
Wie Self-Service-Daten die Geschäftsentscheidungsfindung revolutionieren

Was ist Self Service Data (SSD)?
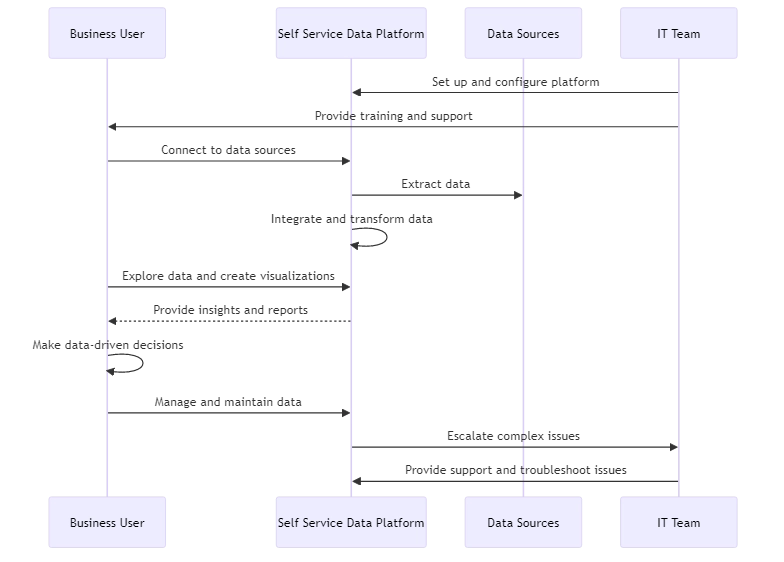
In der heutigen schnelllebigen, datengesteuerten Geschäftswelt benötigen Organisationen effiziente Möglichkeiten, ihre Datenbestände zu nutzen. Self-Service-Daten ermöglichen es Geschäftsanwendern, auf Daten zuzugreifen, sie zu analysieren und zu verwalten – ganz ohne Unterstützung durch IT-Teams. SSD erleichtert es den Nutzern, Daten zu nutzen und schnell Entscheidungen zu treffen.
SSD umfasst zwei Hauptbereiche: SSD-Analyse und SSD-Management. Lassen Sie uns jeden dieser Bereiche näher betrachten.
Self Service Data Analytics
Self-Service-Datenanalysen erlauben es Geschäftsanwendern, Daten zu erkunden, Visualisierungen zu erstellen und eigenständig Erkenntnisse zu gewinnen. Benutzerfreundliche BI- und Analysewerkzeuge ermöglichen die direkte Interaktion mit den Daten. Es ist nicht notwendig, auf Berichte von Datenanalysten zu warten.
Einige der wichtigsten Vorteile der SSD-Analyse sind:
- Schnellere Gewinnung von Erkenntnissen: Benutzer können Geschäftsanfragen ohne Verzögerungen beantworten.
- Erhöhte Agilität: Unternehmen können flexibler auf veränderte Marktbedingungen und Chancen reagieren.
- Entlastung der IT: Da sich die Benutzer selbst bedienen, können sich IT-Teams auf strategischere Initiativen konzentrieren.
Beispielsweise kann ein Marketing-Analyst, der die Effektivität einer kürzlich durchgeführten E-Mail-Kampagne evaluieren möchte, problemlos Informationen abrufen, ein Dashboard mit den wichtigsten Kennzahlen erstellen und Ideen mit seinem Team teilen – alles ohne Hilfe der IT.
Hier ist ein einfaches Python-Skript, das die Verbindung zu einer PostgreSQL-Datenbank demonstriert und Daten einer E-Mail-Kampagne abfragt:
import psycopg2
conn = psycopg2.connect(
host="localhost",
database="marketing",
user="analyst",
password="password"
)
cur = conn.cursor()
cur.execute("""
SELECT
campaign_name,
SUM(num_delivered) AS total_delivered,
SUM(num_opened) AS total_opened,
SUM(num_clicked) AS total_clicked
FROM email_campaigns
WHERE campaign_date
BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY campaign_name;
""")
results = cur.fetchall()
for row in results:
campaign_name, total_delivered, total_opened, total_clicked = row
open_rate = total_opened / total_delivered * 100
click_rate = total_clicked / total_delivered * 100
print(f"{campaign_name}: Delivered={total_delivered}, Open Rate={open_rate:.2f}%, Click Rate={click_rate:.2f}%")
cur.close()
conn.close()
Dieses Skript stellt eine Verbindung zu einer Marketing-Datenbank her. Es analysiert E-Mail-Kampagnendaten und zeigt die wichtigen Kennzahlen für jede Kampagne im ersten Quartal 2023 an.
Self Service Data Management
Self-Service-Analysen befassen sich mit der Nutzung von Daten, während SSD-Management die Verwaltung und Pflege der Daten umfasst. Dazu gehören Aufgaben wie Datenintegration, Qualitätssicherung und Governance.
SSD-Management-Plattformen verfügen über benutzerfreundliche Oberflächen. Benutzer können Datenquellen verbinden, Daten bereinigen und transformieren sowie Geschäftsregeln einfach festlegen. Dadurch können Fachexperten Aufgaben des Datenmanagements übernehmen, ohne tiefgehende technische Kenntnisse zu besitzen.
Die Vorteile des SSD-Managements umfassen:
- Verbesserte Datenqualität: Datenverwalter können ihr Fachwissen einbringen, um sicherzustellen, dass die Daten korrekt und zweckmäßig sind.
- Erhöhte Effizienz: Die Automatisierung von Datenmanagement-Aufgaben durch Self-Service-Tools spart Zeit und Ressourcen.
- Bessere Governance: Benutzer arbeiten innerhalb definierter Rahmenbedingungen, was die Einhaltung von Datenrichtlinien sicherstellt.
Stellen Sie sich einen Vertriebsoperationsmanager vor, der Salesforce-Daten mit dem ERP-System des Unternehmens integrieren muss. Mit einem Self-Service-Datenwerkzeug kann er Daten problemlos zuordnen, Regeln für Änderungen festlegen und automatische Updates planen.
Allerdings erfordern manche Aufgaben im Datenmanagement weiterhin den Einsatz von Code. Hier ist ein Beispiel für die Verwendung von Python und der Pandas-Bibliothek zur Bereinigung und Transformation einer CSV-Datei:
import pandas as pd
df = pd.read_csv('salesforce_data.csv')
# Entferne Zeilen mit fehlenden Werten
df = df.dropna()
# Benenne Spalten um, damit sie dem ERP-System entsprechen
df = df.rename(columns={
'Account': 'CustomerID',
'Industry': 'Vertical',
'AnnualRevenue': 'Revenue'
})
# Konvertiere den Umsatz in einen numerischen Typ
df['Revenue'] = pd.to_numeric(df['Revenue'], errors='coerce')
# Filtere nach aktiven Kunden
df = df[df['Status'] == 'Active']
# Speichere die bereinigten Daten in einer neuen Datei
df.to_csv('salesforce_data_cleaned.csv', index=False)
Dieses Skript bereinigt eine Salesforce-Exportdatei, indem es leere Werte entfernt, Spalten umbenennt, Datenformate ändert und Zeilen organisiert. Das System speichert die bereinigten Daten in einer neuen Datei, sodass sie leicht in das ERP-System geladen werden können.
Schlüsseltechnologien
Mehrere Technologien haben zusammengewirkt, um SSD zur Realität werden zu lassen:
- Cloud Computing: Cloud-Datenlager und Analyseplattformen bieten skalierbare, bedarfsgerechte Ressourcen zur Speicherung und Verarbeitung von Daten. Benutzer können neue Projekte schnell starten, ohne Infrastruktur bereitstellen zu müssen.
- NoSQL-Datenbanken: Flexible, schemalose Datenbanken können verschiedene Datentypen problemlos aufnehmen. Dies ermöglicht es den Nutzern, mit den in Self-Service-Szenarien üblichen halbstrukturierten und unstrukturierten Daten zu arbeiten.
- Datenvisualisierung: Moderne BI-Tools bieten Drag-and-Drop-Oberflächen zur Untersuchung von Daten und zum Erstellen interaktiver Dashboards. Fortschrittliche Funktionen wie natürliche Sprachabfragen machen Analysen auch für Geschäftsanwender zugänglich.
- KI und maschinelles Lernen: Intelligente Algorithmen können komplexe Datenmanagementaufgaben automatisieren und verborgene Erkenntnisse zutage fördern. Funktionen wie intelligente Datenentdeckung und automatisierte Datenaufbereitung rationalisieren die Self-Service-Workflows.
Implementierung von Self Service Data
Obwohl das Potenzial von SSD überzeugend ist, erfordert eine erfolgreiche Implementierung sorgfältige Planung und Ausführung. Einige wichtige Aspekte sind:
- Klare Definition von Rollen und Verantwortlichkeiten: Es sollte klar festgelegt werden, welche Aufgaben Geschäftsanwender eigenständig erledigen können und welche weiterhin von der IT verwaltet werden.
- Bereitstellung von Schulungen und Support: Stellen Sie sicher, dass Geschäftsanwender den Umgang mit Self-Service-Tools beherrschen und die Best Practices im Datenmanagement verstehen. Bieten Sie fortlaufende Schulungen und Supportressourcen an.
- Sicherstellung von Datensicherheit und Compliance: Implementieren Sie strenge Zugriffskontrollen und Daten-Governance-Richtlinien, um Risiken zu minimieren. Auditieren Sie regelmäßig die Benutzeraktivitäten und Berechtigungen.
- Klein anfangen und iterativ vorgehen: Beginnen Sie mit einem konkreten Beispiel, um die Vorteile aufzuzeigen, bevor Self-Service-Optionen allen zugänglich gemacht werden. Sammeln Sie Feedback und optimieren Sie die Prozesse kontinuierlich.
Praxisbeispiele
Viele Organisationen haben SSD-Ansätze erfolgreich eingeführt. Im Folgenden einige Beispiele:
- Procter & Gamble nutzt Self-Service-Analysen, um über 50.000 Mitarbeitern weltweit den direkten Zugriff auf Daten zu ermöglichen. Geschäftsanwender erhalten innerhalb von Minuten Antworten, statt wochenlang auf Berichte zu warten.
- Comcast hat über 2.000 Nutzer, die regelmäßig mit der Self-Service-BI-Plattform interagieren. Das Unternehmen verzeichnete eine Reduzierung der BI-Kosten um 25% und eine Verringerung der Berichtserstellungszeit um 50%.
- Hertz verwendet eine SSD-Management-Plattform, um über 100 Datenquellen zu integrieren. Geschäftsanwender können neue Datensätze in wenigen Stunden statt Monaten einführen – die Datenqualität hat sich dabei erheblich verbessert.
Fazit
Self-Service-Daten verändern grundlegend, wie Organisationen ihre Datenbestände nutzen. Durch die Befähigung von Geschäftsanwendern mit intuitiven Werkzeugen für Datenanalyse und Datenmanagement können Unternehmen Erkenntnisse beschleunigen, ihre Agilität erhöhen und bessere Geschäftsergebnisse erzielen.
Obwohl die Implementierung von SSD ein sorgfältiges Veränderungsmanagement erfordert, sind die Vorteile unbestreitbar. Da die Datenmenge weiter wächst und Unternehmen rasanter arbeiten, wird die Bedeutung von Self-Service-Daten noch zunehmen. Organisationen, die diesen Wandel annehmen, werden hervorragend positioniert sein, um in einer zunehmend datenzentrierten Welt wettbewerbsfähig zu bleiben.
