Adversielles Maschinelles Lernen
Während künstliche Intelligenz in geschäftskritische Arbeitsabläufe integriert wird, nutzen etwa 91 % der US-Banken nun KI zur Betrugserkennung, so Elastic Insights (2025).
Obwohl die meisten Organisationen massiv in Datenbanksicherheit und Infrastrukturkontrollen investieren, enthüllt adversarisches maschinelles Lernen (AML) eine neue, subtilere Bedrohung – eine, die nicht die umliegenden Systeme, sondern die Algorithmen selbst ins Visier nimmt.
Dieser Artikel untersucht, wie adversarische Angriffe funktionieren, warum sie für KI-Pipelines so gefährlich sind und wie Technologien wie der dateninspirierte Sicherheitsansatz von DataSunrise die Modellintegrität von der Schulung bis zur Bereitstellung stärken können.
Verständnis von adversarischem maschinellem Lernen
Adversarisches maschinelles Lernen konzentriert sich darauf, absichtlich Eingaben zu erstellen, die dazu führen, dass KI-Modelle Fehler machen – von der falschen Klassifizierung von Bildern bis hin zur Generierung falscher Vorhersagen. Im Kern ist es die Wissenschaft, die Intelligenz eines Modells in eine Schwäche zu verwandeln.
Anders als klassische Cybersecurity-Bedrohungen, die Softwarefehler ausnutzen, zielen adversarische Angriffe auf das statistische Herz des maschinellen Lernens ab. Ein paar veränderte Bytes in der Eingabe können den Ausgabe des Modells manipulieren, ohne dass für Menschen eine sichtbare Veränderung erkennbar ist. Deshalb erfordert der Schutz von KI-Systemen eine Fusion aus Echtzeitüberwachung, Anomalieerkennung und Rückverfolgbarkeit der Datenherkunft über alle Lernphasen hinweg.
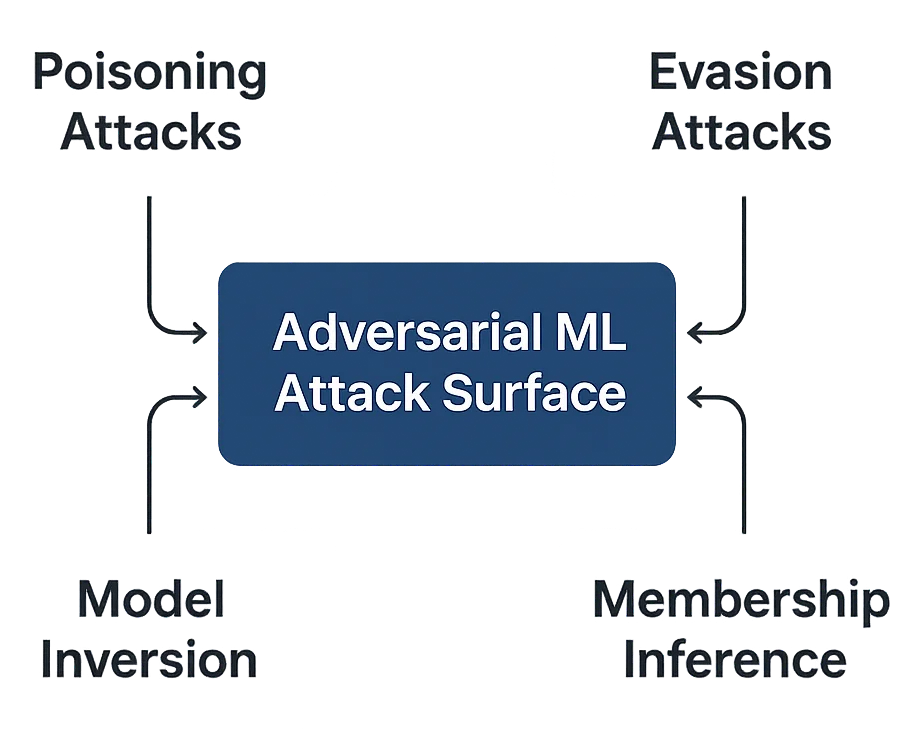
Die wesentlichen adversarischen Bedrohungen
Adversarisches ML kann je nach Zeitpunkt und Art des Eingreifens von Angreifern in verschiedenen Formen auftreten:
- Vergiftungsangriffe – Verunreinigung von Trainingsdatensätzen mit bösartigen Beispielen. Selbst eine geringe Datenverschmutzung kann Modelle verzerren und compliance-relevante Vorhersagen sabotieren.
- Umgehungsangriffe – Gestaltung von Eingaben, die die Modellerkennung umgehen. Häufig anzutreffen in der Gesichtserkennung, bei Spamfiltern und der Betrugserkennung.
- Modellinversion – Rekonstruktion sensitiver Trainingsdaten anhand von Modellausgaben, was die Exposition von personenbezogenen Daten bedroht.
- Mitgliedschafts-Inferenz – Vermutung, ob ein bestimmter Datensatz Teil des Trainingssets war, was die Datenvertraulichkeit untergräbt.
Echtzeit-Erkennung adversarischen Verhaltens
Traditionelle Überwachungstools können eine adversarische Eingabe nicht einfach erkennen. Ein leicht verändertes Pixelarray oder Text-Embedding mag normal erscheinen, kann das Modellverhalten jedoch vollständig entgleisen lassen. Zur Bewältigung dieses Problems setzen Sicherheitsteams auf ML-basierte Detektoren, die Anomalien im Gradientverhalten, in der Merkmalsvarianz oder in der Ausgabeentropie erkennen.
Im Folgenden ein vereinfachtes Beispiel eines solchen Detektors:
import numpy as np
class AdversarialDetector:
"""Erkennt adversarische Störungen anhand der Analyse von Merkmalsabweichungen."""
def __init__(self, baseline_vector: np.ndarray, threshold: float = 0.15):
self.baseline = baseline_vector
self.threshold = threshold
def detect(self, input_vector: np.ndarray) -> dict:
delta = np.linalg.norm(input_vector - self.baseline) / len(input_vector)
is_adversarial = delta > self.threshold
return {
"threat_detected": is_adversarial,
"risk_score": float(delta * 100),
"severity": "HIGH" if is_adversarial else "LOW",
"recommendations": ["Erneutes Training mit verifizierten Daten"] if is_adversarial else []
}
Diese Routine vergleicht neue Eingaben mit einer Basislinie vertrauenswürdiger Datendistributionen und liefert sowohl quantitative als auch qualitative Indikatoren für die nachgelagerte Verhaltensanalyse.
Absicherung von Modellen durch defensives Training
Neben der Erkennung müssen Organisationen ihre Modelle gegen zukünftige Manipulationen absichern. Eine effektive Technik ist das adversarische Training – das absichtliche Aussetzen des Modells gegenüber modifizierten Beispielen während des Lernprozesses, damit es lernt, diesen zu widerstehen.
class RobustTrainer:
"""Führt adversarisches Training durch, um die Widerstandsfähigkeit des Modells zu verbessern."""
def __init__(self, model, epsilon: float = 0.1):
self.model = model
self.epsilon = epsilon
def perturb(self, x):
noise = np.random.uniform(-self.epsilon, self.epsilon, x.shape)
return np.clip(x + noise, 0, 1)
def train(self, data, labels):
adv_data = self.perturb(data)
combined = np.vstack((data, adv_data))
combined_labels = np.concatenate((labels, labels))
self.model.fit(combined, combined_labels)
return {"status": "Modell mit adversarischer Robustheit trainiert"}
Best-Practice-Empfehlungen für die Sicherheit im adversarischen ML
Für Organisationen
- Sichern Sie den Datenlebenszyklus – Etablieren Sie eine kontinuierliche Aktivitätsverlauf-Überwachung, um frühe Anomalien zu erkennen.
- Implementieren Sie eine Modell-Governance – Definieren Sie Zuständigkeiten und Richtlinien, die mit Compliance-Rahmenwerken wie GDPR und HIPAA in Einklang stehen.
- Führen Sie umfassende Audits durch – Aktivieren Sie ein einheitliches Audit-Trail, um die Herkunft des Modells und die Integrität des Trainings zu überprüfen.
- Schulen Sie alle Stakeholder – Stellen Sie sicher, dass Datenwissenschaftler die Sicherheitsimplikationen adversarischer Störungen verstehen.
Für technische Teams
- Nutzen Sie erklärbare KI-Tools – Interpretieren Sie Modellausgaben und verfolgen Sie Anomalien über Sicherheits-Dashboards.
- Integrieren Sie kontinuierliche Validierung – Automatisieren Sie Prüfungen in Ihren Pipelines mithilfe von Reverse-Proxy-Kontrollen zur Anfragenfilterung.
- Verwenden Sie rollenbasierte Zugriffssteuerung – Beschränken Sie den Zugang zu Modelltraining und -inferenz mit RBAC.
- Verschlüsseln Sie Datensätze – Nutzen Sie feldbasierte Verschlüsselung, um unbefugte Datenwiederherstellung zu verhindern.
DataSunrise: Umfassender Schutz gegen adversarisches ML
DataSunrise erweitert den Schutz über die Infrastruktur hinaus, indem es Resilienz direkt in den KI-Workflow integriert. Die Plattform bietet Zero-Touch Security Orchestration mit Context-Aware Protection und Autonomous Threat Detection über mehr als 50 unterstützte Plattformen.
Kernfunktionen
- ML-basierte Anomalieerkennung – Korrelierung abnormalen Gradient- und Merkmalverhaltens.
- Rückverfolgbarkeit der Datenherkunft – Stellt sicher, dass jeder Datensatz, der im Modelltraining verwendet wird, nachvollziehbar ist.
- Compliance-Autopilot – Ordnet Modell- und Datenoperationen regulatorischen Kontrollen zu.
- Einheitliches Audit-Framework – Verknüpft Logs, Ereignisse und Benutzeraktivitäten in einem Dashboard.
- Adaptive Maskierungs-Engine – Verbirgt dynamisch risikoreiche Merkmale während der Modellevaluierung.
Diese Module gewährleisten zusammen, dass KI-Compliance standardmäßig erreicht wird – und verhindern sowohl absichtliche als auch unbeabsichtigte adversarische Manipulationen in Unternehmensumgebungen.
Fazit: Vertrauenswürdige KI-Modelle aufbauen
Adversarisches maschinelles Lernen erinnert uns daran, dass intelligente Systeme genauso leicht getäuscht werden können wie Menschen – und dass ihr Schutz gleichermaßen intelligente Abwehrmaßnahmen erfordert.
Durch die Kombination starker Datenkontrollen, erklärbarer Modelle und kontinuierlicher Datenbankfirewall-Durchsetzung können Organisationen Verwundbarkeit in Wachsamkeit umwandeln.
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen