die Datenentdeckung ist ein kritischer Prozess, der es Organisationen ermöglicht, das volle Potenzial ihrer Datenressourcen auszuschöpfen.
Unternehmen können fortschrittliche Technologien wie KI, maschinelles Lernen und Datenanalyse nutzen, um ihre Daten besser zu verstehen. Die Analyse von Daten hilft Unternehmen, Muster und Trends zu erkennen, um bessere Entscheidungen zu treffen und Innovationen voranzutreiben.
Diese Technologien können Unternehmen auch dabei helfen, neue Ideen zu generieren, indem sie verborgene Chancen aufdecken und zukünftige Markttrends vorhersagen.
Darüber hinaus können fortschrittliche Technologien Unternehmen helfen, sensible Informationen zu schützen, indem robuste Sicherheitsmaßnahmen wie Verschlüsselung, Zugangskontrollen und Bedrohungserkennungssysteme implementiert werden. Der Schutz von Daten hilft Unternehmen, Datenverletzungen und Cyberangriffe zu vermeiden, sodass ihre Informationen sicher und geschützt sind.
Der Einsatz fortschrittlicher Technologien kann Unternehmen dabei helfen, ihre Daten besser zu nutzen, innovativer zu sein und ihre sensiblen Informationen zu schützen. Dies kann zu einer besseren Leistung und einem Wettbewerbsvorteil im Markt führen.
Da die Datenmengen zunehmen, ist es für Organisationen wichtig, in Werkzeuge zur Datenentdeckung zu investieren, um vorauszubleiben.
DataSunrise bietet eine Vielzahl von Möglichkeiten, Daten zu entdecken. Kontaktieren Sie unser Team, um eine Demo zu buchen und zu erfahren, wie es geht.
