Tools und Techniken zur Datenmaskierung für Vertica
Tools und Techniken zur Datenmaskierung für Vertica spielen eine zentrale Rolle beim Schutz sensibler Informationen in modernen Analyseumgebungen. Vertica wird häufig für Analysen mit hohem Datenvolumen, Reporting, Data Science und Machine-Learning-Anwendungen eingesetzt. Diese Anwendungsfälle erfordern flexiblen und oft weitreichenden Datenzugriff, wodurch die Wahrscheinlichkeit steigt, dass vertrauliche Werte – wie persönliche Identifikatoren, finanzielle Merkmale oder Gesundheitsinformationen – in Abfrageergebnissen erscheinen.
Im Gegensatz zu transaktionalen Datenbanken legen Vertica-Umgebungen den Fokus auf Leistung und analytischen Durchsatz. Folglich werden Daten häufig denormalisiert, über Projektionen repliziert und gleichzeitig von vielen Werkzeugen genutzt. In diesem Kontext muss die Maskierung sowohl effizient als auch konsistent sein, um sicherzustellen, dass sensible Werte geschützt werden, ohne die Analysen zu beeinträchtigen.
Dieser Artikel untersucht praktische Methoden zur Datenmaskierung für Vertica und die Tools, die Organisationen einsetzen, um diese effektiv umzusetzen, einschließlich zentralisierter Ansätze, die mit DataSunrise Daten-Compliance und modernen Datenschutzanforderungen übereinstimmen.
Warum Datenmaskierung in Vertica-Umgebungen entscheidend ist
Die Architektur von Vertica bringt einzigartige Herausforderungen beim Datenschutz mit sich. Die spaltenorientierte Speicherung, ROS/WOS-Speicherebenen und eine projektionsbasierte Optimierung ermöglichen es Vertica, große Datensätze schnell zu verarbeiten. Gleichzeitig erschweren diese Merkmale jedoch den Einsatz traditioneller Schutzmethoden.
Zu den häufigen Herausforderungen gehören:
- Breite analytische Tabellen, die Metriken mit sensiblen Attributen vermischen.
- Mehrere Projektionen, die dieselben Spalten in unterschiedlichen Layouts speichern.
- Geteilte Cluster, auf die BI-Tools, ETL-Jobs, Notebooks und ML-Pipelines zugreifen.
- Ad-hoc-SQL-Abfragen, die kuratierte Reporting-Views umgehen.
Die natives rollenbasierte Zugriffskontrolle von Vertica begrenzt, wer Objekte abfragen darf, steuert aber nicht, welche Spaltenwerte in den Ergebnissen erscheinen. Sobald eine Abfrage ausgeführt wird, liefert Vertica alle ausgewählten Daten im Klartext zurück. Um diese Lücke zu schließen, wenden Organisationen Maskierungstechniken zur Abfragezeit an, häufig kombiniert mit fortschrittlichen Zugriffskontrollen.
Für weiterführende Informationen zum Ausführungsmodell von Vertica siehe die offizielle Vertica-Architektur-Dokumentation.
Gängige Techniken zur Datenmaskierung für Vertica
In Vertica-Umgebungen kommen verschiedene Maskierungsmethoden zum Einsatz. Jede Methode bietet unterschiedliche Kompromisse zwischen Sicherheit, Flexibilität und Wartungsaufwand.
- Statische Maskierung: Erstellt maskierte Kopien von Tabellen für Nicht-Produktionszwecke. Während sie sich für Entwicklung und Tests eignet, führt statische Maskierung zu Daten-Duplikationen und laufendem Wartungsaufwand, der häufig mit Tools für statische Datenmaskierung adressiert wird.
- View-basierte Maskierung: Nutzt SQL-Views, um sensible Spalten zu verbergen oder zu transformieren. Diese Methode ist anfällig, da Benutzer Views durch direkten Tabellenzugriff umgehen können.
- Maskierung auf Anwendungsebene: Wendet Maskierungslogik in BI-Tools oder Anwendungen an. Dieser Ansatz ist inkonsistent und schützt nicht alle Zugriffswege.
- Dynamische Datenmaskierung: Maskiert Werte zur Abfragezeit basierend auf Richtlinien, ohne gespeicherte Daten zu verändern.
Unter diesen Techniken bietet die dynamische Datenmaskierung das beste Gleichgewicht für Vertica-Analysen. Sie schützt sensible Werte in Echtzeit und bewahrt gleichzeitig analytische Genauigkeit und Leistung – besonders in Verbindung mit Dynamischen Datenmaskierungs-Engines.
Datenmaskierungstools für Vertica
Effektive Maskierung in Vertica erfordert Werkzeuge, die sowohl SQL-Semantik als auch Spaltensensitivität verstehen. Viele Organisationen setzen dabei DataSunrise ein, das eine zentrale Maskierungsschicht vor Vertica bietet und sich eng in Datenbank-Aktivitätsüberwachung integriert.
DataSunrise vereint mehrere Funktionen in einer einzigen Plattform:
- Sensitive Datenerkennung zur Identifikation von PII, PHI und Finanzdaten.
- Dynamische Datenmaskierung zum Schutz von Werten bei Abfrageausführung.
- Datenbank-Aktivitätsüberwachung zur Nachverfolgung von Zugriffen und Verhalten.
- Audit-Protokolle zur Unterstützung der Compliance-Berichterstattung.
Diese Kombination ermöglicht Organisationen, Maskierung konsistent über alle Vertica-Zugriffswege anzuwenden und zugleich Compliance-Manager-Workflows zu unterstützen.
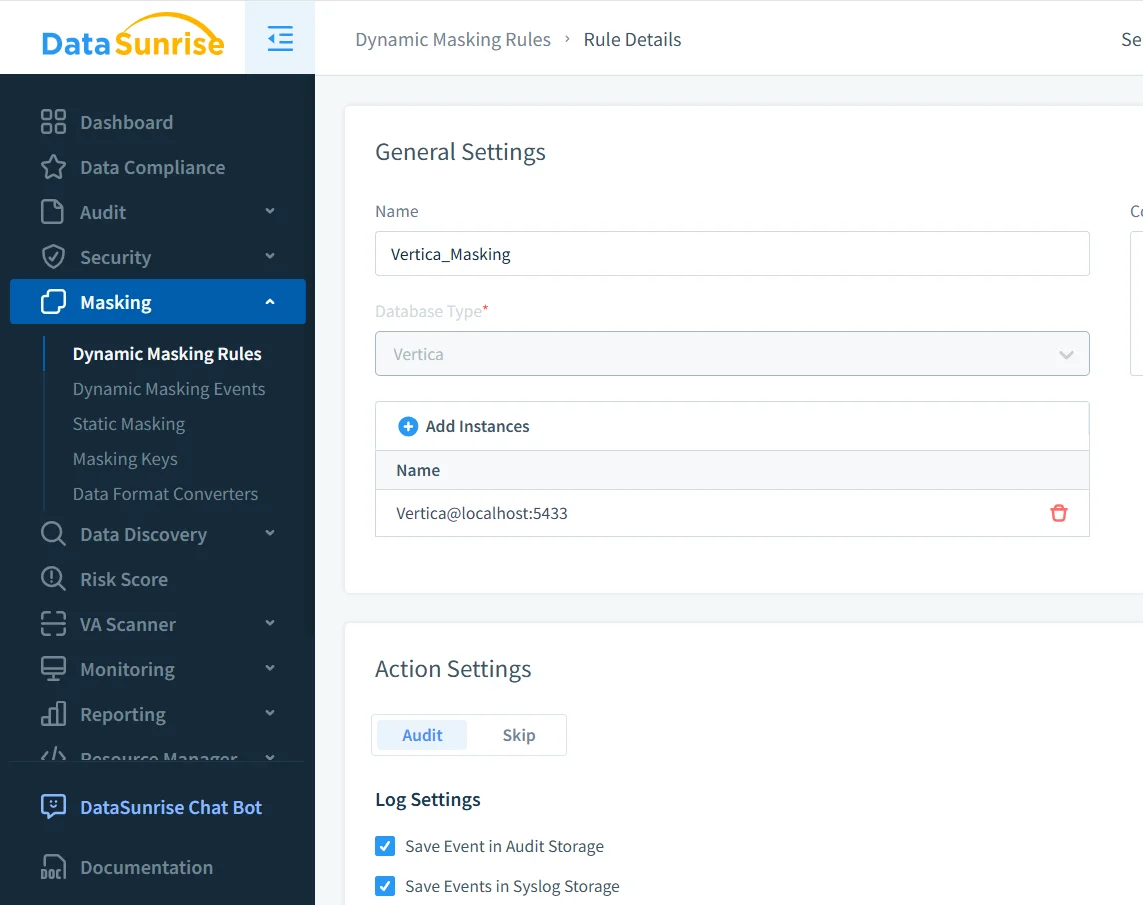
Konfiguration einer Maskierungsregel für Vertica
Dynamische Maskierungsregeln definieren, wie und wann sensible Daten geschützt werden. Eine typische Regel spezifiziert die Vertica-Instanz, Ziel-Schemas oder Tabellen sowie die Spalten, die maskiert werden müssen.
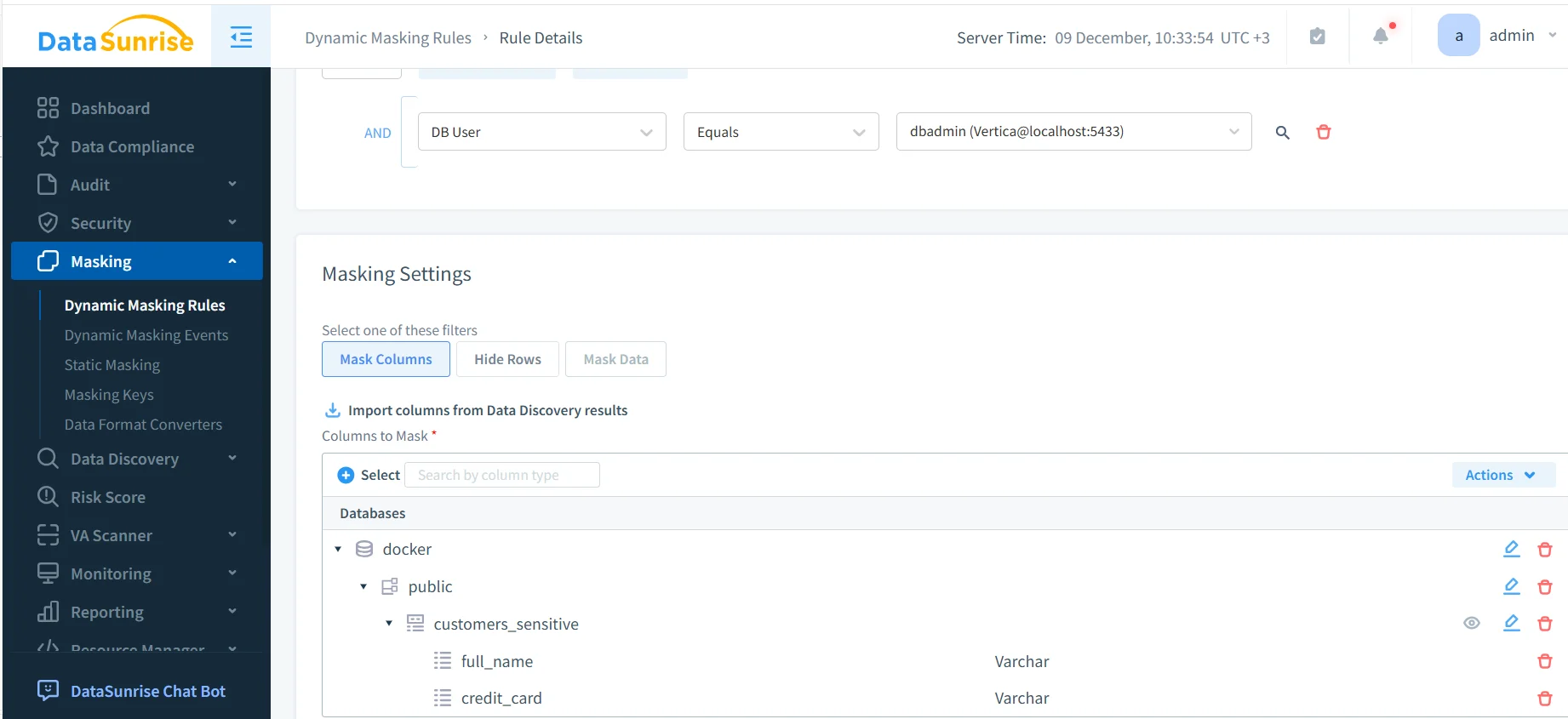
Konfiguration einer dynamischen Maskierungsregel für Vertica.
Ist die Regel aktiviert, wird sie automatisch auf jede passende Abfrage angewandt. Administratoren können zudem Bedingungen basierend auf Datenbankbenutzern, Anwendungen oder Umgebungen definieren und Ereignisse mittels Audit-Trail-Funktionalitäten korrelieren.
Maskierte Abfrageergebnisse in analytischen Workflows
Aus Sicht des Endbenutzers ändert die dynamische Maskierung nichts an der Art, wie Abfragen formuliert werden. Analysten schreiben weiterhin Standard-SQL, und Vertica führt Abfragen normal aus. Der Unterschied zeigt sich nur in den zurückgegebenen Werten.
Maskierte Abfrageergebnisse, die an den Client zurückgegeben werden.
Mit aktivierter Maskierung sehen nicht privilegierte Benutzer anonymisierte oder teilweise verdeckte Werte, während Aggregationen, Joins und Filter weiterhin korrekt funktionieren. Das macht die dynamische Maskierung geeignet für BI-Dashboards, explorative Analysen und ML-Feature-Engineering, die durch Daten-Governance-Richtlinien gesteuert werden.
Dieser Ansatz unterstützt Datenschutz- und Datenminimierungsanforderungen gemäß Vorschriften wie DSGVO, HIPAA und PCI DSS.
Vergleich der Maskierungstechniken für Vertica
| Technik | Beschreibung | Betriebliche Auswirkungen |
|---|---|---|
| Statische Maskierung | Erstellt dauerhaft maskierte Kopien von Daten | Hoher Wartungsaufwand, Daten-Duplikation |
| View-basierte Maskierung | Verwendet SQL-Views, um sensible Spalten zu verbergen | Leicht durch direkte Abfragen zu umgehen |
| Maskierung auf Anwendungsebene | Maskierungslogik innerhalb von BI oder Apps | Inkonsistente Abdeckung |
| Dynamische Maskierung | Maskiert Werte während der Abfrageausführung | Zentrale, skalierbare Schutzlösung |
Best Practices für die Datenmaskierung in Vertica
- Beginnen Sie mit der Identifikation sensibler Spalten.
- Wenden Sie Maskierung auf Abfrageebene an, anstatt Daten zu kopieren.
- Testen Sie Maskierung mit echten analytischen Workloads.
- Überprüfen Sie regelmäßig Audit-Protokolle, um unerwartete Zugriffe zu erkennen.
- Richten Sie Maskierungsrichtlinien an umfassenden Datensicherheitsstrategien aus.
Fazit
Tools und Techniken zur Datenmaskierung für Vertica ermöglichen es Organisationen, sensible Informationen zu schützen und gleichzeitig die Flexibilität und Leistung analytischer Workloads zu bewahren. Durch die Kombination dynamischer Maskierung mit zentralisierter Richtliniendurchsetzung und Auditing vermeiden Teams fragile Workarounds und erzielen konsistenten Schutz über alle Zugriffswege hinweg.
Mit den richtigen Maskierungstools bleibt Vertica eine leistungsstarke Analyseplattform, während sensible Daten in BI-, ETL- und Machine-Learning-Pipelines geschützt bleiben.
