
Amazon S3 Sensitive Data Discovery Neue Fähigkeiten von DataSunrise
Einführung
Laut einer aktuellen Umfrage hosten mehr als 50 % der Unternehmen eine große Menge sensibler Daten in Cloud-Speichern wie S3 von Amazon.
DataSunrise Sensitive Data Discovery ist für die schnelle Datensuche, Klassifizierung und Verwaltung verfügbar. Die Suche und Analyse von Daten in Ihren Datenspeichern stellt sicher, dass Sie sensible Daten in Amazon S3 rechtzeitig, schnell und mühelos identifizieren können. Wir haben unser Werkzeug verbessert. Früher konnten wir halbstrukturierte und unstrukturierte Daten in S3 dank der NLP-Funktion entdecken, und jetzt können wir noch mehr.
DataSunrise Sensitive Data Discovery
Data Discovery für Amazon S3 hat neue Fähigkeiten zur Erkennung und zum Schutz sensibler Daten. Jetzt ist Data Discovery verfügbar für:
- Apache Parquet-Dateiformat;
- Halbstrukturierte Dateien wie XML, JSON, CSV;
- Unstrukturierte Textformate wie Microsoft Word-Dokumente;
- Bilder.
Data Discovery für S3 analysiert nicht nur Objekte, sondern auch deren Namen und Pfade. DataSunrise verbindet semantische Beziehungen mit dem Kontext des Objekts für eine vollständige und umfassende Entdeckung sensibler Daten. So müssen Sie sich keine Gedanken über die spezifischen Namen von Objekten machen, die sensible und private Informationen enthalten.
Vordefinierte und benutzerdefinierte Vorlagen für PII. DataSunrise verfügt über viele vordefinierte Vorlagen für die Suche nach sensiblen Daten wie Kreditkartennummern, Reisepässen, Führerscheinen. Für eine flexiblere Suche können Sie benutzerdefinierte Informationstypen verwenden (können mit regulären Ausdrücken, Lua-Skripten usw. eingerichtet werden). Dank dieser Filter erhalten Sie ein vollständiges Bild der gesammelten sensiblen Daten. Die Feinabstimmung der Entdeckung spart Ihre Zeit und andere Ressourcen. Das Wichtigste ist, dass Sie sicher sind, dass keine sensiblen Daten außer Kontrolle geraten und möglicherweise offengelegt werden.
Bedarfsabhängige Datenerkennung. Sie können Data Discovery nicht nur manuell über die Web-Konsole erstellen und ausführen. Verwenden Sie das Systemterminal mit der Befehlszeilenschnittstelle, um automatisierte Systeme zu erstellen, die auf Sicherheitsereignisse ohne manuelle Eingriffe reagieren.
Erkennung sensibler Daten in Bildern. Unternehmen, die sensible Daten in Bildern speichern (Führerschein, SSN usw.), werden erfreut sein, DataSunrise Data Discovery mit optischer Zeichenerkennung zu verwenden. Die Verwendung der Bildentdeckung ermöglicht es Ihnen, nach sensiblen Daten in Bildern dank der OCR-Engine zu suchen. Es extrahiert Text aus den Bildern, analysiert diese Informationen und findet private Daten aus Dokumenten. Unsere Bilddatenentdeckung unterstützt die folgenden Dateiformate: JPG, PNG, GIF, TIFF, PSD.
Kompakte und archivierte Dateien Data Discovery. Zusammen mit Objekten und verschiedenen Dateiformaten kann Data Discovery für S3 auch nach sensiblen Daten in komprimierten und archivierten Formaten suchen. Komprimierte Dateien ermöglichen es Ihnen, den genutzten Speicherplatz zu reduzieren und damit die Kosten zu senken. Archivierte Dateien ermöglichen es Ihnen, Dateien an einem Ort zu sammeln und zu gruppieren. Unabhängig von der Größe des Archivs werden sensible Daten entdeckt.
Leistung der sensiblen Datenerkennung
Die Erkennung sensibler Daten funktioniert auf verschiedenen Ebenen in S3. Zuerst können Sie Ihre S3-Buckets und -Objekte nach sensiblen Informationen durchsuchen. Es ist der einfachste Weg, private Informationen zu finden, die geschützt werden sollten. Aber wenn Sie viele S3-Buckets und Objekte haben, wird diese Aufgabe zeitaufwendig und ermüdend. Mit DataSunrise können Sie Ihre Zeit, Ihr Budget und andere Ressourcen sparen, da DataSunrise jetzt verschiedene Techniken zur Leistungssteigerung unterstützt.
AWS S3-Inventar. Es hält alle Metadaten über Ihre S3-Buckets an einem Ort in Form einer archivierten CSV-Datei. Um den Datenverkehrsverbrauch und die Betriebskosten zu senken, kann DataSunrise diese Metadaten mithilfe von S3-Inventar ohne Aufrufe der AWS-API abrufen.
Inkrementelle Datenentdeckung. Mit der inkrementellen Datenentdeckung ist keine wiederholte Entdeckung derselben Objekte und Buckets für das Vorhandensein sensibler Daten erforderlich. Der inkrementelle Scanning-Modus überspringt bereits früher entdeckte Buckets und Objekte. Er scannt nur neue oder aktualisierte Objekte und vergleicht sie mit der zuletzt gescannten Zeit. Es hilft Ihnen, Zeit und Geld zu sparen, während Sie mit großen Datenmengen arbeiten. Außerdem ist das inkrementelle Scannen optional, sodass Sie es jederzeit deaktivieren können, wenn Sie es benötigen.
Parallel Data Discovery. Für die schnelle Suche nach sensiblen Daten in großen Datenmengen können Sie Multiprocessing verwenden. Es ermöglicht die Nutzung mehrerer DataSunrise-Server für parallele Datenerkennung. Mit Parallelentdeckung können Sie die CPU- und Speicherauslastung optimieren. Die Verwendung von Multiprocessing vereinfacht die Arbeit der Datenerkennung, wenn Sie eine große Menge an Daten verarbeiten müssen. Außerdem reduziert es die Belastung des Servers und beeinträchtigt nicht die parallelen Prozesse, die Sie haben. Mit Multiprocessing können Sie mehrere Suchattribute auswählen und bestimmte Objekte von der Suche ausschließen.
Zufällige Datenentdeckung. Diese Funktion ermöglicht das Scannen zufälliger Dateien in S3-Buckets, um den Data Discovery-Prozess zu beschleunigen. Es ist möglich, den Prozentsatz der zu entdeckenden sensiblen Daten über große Datenmengen hinweg zu wählen.
Teilen großer Dateien in Stücke. Große Objekte verbrauchen zusätzlichen Speicherplatz, was in- Memory-Berechnungen erforderlich macht. Jetzt können wir jedes Objekt in Stücke teilen, um die Leistung zu steigern und die Speichernutzung zu optimieren. Mit zusätzlichen Parametern wie “DataDiscoveryChunkSize” und anderen können wir diese Teile leicht entdecken und alle sensiblen Informationen finden.
Einstellungen und Anpassungen der sensiblen Datenerkennung
Sie können den Entdeckungsprozess durch Anpassung einiger zusätzlicher Parameter feinabstimmen.
DataSunrise verfügt über 25 anpassbare Parameter. Zum Beispiel:
- “DataDiscoveryMatchesSaveStrategy” ermöglicht das Speichern von Data Discovery-Vorkommen im Wörterbuch je nach Ihren speziellen Bedürfnissen: erste Übereinstimmungen, alle Übereinstimmungen oder eindeutige Übereinstimmungen speichern;
- “DataDiscoveryChunkSize” ermöglicht das teilweise Herunterladen der Dateien für Data Discovery, um ein Überlaufen des Speichers zu vermeiden. Sie können die Chunk-Größe und das Chunk-Summierungslimit festlegen;
- “DataDiscoveryMaxFileSizeForChunkProcessing” ist für die gesamte Dateigröße, die als Summe der Chunks gescannt werden soll. Die Chunk-Verarbeitung scannt so lange, bis der Wert dieses Parameters erreicht ist;
- “DataDiscoveryS3FilePartToRead” ist für die maximale Dateigröße (MB) für die S3 Data Discovery. Dieser Parameter arbeitet in Verbindung mit DataDiscoveryFilesThreadPools. Es definiert die Anzahl der für die Datei verarbeiteten Threads. Jeder Thread verarbeitet jeweils eine Datei. Daher hängt dieser Parameterwert von den verfügbaren Systemressourcen ab;
- “DataDiscoveryBatchSplitFactor” gibt an, in wie viele Teile das fehlgeschlagene Batch für die erneute Ausführung der Data Discovery-Aufgabe aufgeteilt wird.
Berichterstattung zur Erkennung sensibler Daten
DataSunrise bietet einen mehrschichtigen Schutz für AWS S3. Infolgedessen arbeitet DataSunrise mit einer großen Menge an Daten. Es ermöglicht Ihnen, alle detailliertesten Informationen über Ihre Datenbanken und die darin enthaltenen Daten zu erhalten, indem Sie benutzerdefinierte Berichte im CSV- oder PDF-Format erstellen.
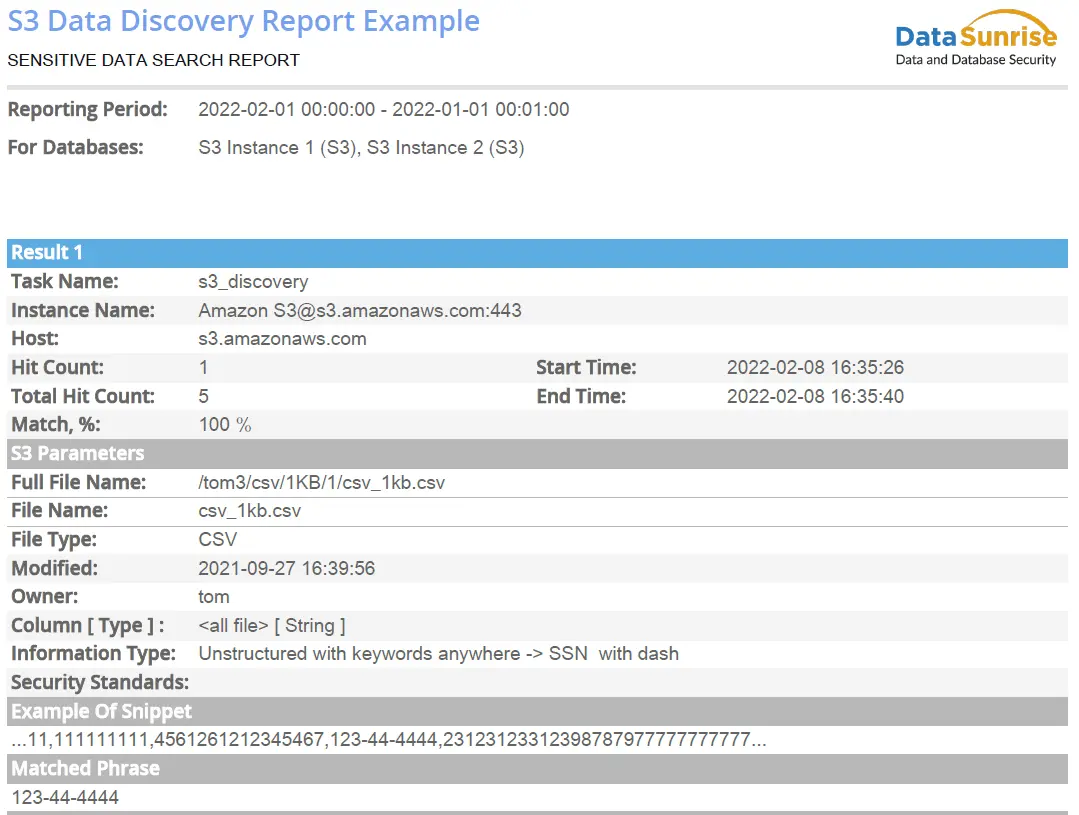
Bild 1: Beispiel für einen PDF-Bericht zur Erkennung sensibler Daten
Verfügbarkeit von Berichten. Die Berichtserstellung ist nun während des Entdeckungsaufgabenprozesses möglich, sodass Sie nicht warten müssen, bis die Aufgabe abgeschlossen ist. Es ermöglicht Ihnen, Zwischenergebnisse anzuzeigen und für Analysen zu nutzen.
Verwendung von Berichten. Durch die Ergebnisse der Berichte können Sie Analysen sammeln und Statistiken zur Datenverarbeitungsgeschwindigkeit und zu Attributen erhalten und die erhaltenen Daten für spezifische Zwecke verwenden, einschließlich des Trainings Ihrer eigenen KI.
Mit einem flexiblen System anpassbarer Berichte müssen Sie Informationen über die Schutzniveaus Ihrer Datenbanken nicht mehr manuell überwachen.
Fazit
Die Erkennung sensibler Daten ermöglicht es Ihnen zu wissen, wo sich sensible Daten in Ihren AWS S3-Buckets befinden, und entsprechende Datenschutz-Maßnahmen zu ergreifen.
DataSunrise bietet eine große Auswahl an Formaten und Methoden zur Erkennung sensibler Daten in AWS S3, unabhängig davon, wo sie sich befinden. Mit der verbesserten Leistung wird die Datenerkennung weniger zeitaufwendig. Sie können DataSunrise Sensitive Data Discovery feinabstimmen, um unnötige Wiederholungssuchen bei großen Datenmengen zu vermeiden. Anpassbare Suchmuster ermöglichen es Ihnen, nach jedem spezifischen Datensatz zu suchen. Mit Berichten können Sie die detailliertesten Informationen erhalten, die es Ihnen ermöglichen, Zwischenergebnisse für Analysen, KI- Lernen und andere Geschäftsprozesse zu sehen.
Um mit DataSunrise bei Amazon loszulegen, besuchen Sie DataSunrise im AWS Marketplace.
