
Wie man dynamische Datenmaskierung in Amazon Aurora implementiert
Einführung
Da Unternehmen zunehmend auf Cloud-Datenbanken wie Amazon Aurora angewiesen sind, wächst der Bedarf an robusten Sicherheitsmaßnahmen. Ein mächtiges Werkzeug im Arsenal des Datenschutzes ist die dynamische Datenmaskierung. Wussten Sie, dass 68% der Datenverletzungen nicht durch böswillige Handlungen, sondern durch menschliches Fehlverhalten verursacht werden? Diese alarmierende Statistik unterstreicht die Wichtigkeit, starke Datenschutzstrategien zu implementieren, einschließlich dynamischer Datenmaskierung für Amazon Aurora.
Was ist dynamische Datenmaskierung?
Dynamische Datenmaskierung ist eine Sicherheitsfunktion, die sensible Daten in Echtzeit verbirgt, während auf sie zugegriffen wird. Anstatt die Originaldaten zu verändern, wendet sie Masken oder Transformationen “on-the-fly” an, wenn Benutzer die Datenbank abfragen. Dieser Ansatz stellt sicher, dass nur autorisierte Benutzer die vollständigen, unmaskierten Daten sehen, während andere maskierte Versionen erhalten.
Wesentliche Vorteile der dynamischen Datenmaskierung sind:
- Erhöhter Datenschutz
- Reduziertes Risiko von Datenverletzungen
- Vereinfachte Einhaltung von Datenschutzvorgaben
- Flexibilität beim Verwalten des Datenzugriffs
Dynamische Datenmaskierungsfunktionen von Amazon Aurora
Amazon Aurora, eine leistungsstarke relationale Datenbank-Engine, bietet integrierte Funktionen zur dynamischen Datenmaskierung. Diese Möglichkeiten erlauben es, sensible Daten zu schützen, ohne den Anwendungscode zu verändern.
Einrichtung der dynamischen Datenmaskierung in Aurora
Um dynamische Datenmaskierung in Amazon Aurora PostgreSQL zu implementieren, können wir die integrierte Row-Level Security (RLS)-Funktion der Datenbank nutzen. Dieser Ansatz bietet eine leistungsstarke und flexible Methode, den Datenzugriff auf granularer Ebene zu steuern. Lassen Sie uns den Prozess durchgehen, beginnend mit der Erstellung einiger Beispieldaten und anschließend der Implementierung von RLS-Richtlinien, um dynamische Maskierungseffekte zu erzielen.
-- Erstellen der Tabelle employees
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
department VARCHAR(50),
salary NUMERIC(10, 2)
);
-- Einfügen von Beispieldaten
INSERT INTO employees (first_name, last_name, email, department, salary) VALUES
('John', 'Doe', '[email protected]', 'IT', 75000),
('Jane', 'Smith', '[email protected]', 'HR', 65000),
('Bob', 'Johnson', '[email protected]', 'IT', 70000),
('Alice', 'Williams', '[email protected]', 'Finance', 80000),
('Charlie', 'Brown', '[email protected]', 'HR', 60000);
Als nächstes richten wir die notwendigen Benutzer und Rollen ein, um zu demonstrieren, wie unterschiedliche Zugriffslevels die Datenansicht beeinflussen.
-- Erstellen von Rollen CREATE ROLE it_manager; CREATE ROLE hr_manager; CREATE ROLE finance_manager; CREATE ROLE employee; -- Erstellen von Benutzern und Zuweisen von Rollen CREATE USER john_it WITH PASSWORD 'password123'; GRANT it_manager TO john_it; CREATE USER jane_hr WITH PASSWORD 'password123'; GRANT hr_manager TO jane_hr; CREATE USER alice_finance WITH PASSWORD 'password123'; GRANT finance_manager TO alice_finance; CREATE USER bob_employee WITH PASSWORD 'password123'; GRANT employee TO bob_employee; -- Gewähren der notwendigen Berechtigungen GRANT SELECT, INSERT, UPDATE, DELETE ON employees TO it_manager, hr_manager, finance_manager; GRANT SELECT ON employees TO employee; GRANT USAGE, SELECT ON SEQUENCE employees_employee_id_seq TO it_manager, hr_manager, finance_manager;
Nun implementieren wir die Row-Level Security (RLS), um unsere Ziele der dynamischen Datenmaskierung zu erreichen.
-- Aktivieren von RLS auf der Tabelle employees ALTER TABLE employees ENABLE ROW LEVEL SECURITY; -- Erstellen von RLS-Richtlinien CREATE POLICY employee_self_view ON employees FOR SELECT TO employee USING (email = current_user); CREATE POLICY manager_department_view ON employees FOR ALL TO it_manager, hr_manager, finance_manager USING ( CASE WHEN current_user = 'john_it' THEN department = 'IT' WHEN current_user = 'jane_hr' THEN department = 'HR' WHEN current_user = 'alice_finance' THEN department = 'Finance' END ); -- Erstellen einer Ansicht für maskierte Gehaltsinformationen CREATE OR REPLACE VIEW masked_employees AS SELECT employee_id, first_name, last_name, email, department, CASE WHEN pg_has_role(current_user, 'hr_manager', 'member') OR pg_has_role(current_user, 'finance_manager', 'member') THEN salary::text ELSE 'VERTRAULICH' END AS salary FROM employees; -- Zugriff auf die Ansicht gewähren GRANT SELECT ON masked_employees TO it_manager, hr_manager, finance_manager, employee; SELECT * FROM employees;
Der letzte Befehl ist das SELECT. Alle oben stehenden SQL-Anweisungen werden als postgres Benutzer ausgeführt. Und da dies ein Admin ist, kann er alle Daten in der Tabelle employees sehen:
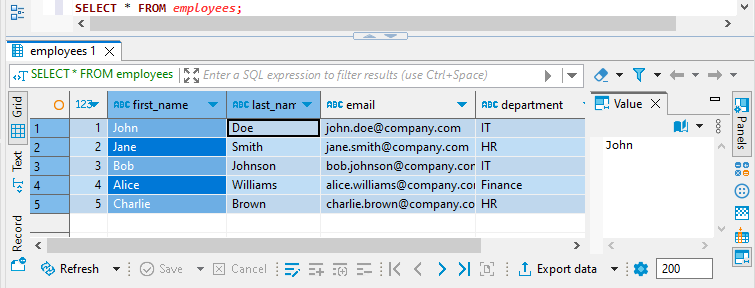
Die Benutzer der HR- und IT-Abteilung können nur die Mitarbeiter ihrer Abteilung sehen:
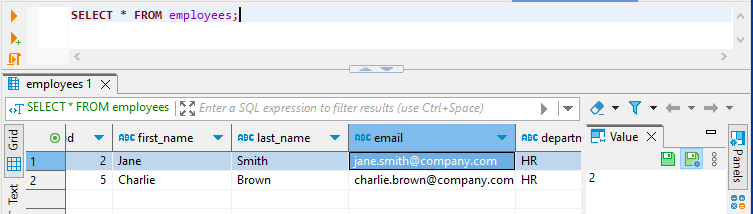
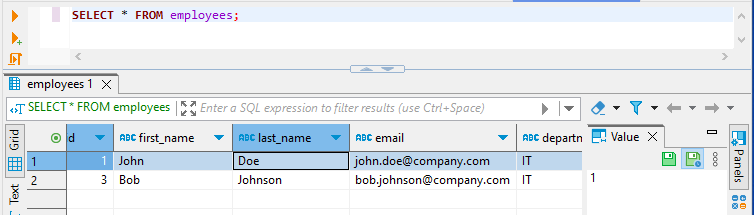
Und schließlich wird das Gehalt in der Ansicht masked_employees für den Benutzer john_it maskiert:
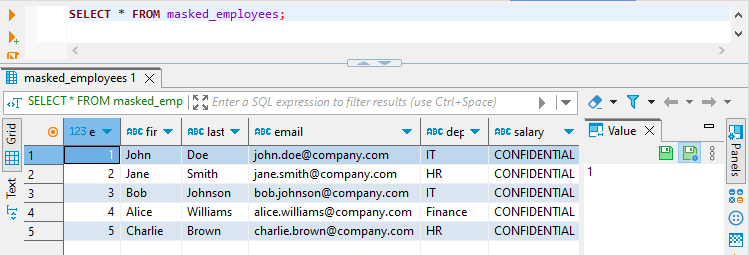
Implementierung der dynamischen Datenmaskierung mit DataSunrise
Obwohl Auroras native Maskierungsfunktionen nützlich sind, bieten Drittanbietertools wie DataSunrise erweiterte Features und eine granulare Steuerung der Datenmaskierung.
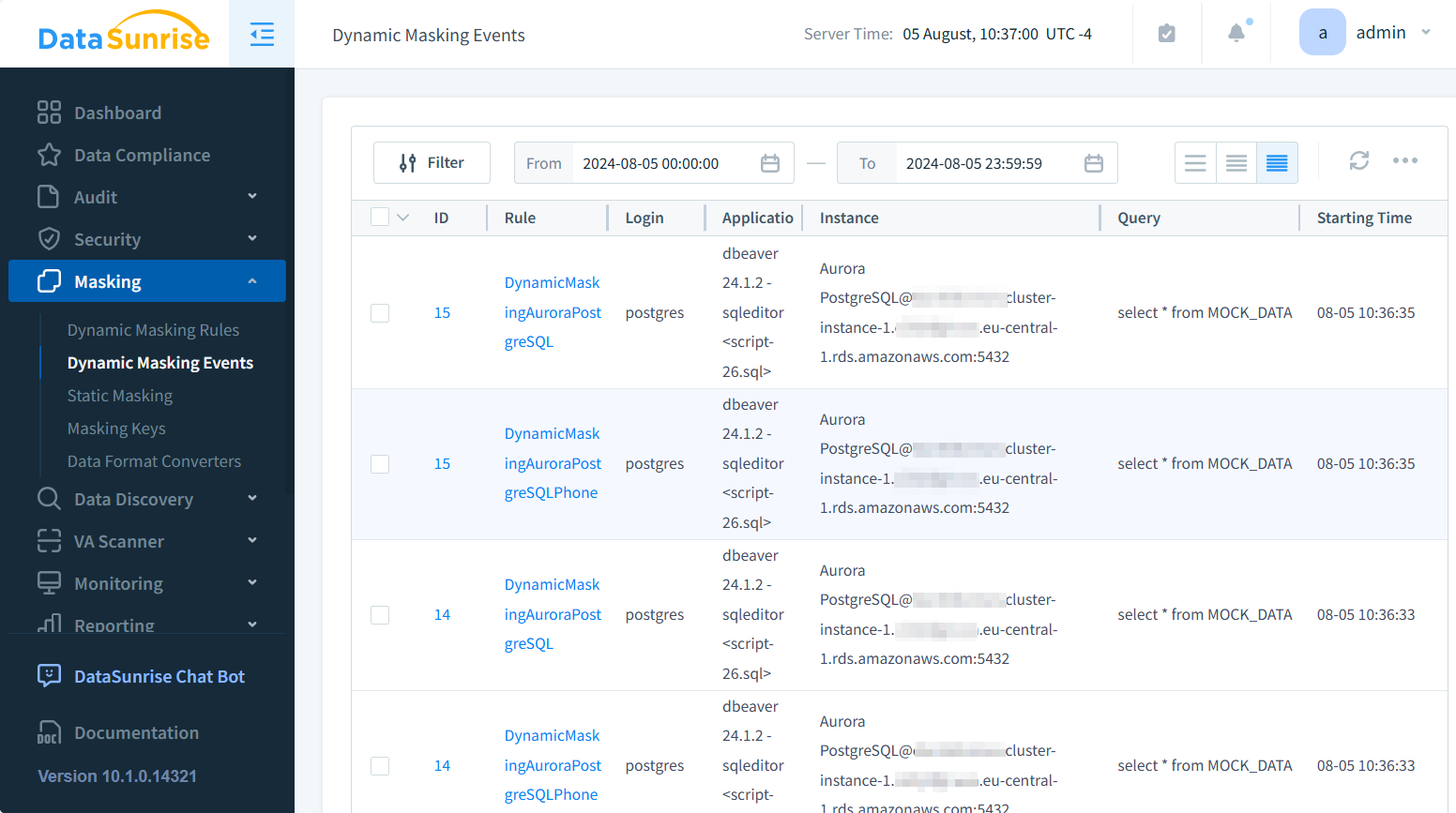
Verfolgung von Maskierungsvorgängen
Um die Effektivität Ihrer Maskierungsregeln zu überwachen, ist es entscheidend, Maskierungsvorgänge zu protokollieren. DataSunrise ermöglicht es, das Logging für Maskierungsvorgänge während der Regelkonfiguration zu aktivieren.
Anschließend können Sie diese Protokolle im DataSunrise-Dashboard einsehen oder für weitere Analysen exportieren.
Best Practices für dynamische Datenmaskierung
Um das volle Potenzial der dynamischen Datenmaskierung für Amazon Aurora auszuschöpfen, sollten Sie diese Best Practices berücksichtigen:
- Sensibele Daten identifizieren: Überprüfen Sie regelmäßig Ihre Datenbank, um sensible Informationen zu identifizieren und zu klassifizieren.
- Geeignete Maskierungsmethoden anwenden: Wählen Sie Maskierungstechniken, die Sicherheit und Benutzerfreundlichkeit in Einklang bringen.
- Gründlich testen: Stellen Sie sicher, dass die Maskierungsregeln die Funktionalität der Anwendung nicht beeinträchtigen.
- Überwachen und anpassen: Überprüfen Sie regelmäßig die Maskierungsprotokolle und passen Sie die Regeln bei Bedarf an.
- Kombinieren mit anderen Sicherheitsmaßnahmen: Verwenden Sie Datenmaskierung zusammen mit Verschlüsselung, Zugriffskontrollen und Auditing.
Datengetriebene Anwendungstests: Maskierte versus synthetische Daten
Bei Tests datengetriebener Anwendungen stehen zwei Hauptansätze zur Verfügung:
- Testen mit maskierten Daten
- Testen mit synthetischen Daten
Testen mit maskierten Daten
Dieser Ansatz verwendet Ihre tatsächlichen Produktionsdaten, wendet jedoch Maskierungsregeln an, um sensible Informationen zu schützen. Vorteile sind:
- Realistische Datenszenarien
- Einfachere Einrichtung
- Erhalt der Datenbeziehungen
Allerdings besteht immer noch ein geringes Risiko der Datenoffenlegung, und maskierte Daten decken möglicherweise nicht alle möglichen Testfälle ab.
Testen mit synthetischen Daten
Diese Methode verwendet künstlich generierte Daten, die die Struktur und Eigenschaften Ihrer Produktionsdaten nachahmen. Vorteile sind:
- Kein Risiko der Offenlegung realer Daten
- Möglichkeit, Randfälle für gründliche Tests zu generieren
- Vermeidung von Datenschutzkonformitätsproblemen
Der Nachteil ist, dass die Erstellung realistischer synthetischer Daten herausfordernd und zeitaufwendig sein kann.
Fazit
Die dynamische Datenmaskierung für Amazon Aurora ist ein leistungsstarkes Werkzeug zum Schutz sensibler Daten in Cloud-Umgebungen. Durch die Implementierung von Maskierungsstrategien können Unternehmen das Risiko von Datenverletzungen erheblich reduzieren und die Einhaltung von Datenschutzvorschriften vereinfachen. Unabhängig davon, ob Sie Auroras nativen Funktionen oder fortschrittlichen Tools wie DataSunrise nutzen, sollte die dynamische Datenmaskierung ein wesentlicher Bestandteil Ihrer Datenbanksicherheitsstrategie sein.
Denken Sie daran, dass effektiver Datenschutz ein fortlaufender Prozess ist. Überprüfen und aktualisieren Sie regelmäßig Ihre Maskierungsregeln, überwachen Sie Maskierungsvorgänge und informieren Sie sich über die neuesten Best-Practice-Empfehlungen, um Ihre sensiblen Daten in der sich ständig verändernden digitalen Landschaft zu schützen.
DataSunrise bietet benutzerfreundliche und innovative Tools für die Datenbanksicherheit, einschließlich umfassender Audit-Funktionalitäten und Datenentdeckungsfunktionen. Um mehr darüber zu erfahren, wie DataSunrise Ihre Datenbanksicherheit verbessern kann und um unsere Lösungen in Aktion zu sehen, besuchen Sie unsere Website, um eine Online-Demo zu vereinbaren.
Nächste
