Vertrauliches Computing für KI
Einführung
Während Unternehmen künstliche Intelligenz (KI) in hybriden und Cloud-Umgebungen einsetzen, wird Datenschutz zu einer vorrangigen Sorge.
Das Training moderner Modelle erfordert enorme Mengen sensibler Informationen – von medizinischen Bildern und Finanzdaten bis hin zu Kundeninteraktionen –, die häufig auf gemeinsam genutzter oder mandantenfähiger Infrastruktur verarbeitet werden.
Traditionelle Sicherheitsmaßnahmen schützen Daten im Ruhezustand durch Verschlüsselung und während der Übertragung durch sichere Protokolle wie TLS. Dennoch bleiben Daten während der Nutzung ungeschützt, was Angreifer ausnutzen können.
Vertrauliches Computing schließt diese Lücke. Es sichert Daten, während sie aktiv verarbeitet werden, durch den Einsatz von Trusted Execution Environments (TEEs) – isolierte, hardwaregeschützte Enklaven innerhalb von CPUs. Innerhalb dieser Enklaven bleiben die Daten verschlüsselt und sind selbst für privilegierte Benutzer, Hypervisoren oder den Cloud-Anbieter nicht zugänglich.
Erfahren Sie mehr in Google Clouds Leitfaden zum vertraulichen Computing für KI für architektonische Einblicke.
Die Notwendigkeit von vertraulicher KI
KI-Systeme umfassen mehrere voneinander abhängige Schichten – Erfassung, Vorverarbeitung, Training und Inferenz. Jede Schicht bringt ihre eigene Angriffsfläche mit sich:
- Daten während der Übertragung: Informationen, die zwischen Cloud-Diensten gesendet werden, können abgefangen werden.
- Daten im Ruhezustand: Fehlende oder falsche Verschlüsselung bzw. Zugriffsrichtlinien können zu unautorisiertem Datenzugriff führen.
- Daten während der Nutzung: Sobald Daten im Speicher entschlüsselt sind, können Insider oder kompromittierte Betriebssysteme darauf zugreifen.
Die meisten Unternehmen bewältigen die ersten beiden Zustände bereits mit etablierten Sicherheitswerkzeugen wie Datenbankverschlüsselung und Netzwerkschutz. Jedoch bleiben Daten während der Nutzung angreifbar, da die Verschlüsselung für die Verarbeitung vorübergehend aufgehoben werden muss.
Vertrauliches Computing beseitigt diese Voraussetzung. Es hält die Rechenprozesse verschlüsselt, sodass Rohdaten niemals die sichere Enklave verlassen. Dies macht es unverzichtbar für föderiertes Lernen, grenzüberschreitende Analysen und regulierte Branchen, in denen die Einhaltung von DSGVO, HIPAA und PCI DSS verpflichtend ist.
Wie Vertrauliches Computing funktioniert
Vertrauliches Computing nutzt hardwarebasierte TEEs wie Intel SGX, AMD SEV und ARM TrustZone. Diese Enklaven sind kleine, dedizierte Bereiche des CPU-Speichers, die Integrität, Vertraulichkeit und Attestierung gewährleisten.
Innerhalb eines TEE:
- Daten werden ausschließlich innerhalb der Enklaven-Grenzen entschlüsselt und verarbeitet.
- Die Ausführung von Code bleibt isoliert vom Betriebssystem, Hypervisor und anderen virtuellen Maschinen.
- Remote Attestation stellt sicher, dass vor der Bereitstellung sensibler Schlüssel ausschließlich autorisierter, unveränderter Code innerhalb der Enklave ausgeführt wird.
Dieses Modell gewährleistet, dass selbst Systemadministratoren, Insider oder kompromittierte Hypervisoren die Arbeitslast nicht überwachen oder verändern können.
Es verwandelt Cloud-KI-Umgebungen in vertrauenswürdige Rechenzonen, ideal für vertrauliche Arbeitslasten wie gemeinsames Modelltraining oder sichere Inferenz auf Benutzerdaten.
KI-Workflows, die durch Vertrauliches Computing abgesichert werden
1. Training sensibler Modelle
Hochrisikodaten, wie genomische oder finanzielle Informationen, können sicher innerhalb von TEEs verarbeitet werden, ohne jemals offengelegt zu werden.
Dies ermöglicht Institutionen, Modelle über Ländergrenzen hinweg kollaborativ zu trainieren, während sensible Aufzeichnungen vertraulich bleiben.
2. Föderiertes Lernen und Datenkooperation
Organisationen können verschlüsselte Daten zu einem gemeinsamen Trainingsprozess beisteuern.
Nur die resultierenden Modellparameter – nicht die Rohdaten – verlassen die Enklave, was eine datenschutzwahrende Zusammenarbeit unter Krankenhäusern, Banken oder Forschungszentren ermöglicht.
3. Sichere Inferenz und Vorhersage
Benutzereingaben (z. B. ein medizinisches Bild oder ein Kreditantrag) können sicher innerhalb der Enklave analysiert werden, wodurch sowohl die Eingabe als auch die Modellgewichte vor externem Zugriff geschützt werden.
4. Regulatorische Konformität
Vertrauliches Computing ermöglicht dauerhafte Einhaltung von Datenschutzvorschriften wie DSGVO, HIPAA und PCI DSS.
Es gewährleistet prüfungsbereite Verarbeitung, ohne Leistung oder Zugänglichkeit zu beeinträchtigen.
Architekturübersicht
Im Folgenden wird eine konzeptionelle Referenzarchitektur aus dem Google Cloud Leitfaden für vertrauliche KI dargestellt.
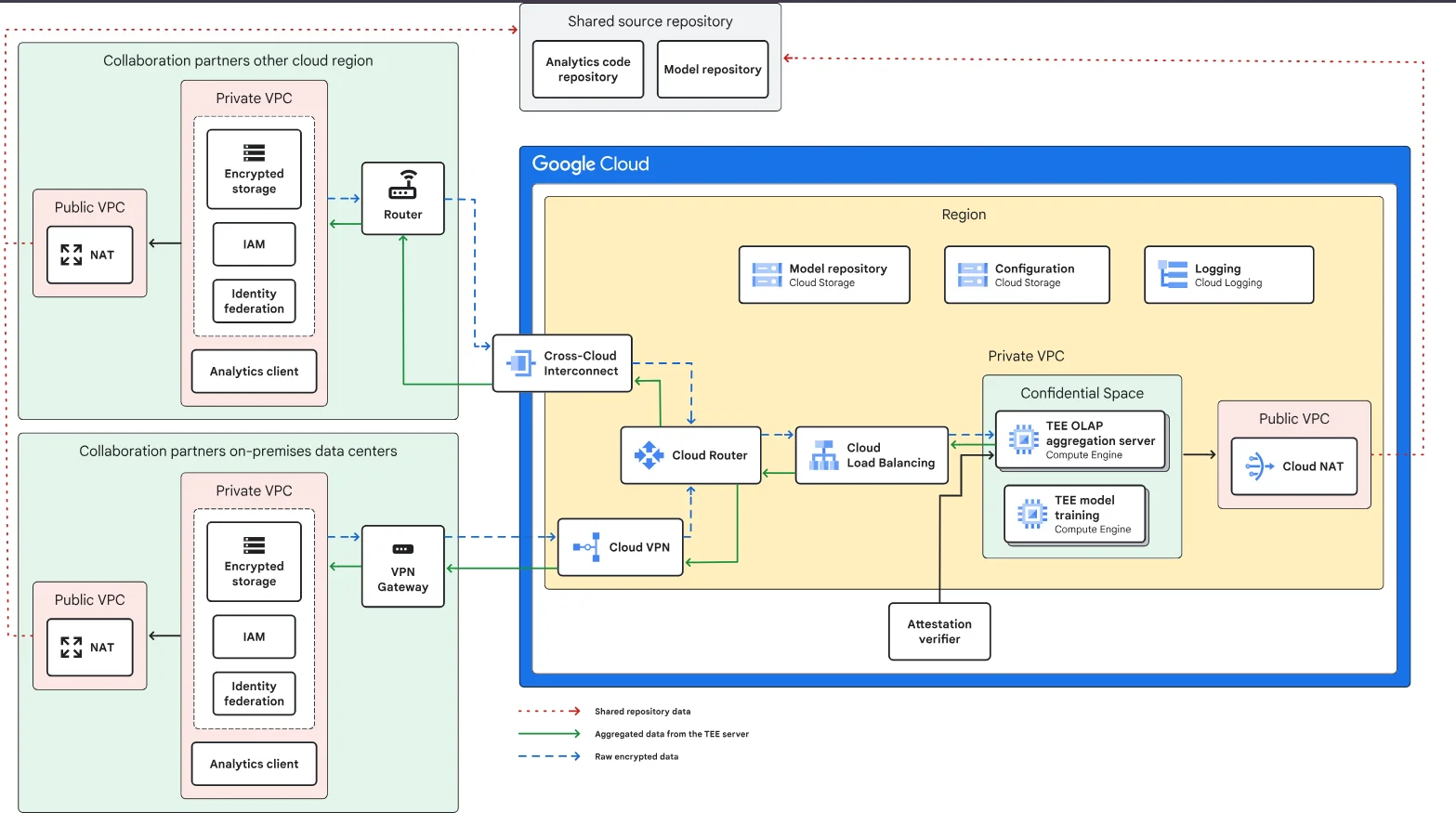
Architekturaufbau
| Komponente | Rolle | Sicherheitsfunktion |
|---|---|---|
| Vertraulicher Bereich (TEE) | Führt sensible Berechnungen durch | Verschlüsselt und isoliert Daten während der Nutzung |
| Verschlüsselter Speicher | Speichert Trainingsdatensätze | Schützt Daten im Ruhezustand mit verwalteten Schlüsseln |
| Cloud Load Balancer & Router | Leitet den Datenverkehr zwischen Enklaven | Sorgt für Netzwerksegmentierung und Verschlüsselung |
| Cross-Cloud Interconnect / VPN | Verbindet Partnerumgebungen | Sorgt für verschlüsselte Kommunikation |
| Attestierungsprüfer | Bestätigt die Integrität der Enklave | Verhindert die Ausführung von nicht verifiziertem Code |
| Protokollierung & Überwachung | Verfolgt Enklavenereignisse | Unterstützt Prüfprotokolle und die Überprüfung der Einhaltung von Vorschriften |
Beispiel: Enklavenbasierte Modellausführung
Im Folgenden ein vereinfachtes Beispiel einer enklavenbasierten Modellausführung mit Remote Attestation vor der Ausführung sensibler Code:
class ConfidentialEnclave:
def __init__(self, enclave_id: str):
self.enclave_id = enclave_id
self.attested = False
def attest(self, signature: str):
"""Überprüfe die Integrität der Enklave mittels Attestation."""
if signature == "valid_signature":
self.attested = True
print("Enklave verifiziert und vertrauenswürdig.")
else:
raise PermissionError("Attestation fehlgeschlagen!")
def run_model(self, data: list):
if not self.attested:
raise PermissionError("Modell kann in einer nicht verifizierten Enklave nicht ausgeführt werden.")
print(f"Verarbeite {len(data)} Datensätze sicher innerhalb der Enklave {self.enclave_id}.")
# Beispielanwendung
enclave = ConfidentialEnclave("TEE-01")
enclave.attest("valid_signature")
enclave.run_model(["record1", "record2"])
In Produktionsumgebungen umfasst der Prozess die sichere Bereitstellung von Schlüsseln und hardwarebasierte Signaturprüfungen, bevor der Zugriff auf verschlüsselte Modellgewichte oder sensible Datensätze gestattet wird.
Betriebliche und Sicherheitstechnische Vorteile
Vertrauliches Computing führt zu messbaren Verbesserungen sowohl in der betrieblichen Effizienz als auch in der Einhaltung von Vorschriften:
- Erweiterte Privatsphäre: Verschlüsselter Speicher verhindert Datenleckagen durch Systemwerkzeuge oder Speicherauszüge.
- Verifizierbares Vertrauen: Hardware-Attestierung liefert einen Nachweis der Enklavenintegrität für externe Prüfer.
- Sichere Zusammenarbeit: Mehrere Organisationen können gemeinsam Daten verarbeiten, ohne proprietäre Details preiszugeben.
- Regelkonforme Ausrichtung: Integrierte Verschlüsselungsmechanismen vereinfachen Prüfungen unter Rahmenwerken wie SOX oder DSGVO.
- Widerstandsfähigkeit gegen Insider-Bedrohungen: Selbst privilegierte Konten können Enklavendaten nicht einsehen oder manipulieren.
Diese Möglichkeiten machen vertrauliches Computing unerlässlich für die sichere Verwaltung des Lebenszyklus von KI-Modellen, von der Datenerfassung bis zur Inferenz.
Integration von vertraulichem Computing in KI-Pipelines
Organisationen können TEEs mit minimaler Umgestaltung in ihre bestehenden ML-Pipelines integrieren. Ein typischer Implementierungsablauf umfasst:
import hashlib
def secure_pipeline_hash(stage: str, payload: bytes) -> str:
"""Erzeuge einen unveränderlichen Hash für jede Phase der KI-Pipeline."""
stage_hash = hashlib.sha256(stage.encode() + payload).hexdigest()
print(f"Phase '{stage}' mit Hash aufgezeichnet: {stage_hash}")
return stage_hash
# Beispiel: Aufzeichnung sicherer Trainingsphasen
secure_pipeline_hash("data_preprocessing", b"normalized_features")
secure_pipeline_hash("model_training", b"weights_v3.4")
secure_pipeline_hash("evaluation", b"accuracy_0.98")
Unveränderliche Hashing-Methoden und Attestierungsprotokolle gewährleisten vollständige Rückverfolgbarkeit für Compliance-Prüfungen und forensische Untersuchungen – in Übereinstimmung mit den Best Practices in der Datenbank-Aktivitätsüberwachung.
Herausforderungen und Überlegungen
Obwohl vertrauliches Computing eine starke Isolation bietet, müssen Organisationen praktische Faktoren berücksichtigen, bevor sie es in großem Maßstab einsetzen:
- Leistungseinbußen: Verschlüsselte Berechnungen können zu leichten Verzögerungen führen, was eine Kapazitätsplanung erfordert.
- Reife des Ökosystems: Die Integration von GPUs, TPUs und Beschleunigern befindet sich noch in der Entwicklung.
- Anwendungskompatibilität: Bestehender Legacy-Code muss möglicherweise umstrukturiert werden, um innerhalb von TEEs zu laufen.
- Schlüsselverwaltung: Die Sicherheit hängt von einem robusten Lebenszyklusmanagement der Verschlüsselungsschlüssel ab.
Die Kombination von vertraulichem Computing mit bestehenden Sicherheitsrichtlinien und kontinuierlichen Schwachstellenbewertungen hilft, diese Herausforderungen effektiv zu bewältigen.
Compliance Mapping
Vertrauliche KI unterstützt direkt mehrere Compliance-Anforderungen, die den Datenschutz während der Verarbeitung regeln.
| Regulierung | Erfordernis der vertraulichen KI | Lösungsansatz |
|---|---|---|
| GDPR | Datenminimierung und Pseudonymisierung während der KI-Verarbeitung | Datensätze in sicheren Enklaven isolieren und verschlüsseln |
| HIPAA | Schutz von Patientendaten während KI-basierter Analysen | Modelltraining und -inferenz innerhalb von TEEs durchführen |
| PCI DSS 4.0 | Verhindern, dass Zahlungsdaten bei der Modelinferenz offengelegt werden | Sensible Datensätze nur in verifizierten Umgebungen verarbeiten |
| SOX | Gewährleisten von Verantwortlichkeit und Prüfungsfähigkeit in der KI-Datenverarbeitung | Pflegen von verifizierbaren Prüfprotokollen für Enklavenoperationen |
| NIST AI RMF | Integrität und Widerstandsfähigkeit vertrauenswürdiger KI-Ausführung | Nutzung von Hardware-Attestierung und Laufzeitverifikation |
Fazit
Der Schutz von KI-Systemen erfordert den Schutz von Daten während des gesamten Lebenszyklus – im Ruhezustand, während der Übertragung und nun auch während der Nutzung.
Vertrauliches Computing vervollständigt dieses Schutzmodell, indem es Daten während der Verarbeitung verschlüsselt und sicherstellt, dass selbst privilegierte Insider oder Cloud-Anbieter keinen Zugriff erhalten.
Organisationen, die diesen Ansatz implementieren, können eine Cloud-übergreifende KI-Zusammenarbeit, datenschutzwahrende Analysen und die Einhaltung von Vorschriften ermöglichen, ohne die Skalierbarkeit zu beeinträchtigen.
Durch die Erweiterung des Zero-Trust-Designs auf die Rechenschicht schaffen sie eine Grundlage des Vertrauens, der Transparenz und der Verantwortlichkeit für KI-Systeme der nächsten Generation.
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen