
Statisches Datenmaskieren
Einführung
Statisches Datenmaskieren schützt sensible Informationen, indem eine sichere, anonymisierte Kopie der Produktionsdaten erstellt wird, bei der vertrauliche Felder durch realistische, aber fiktive Werte ersetzt werden. Da der resultierende Datensatz das ursprüngliche Schema, die Beziehungen und das Datenformat beibehält, ist er weiterhin voll nutzbar für Tests, Analysen, Softwareentwicklung und maschinelles Lernen – ohne persönlich identifizierbare Informationen, Finanzdaten oder Gesundheitsdaten unbefugten Personen zugänglich zu machen. Dieser Ansatz ermöglicht es Organisationen, die Nutzbarkeit der Daten mit strengen Datenschutz- und Compliance-Anforderungen in Einklang zu bringen. Richtlinien von Standards wie dem ISO/IEC 27559 Datenschutzrahmenwerk unterstreichen zudem die Bedeutung robuster Anonymisierungspraktiken.
Dieser Artikel beleuchtet die wesentlichen Prinzipien des statischen Datenmaskierens, erklärt die Unterschiede zur dynamischen Maskierung und untersucht seine wichtige Rolle im Compliance-Management, der Datenschutzsicherung und Risikominderung. Außerdem wird gezeigt, wie DataSunrise die Implementierung durch automatisierte Workflows vereinfacht, die referentielle Integrität komplexer Datensätze sicherstellt und heterogene Datenbankumgebungen – sowohl On-Premises als auch in der Cloud – unterstützt. Darüber hinaus ist statisches Maskieren unverzichtbar für den sicheren Datenaustausch mit Drittanbietern, Forschungspartnern oder Testteams sowie für sichere Cloud-Migrationsprozesse, bei denen nur anonymisierte, compliance-konforme Datensätze das geschützte Produktionsumfeld verlassen.
Statische vs. Dynamische Maskierung: Wichtige Unterschiede
Beide Techniken schützen sensible Felder, erfüllen jedoch unterschiedliche operative Zwecke.
Statisches Datenmaskieren erzeugt eine neue maskierte Kopie der Datenbank, in der sensible Inhalte durch synthetische Werte ersetzt werden – ideal für Entwicklung/Test, Übergabe an Dienstleister und sicheren Datenaustausch.
Im Gegensatz dazu arbeitet dynamische Maskierung zur Laufzeit – maskiert Abfrageergebnisse basierend auf dem Zugriffskontext, ohne die gespeicherten Daten zu verändern – und eignet sich am besten für die Live-Zugriffskontrolle innerhalb von Anwendungen.
| Merkmal | Statische Maskierung | Dynamische Maskierung |
|---|---|---|
| Funktionsweise | Erstellt eine maskierte Datenbankkopie | Ändert Abfrageergebnisse zur Laufzeit |
| Anwendungsfall | Entwicklung/Test, externer Zugriff | Live-Zugriffskontrolle in Produktion |
| Performance | Keine Laufzeitbelastung | Wird “on the fly” angewendet |
| Daten Sicherheit | Sicher für Export/Austausch | Benötigt Laufzeitschutzrichtlinien |
Wann statische Maskierung einsetzen
Statisches Datenmaskieren ist besonders wertvoll, wenn sensible Informationen aus ihrer ursprünglichen Produktionsumgebung herausbewegt werden müssen. Es erlaubt Teams, mit realistischen Datensätzen zu arbeiten und gleichzeitig sicherzustellen, dass keine persönlich identifizierbaren oder regulierten Daten preisgegeben werden. Typische Anwendungsfälle sind:
- Entwickler- und Testumgebungen: Ermöglicht Entwicklern und Ingenieuren, Funktionen mit Daten zu erstellen, zu debuggen und zu optimieren, die reale Komplexität widerspiegeln – ohne tatsächliche Kundenidentitäten, Zahlungsdaten oder vertrauliche Unterlagen offenzulegen.
- Qualitätssicherung und Staging-Systeme: Repliziert Produktionsbedingungen für Funktions-, Leistungs- oder Integrationstests, ohne Compliance- oder Datenschutzrisiken einzuführen.
- Mitarbeiterschulung und Onboarding: Bietet neuen Mitarbeitern und Support-Teams realistische Beispiele, die den Lernerfolg verbessern, während sensible Informationen vollständig geschützt bleiben.
- Externe Zusammenarbeit: Ermöglicht den sicheren Datenaustausch mit Beratern, ausgelagerten Teams, Forschern oder Dienstleistern, ohne Zugang zu regulierten Daten zu gewähren.
- Cloud-Migrationen, Backups und Archivierung: Überträgt oder speichert maskierte Datensätze, um das Risiko bei Bewegung, Replikation oder langfristiger Aufbewahrung zu reduzieren.
Mit DataSunrise können diese Arbeitsabläufe standardisiert und automatisiert werden. Das formatkonservierende Maskieren gewährleistet analytische und relationale Konsistenz, die referentielle Integrität wird über Tabellen und Schemata hinweg beibehalten, und geplante Maskier-Jobs stellen sicher, dass jeder erzeugte Datensatz im Zeitverlauf compliant bleibt. Zusätzlich helfen integrierte Audit- und Richtlinienkontrollen Organisationen, den Maskierungsprozess zu validieren und Compliance gegenüber Prüfern und Regulatoren nachzuweisen.
Wie DataSunrise statisches Datenmaskieren anwendet
DataSunrise unterstützt statisches Maskieren für SQL Server, Oracle, PostgreSQL, MongoDB sowie Cloud-Datenbanken wie Amazon Redshift. Es arbeitet über den DataSunrise-Server (keine Schemaänderungen). Die Einrichtung definiert vier Bereiche: Quell-/Zielinstanzen, zu übertragende Tabellen, Planungsfrequenz und optionale Bereinigungsregeln.
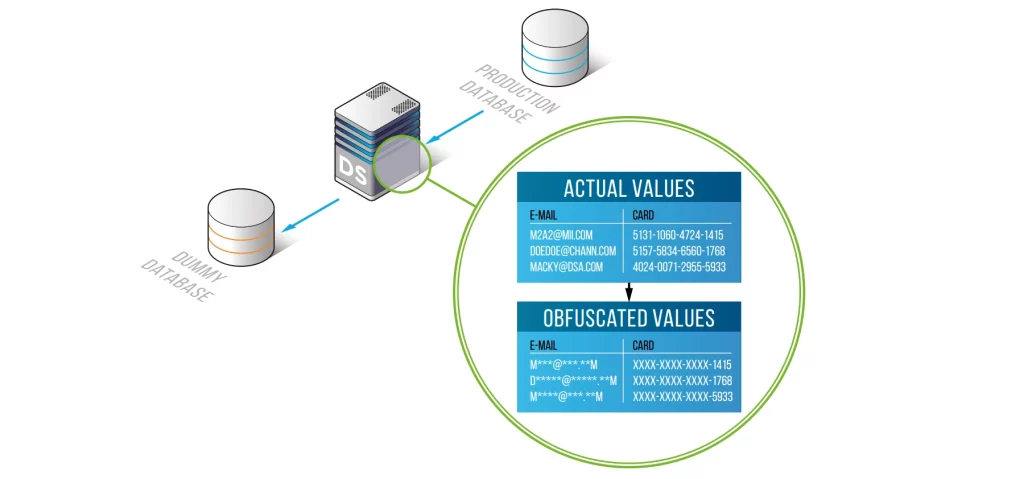
Übliche Maskierungsfunktionen & Anwendungsgebiete
| Funktion | Beispiel Eingabe | Maskiertes Ergebnis | Ideal für |
|---|---|---|---|
| FPE (AES-FFX) | 4111 1111 1111 1111 | 4129 6034 5821 4410 | Simulation von Kreditkartennummern |
| Substring Redact | [email protected] | al***@***.com | E-Mails, Benutzernamen |
| Datumsmischung (+/- 365 Tage) | 1990-05-09 | 1990-12-17 | Geburtsdaten |
| Wörterbuch-Tausch | Chicago | Frankfurt | Stadt-/Länderfelder |
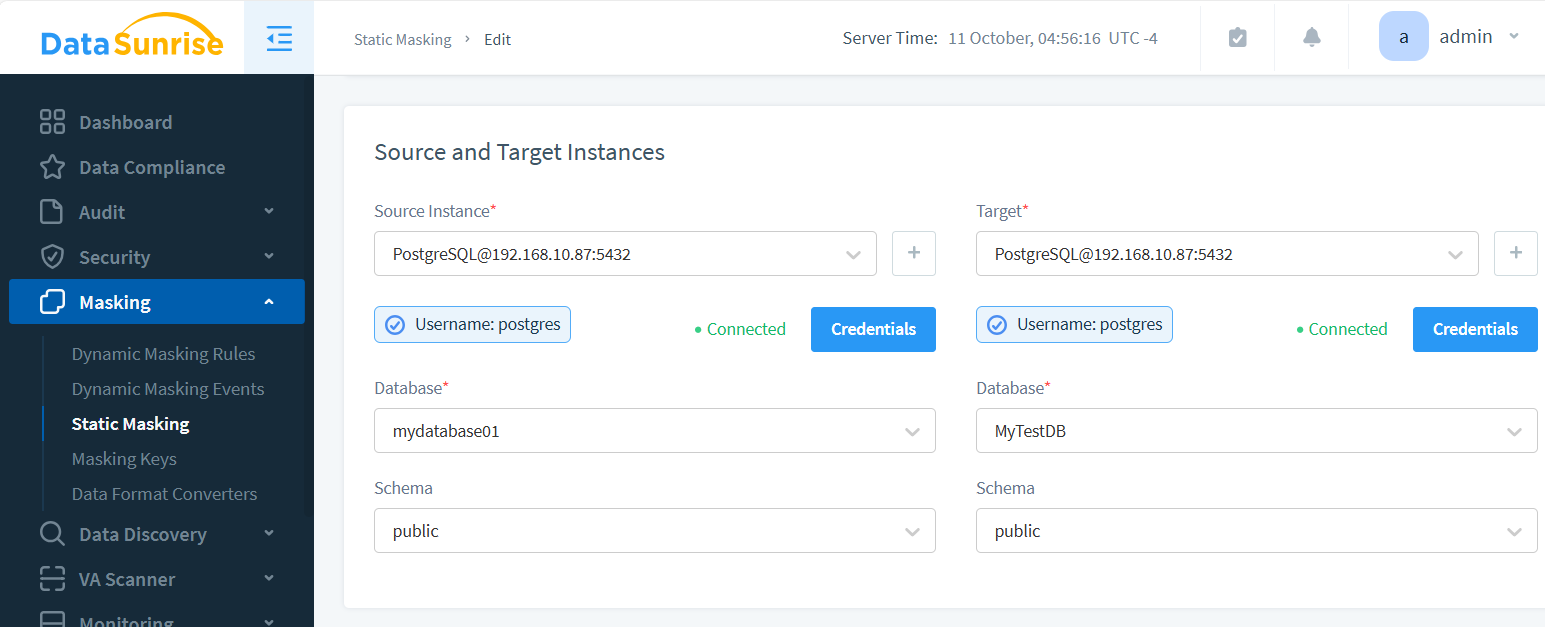
Quell- und Zielinstanzen
Der Maskierungsprozess erzeugt eine neue Instanz mit maskierten Daten. Die Quelle enthält die Originaldaten; das Ziel ist der Speicherort für die verschleierten Daten.
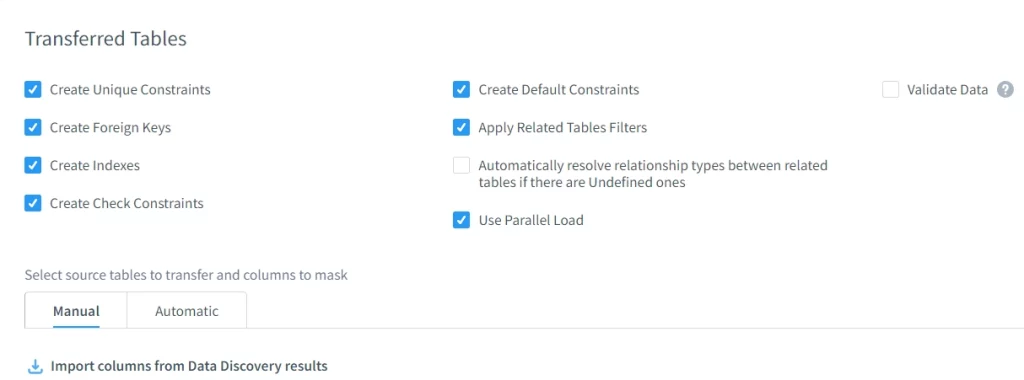
Übertragene Tabellen
DataSunrise erhält bei maskierten Tabellen referentielle Integrität, Constraints, Indizes und Beziehungen – dadurch bleiben die Daten nach der Verschleierung nutzbar.
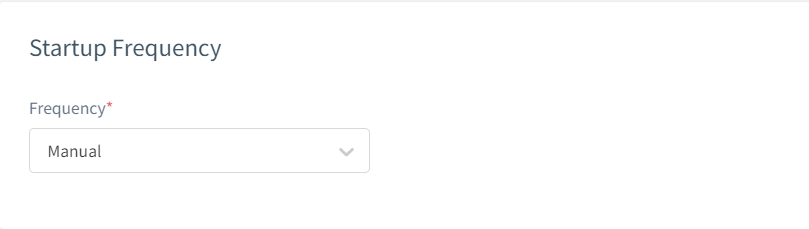
Startfrequenz
Ausführung manuell, einmalig geplant oder in wiederkehrenden Intervallen. Dies automatisiert die Datenaktualisierung und hält Testumgebungen aktuell.
Ergebnisse älter als entfernen
Wenden Sie Aufbewahrung an, um veraltete maskierte Datenbanken zu löschen. Dies spart Speicherplatz und verringert betrieblichen Aufwand.
Simulation des statischen Maskierens in PostgreSQL
So können Sie statisches Maskieren manuell und ohne Automatisierung simulieren:
-- Schritt 1: Erstellen einer maskierten Kopie einer Tabelle
CREATE TABLE customers_masked AS
SELECT
id,
name,
email,
'XXXX-XXXX-XXXX-' || RIGHT(card_number, 4) AS card_number
FROM customers;
-- Schritt 2: Maskieren des E-Mail-Formats
UPDATE customers_masked
SET email = CONCAT(LEFT(email, 2), '***@***.com');
Dies eignet sich für kleine Maskierungsprojekte, bietet jedoch keine formatbewahrende Logik, keine Fremdschlüssel-Überprüfung oder Audit-Protokollierung. DataSunrise automatisiert und skaliert diesen Workflow plattformübergreifend.
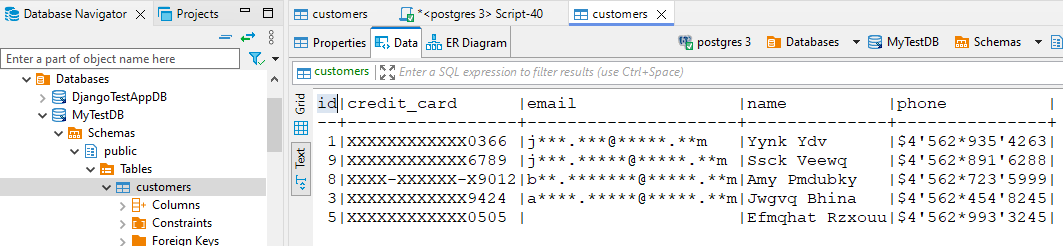
Praktisches Beispiel: PostgreSQL + DataSunrise
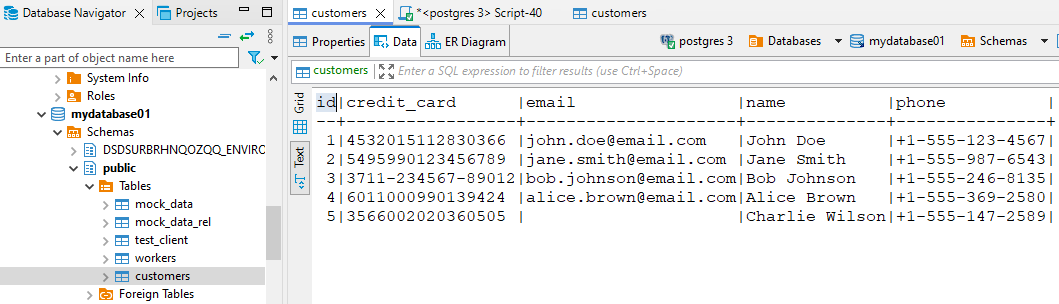
Betrachten Sie eine PostgreSQL-Datenbank mit Kundendaten einschließlich Namen, E-Mails und Kartennummern. Unmaskierte Ansicht:
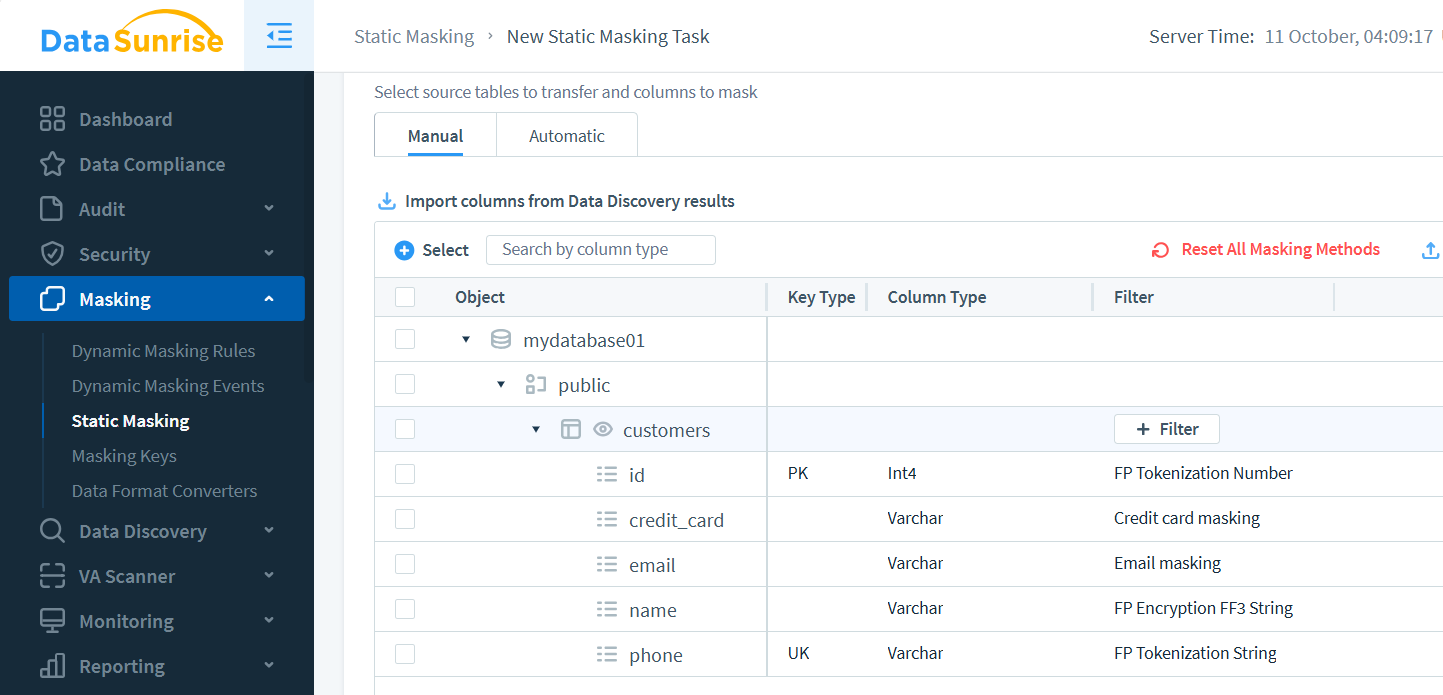
In DataSunrise konfigurieren Sie eine Aufgabe über das Panel für statische Maskierung. Wählen Sie Instanzen aus, definieren Sie Tabellen und wählen Sie Maskierungsmethoden pro Spalte:
Sobald die Aufgabe abgeschlossen ist, sehen Sie die Bestätigung im Aufgabenstatus:
Die Zielinstanz enthält nun eine vollständig maskierte Version der Daten:
Statisches Maskieren mit DataSunrise: Hauptvorteile
- Realistische Daten für Entwicklung/Test
- Formatbewahrende Verschleierung
- Erhaltung der referentiellen Integrität
- Keine Auswirkungen auf Quellsysteme
- GDPR/PCI/HIPAA-konform
Beste Praktiken für statisches Datenmaskieren
Auch mit dem richtigen Werkzeug hängt die Effektivität von präziser Umsetzung ab. Verwenden Sie diese Praktiken, um Maskierung sicher, skalierbar und prüfbar zu halten:
- Maskieren auf Spaltenebene: Beschränken Sie sich nur auf risikoreiche Felder (Namen, E-Mails, Kartennummern), um die Nutzbarkeit zu erhalten.
- Formatbewahrende Methoden für Analysen bevorzugen: Behalten Sie Länge, Typ und referentielle Muster für BI, Joins und Exporte bei.
- Maskieren vor der Auslagerung: Exportieren Sie maskierte Kopien zu S3, Kaltlagerung oder Dienstleistern zur Haftungsminimierung.
- Dokumentieren Sie jeden Job: Verfolgen Sie Quelle/Ziel, betroffene Tabellen, Methoden und Zeitpläne – DataSunrise protokolliert dies für Prüfungen.
- Vierteljährliche Richtlinienüberprüfungen: Aktualisieren Sie Konfigurationen mit sich ändernden Schemata und Vorschriften.
Integrieren Sie statische Maskierung in CI/CD, sodass jede Build-Umgebung automatisch gesäuberte Daten erhält. Das eliminiert fragile Skripte, erzwingt konsistente Logik und hält Testumgebungen synchron mit Produktion – ohne sensible Inhalte preiszugeben.
Richtig umgesetzt wird statisches Maskieren zu einer wiederholbaren, integrierten Kontrollmaßnahme im SDLC – nicht zu einer einmaligen Aufgabe.
Warum statisches Datenmaskieren mit DataSunrise nutzen
- Schützen Sie sensible Felder wie PII, Finanzdaten und Zugangsdaten vor externem Gebrauch.
Statisches Maskieren wandelt vertrauliche Werte unwiderruflich um und stellt sicher, dass exportierte oder geteilte Datensätze keine realen Kundendaten offenbaren – selbst wenn sie die sichere Umgebung verlassen. - Erfüllen Sie Vorgaben wie GDPR, HIPAA und PCI DSS.
Durch Anonymisierung sensibler Elemente an der Quelle erfüllen Organisationen regulatorische Anforderungen hinsichtlich Datenminimierung, sicherem Teilen und Schutz personenbezogener Daten. - Teilen Sie Daten sicher mit Auftragnehmern, Analysten und Drittparteien.
Maskierte Datensätze ermöglichen Zusammenarbeit, ohne Live-Produktionsdaten preiszugeben – das verringert das Risiko von Insider-Missbrauch oder versehentlichen Offenlegungen. - Reduzieren Sie Risiken und unterstützen Sie gleichzeitig realistische Testdatenumgebungen.
Entwickler- und QA-Teams können mit hochqualitativen Datensätzen arbeiten, die statistischen Wert und Geschäftslogik erhalten – ohne Gefahr des Umgangs mit realen Identitäten oder Finanzdetails. - Wahren Sie referentielle Integrität über komplexe Schemata hinweg.
Die Maskierung durch DataSunrise erhält konsistente Beziehungen zwischen Tabellen und Feldern, damit Anwendungen, Analysen und Test-Pipelines nach der Anonymisierung korrekt funktionieren.
Fazit
Statisches Datenmaskieren (SDM) bleibt ein grundlegendes Element moderner Datenschutzframeworks und bietet eine zuverlässige sowie effiziente Methode, sensible Informationen zu anonymisieren und gleichzeitig Struktur, Integrität und Nutzbarkeit der Datensätze zu erhalten. Durch das Ersetzen vertraulicher Werte durch realistische, aber nicht identifizierbare Äquivalente können Organisationen produktionsnahe Daten sicher für Tests, Entwicklung, Analysen und KI-Trainingsmodelle nutzen, ohne persönliche, finanzielle oder firmeneigene Details preiszugeben. Dieser Ansatz sichert nicht nur die Einhaltung globaler Vorschriften wie GDPR, HIPAA, SOX und PCI DSS, sondern gewährleistet auch eine optimale Balance zwischen Datenschutz, Funktionalität und Effizienz in DevOps-Pipelines und unternehmensweiten Datenökosystemen.
Über die Einhaltung von Compliance-Vorgaben hinaus spielt statisches Maskieren eine wichtige Rolle bei komplexen Operationen wie Cloud-Migrationen, Drittanbieter-Kooperationen und abteilungsübergreifendem Datenaustausch. Die zentralisierte Verwaltung und Automatisierung sorgen für konsistente Durchsetzung von Richtlinien über hybride und Multi-Cloud-Umgebungen hinweg – minimieren menschliche Fehler und gewährleisten vollständige Rückverfolgbarkeit während des gesamten Datenlebenszyklus. In Kombination mit ergänzenden Technologien wie dynamischer Maskierung, Database Activity Monitoring (DAM) und intelligenter Datenentdeckung wird SDM zu einem zentralen Bestandteil einer einheitlichen Data-Governance-Strategie.
Innerhalb umfassender Plattformen wie DataSunrise verhindert statisches Maskieren nicht nur unbefugte Datenoffenlegung, sondern erhöht auch die betriebliche Flexibilität durch sicheren Datenaustausch, automatisierte Tests und skalierbare Innovation. Mittels Echtzeitüberwachung, automatisierter Compliance-Durchsetzung und zentraler Audit-Transparenz verwandelt es Datenschutz von einer reaktiven Verpflichtung in eine proaktive Kraft für Vertrauen, Resilienz und nachhaltige digitale Transformation.
