
Data-Masking für Apache Impala

| id | masked_ssn | name |
|---|---|---|
| 1 | XXX-9012 | Charlie |
| 2 | XXX-1098 | Diana |
Views bieten eine einfache Möglichkeit, sensible Informationen zu verbergen, während die Daten für Analysen lesbar bleiben.
2. Data-Masking für Apache Impala über ETL-Jobs
Für Organisationen, die vormaskierte Daten vor der Speicherung benötigen, können ETL (Extract, Transform, Load)-Jobs sensible Daten vor der Einfügung in Tabellen verarbeiten und maskieren.
Hier ist die Ausgabe bei der Ausführung der INSERT INTO-Anweisung in der users-Tabelle basierend auf den Daten aus der raw_users-Tabelle:
Eingabedaten aus der raw_users-Tabelle:
| id | ssn | name |
|---|---|---|
| 1 | 123-45-9012 | Charlie |
| 2 | 987-65-1098 | Diana |
Ausgabedaten in der users-Tabelle:
| id | masked_ssn | name |
|---|---|---|
| 1 | XXX-9012 | Charlie |
| 2 | XXX-1098 | Diana |
Die ssn-Werte wurden maskiert, sodass nur die letzten vier Ziffern angezeigt werden, vorangestellt mit XXX-.
Während dieser Ansatz die Sicherheit erhöht, verringert er auch die Flexibilität, sodass es schwieriger wird, die ursprünglichen Daten ohne einen separaten unmaskierten Datensatz wiederherzustellen.
3. Masking mit benutzerdefinierten Funktionen (UDFs)
Impala verfügt nicht über integrierte Maskierungs-UDFs wie Hive. Basierend auf der Dokumentation unterstützt Impala das Schreiben benutzerdefinierter UDFs in C++ und Java zur Datenumwandlung, umfasst jedoch keine vorgefertigten Maskierungsfunktionen. Sie müssten eigene UDFs schreiben, um die Maskierungsfunktionalität zu implementieren, ähnlich wie Hive seine integrierten Maskierungsfunktionen bereitstellt.
Wenn Sie Maskierungsfähigkeiten benötigen, könnten Sie:
- Benutzerdefinierte C++-UDFs schreiben, um die benötigte Maskierungslogik zu implementieren
- Vorhandene Hive-Java-UDFs zur Maskierung verwenden, indem Sie diese in Impala importieren
- Die Maskierung auf der Anwendungsebene handhaben, bevor Daten in Impala geladen werden
Angenommen, Sie haben eine benutzerdefinierte UDF in Impala mit C++ oder Java geschrieben, um die Sozialversicherungsnummern (SSNs) in der ssn-Spalte zu maskieren. Wir nennen diese benutzerdefinierte UDF zur Einfachheit mask_ssn.
Hier ist ein Beispiel, wie Sie diese UDF abfragen und die erwartete Ausgabe:
Beispielabfrage mit benutzerdefinierter UDF:
SELECT id, mask_ssn(ssn) AS masked_ssn, name
FROM users;
Erwartete Ausgabe:
| id | masked_ssn | name |
|---|---|---|
| 1 | XXX-9012 | Charlie |
| 2 | XXX-1098 | Diana |
Erklärung:
- Die
mask_ssn-UDF würde die SSNs transformieren, indem die ersten fünf Zeichen durchXXX-ersetzt werden und die letzten vier Ziffern sichtbar bleiben. - Das erwartete Ergebnis ist ähnlich dem Effekt der Verwendung von
CONCAT('XXX-', RIGHT(ssn, 4)), aber mit einer benutzerdefinierten UDF haben Sie mehr Flexibilität, wenn Sie komplexere Maskierungslogiken umsetzen möchten.
Fortgeschrittenes Data-Masking für Impala mit DataSunrise
DataSunrise bietet dynamisches und statisches Masking, ohne die originalen Daten zu verändern. Es gewährleistet:
- Rollenbasiertes Data-Masking.
- Nathlose Integration mit Impala.
- Minimale Auswirkungen auf die Leistung.
Schritte zur Implementierung:
- Verbinden Sie Ihre Impala-Instanz mit DataSunrise.
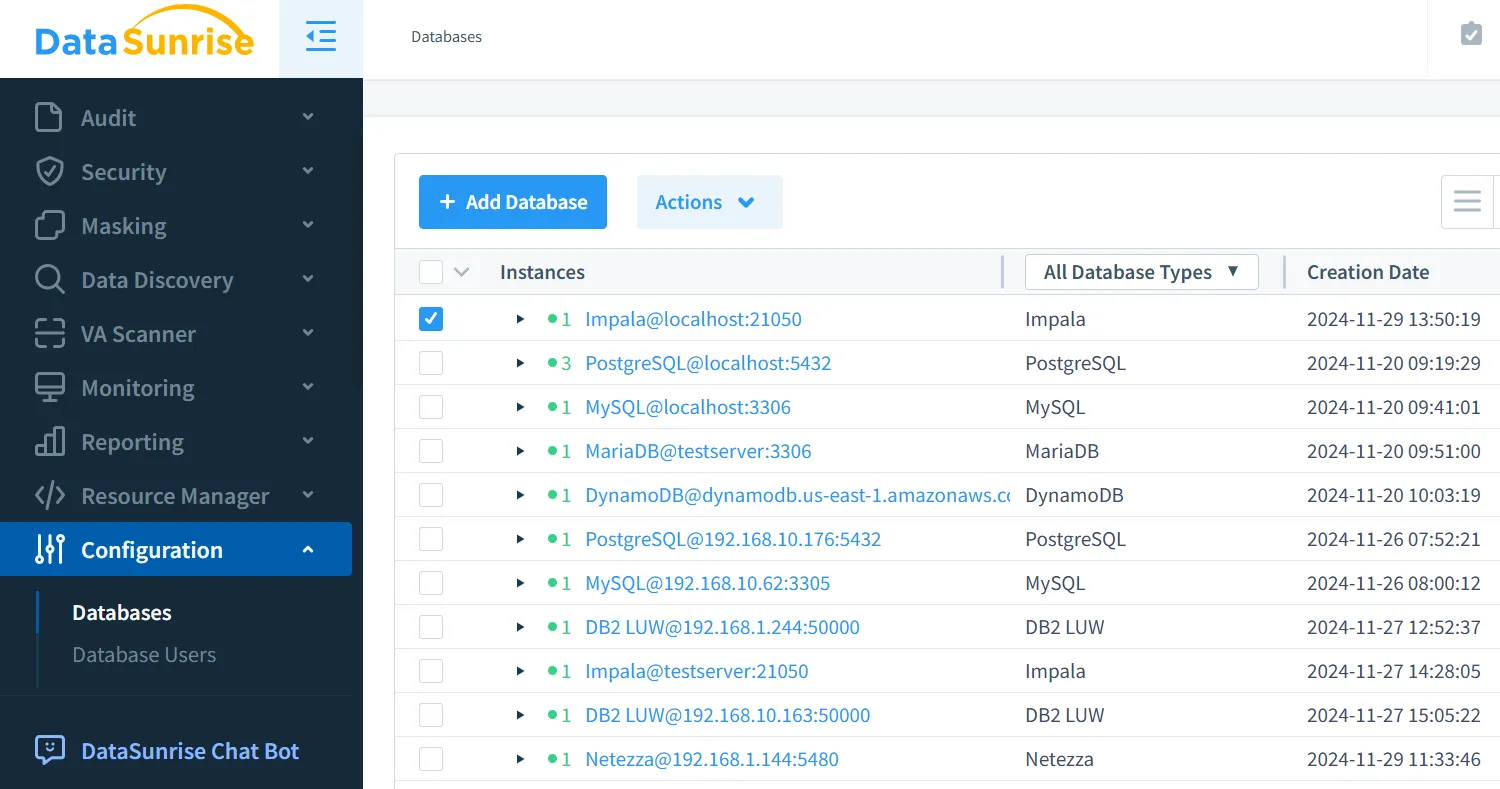
- Definieren Sie Maskierungsregeln über die DataSunrise-Schnittstelle.
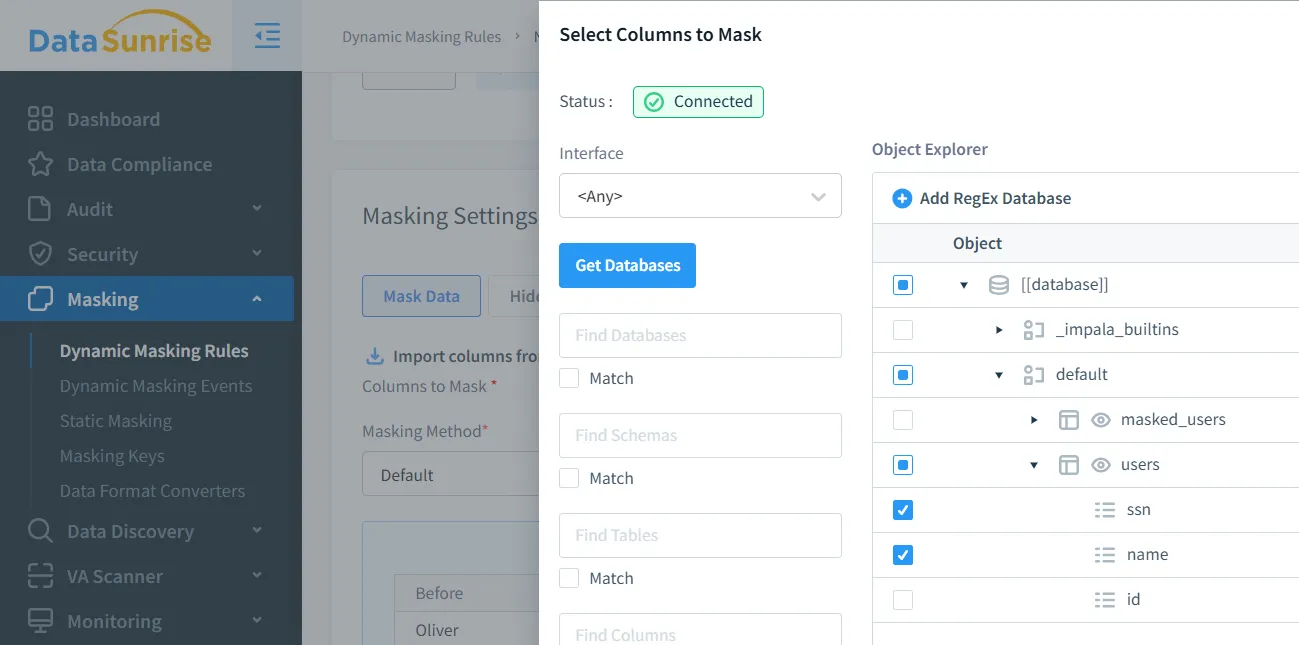
- Validieren Sie die Datenmaskierung durch die Ausführung von Testabfragen.

Fazit
Data-Masking ist entscheidend zum Schutz sensibler Daten in Impala und zur Einhaltung von Vorschriften. Während Views und UDFs grundlegende Lösungen bieten, bietet ETL-Masking einen dauerhafteren Ansatz. DataSunrise erhöht die Sicherheit weiter durch flexible, skalierbare und minimal beeinflussende Data-Masking-Lösungen.
Planen Sie eine DataSunrise-Demo, um fortschrittliche Datensicherheitslösungen für Ihre Impala-Umgebung zu erkunden.
