Statisches Data Masking in Vertica
Statisches Data Masking in Vertica spielt eine entscheidende Rolle beim Schutz sensibler Analysedaten, die für leistungsstarke Berichte, Data Science und umfangreiche analytische Arbeitslasten verwendet werden. Vertica-Umgebungen basieren häufig auf produktionsreifen Datensätzen, die persönlich identifizierbare Informationen, Finanzdaten und andere regulierte Datentypen enthalten. Wenn Teams diese Daten außerhalb streng kontrollierter Produktionssysteme kopieren, erhöht sich das Gesamtrisiko sofort.
Dieser Ansatz adressiert das Risiko, indem sensible Werte dauerhaft transformiert werden, bevor Teams die Daten für Entwicklung, Tests, Analysen oder zum Teilen wiederverwenden. Im Gegensatz zu Laufzeitkontrollen entfernt die irreversible Maskierung die Originalwerte vollständig, sodass sensible Informationen niemals geschützte Grenzen verlassen.
Dieser Artikel erklärt, wie irreversible Maskierung auf Vertica-Arbeitslasten angewendet wird, wo native SQL-basierte Techniken an ihre Grenzen stoßen und wie DataSunrise zentrale, prüfbare Maskierungskontrollen in großem Maßstab bereitstellt.
Warum Data Masking in Vertica Analytics wichtig ist
Vertica-Installationen unterstützen üblicherweise mehrere nachgelagerte Verbraucher, darunter BI-Tools, Data Scientists, externe Auftragnehmer und automatisierte Pipelines. Selbst wenn Administratoren Zugriffssteuerungen korrekt konfigurieren, führt das Kopieren roher Analysedaten in Nicht-Produktionssysteme zu unvermeidbaren Expositionsrisiken.
Irreversible Maskierung mindert diese Risiken, indem sichergestellt wird, dass exportierte oder geklonte Datensätze keine echten sensiblen Werte enthalten. Regulierte Umgebungen, die durch DSGVO, HIPAA oder PCI DSS geregelt sind, verlangen oft eine permanente Transformation als Compliance-Maßnahme statt nur als Empfehlung.
Vertica konzentriert sich auf analytische Leistung und nicht auf Zeilenebenen-Transformationen. Daher basieren native Ansätze in der Regel auf benutzerdefinierten SQL-Skripten, manuellen Anpassungen und fragilen Betriebsprozessen.
Native Daten-Transformationstechniken und ihre Grenzen
Vertica bietet keine eingebauten Funktionen für irreversible Maskierung. Teams verlassen sich üblicherweise auf SQL-basierte Updates oder Export-Pipelines, um sensible Werte manuell zu ersetzen.
Gängige native Ansätze umfassen:
- Aktualisieren von Spalten mit transformierten Werten mittels
UPDATE-Anweisungen - Erstellen anonymisierter Tabellenkopien für den Nicht-Produktionsgebrauch
- Anwenden irreversibler Hash-Funktionen oder String-Austauschfunktionen
Obwohl diese Techniken in kleinen Umgebungen funktionieren, führen sie zu beständigen Betriebsproblemen:
- Keine zentrale Übersicht über transformierte Spalten
- Keine wiederverwendbaren Richtlinien über Schemas oder Umgebungen hinweg
- Kein Audit-Trail, der Zeitpunkt und Urheber der Transformation dokumentiert
- Hoher operativer Aufwand bei Schemaänderungen
Im großen Maßstab werden manuelle Transformations-Workflows schwer kontrollierbar und noch schwerer auditierbar.
Wie DataSunrise irreversible Maskierung für Vertica anwendet
DataSunrise fügt eine externe Kontrollschicht hinzu, die permanente Transformationen ohne Veränderung der Vertica-Schemas oder Anwendungslogik durchführt. Administratoren definieren Maskierungsregeln zentral und wenden sie konsistent während kontrollierter Workflows wie Datenkopieren, Klonen oder Export an.
Dieses Modell harmoniert mit umfassenderen Datensicherheits– und Datenbanksicherheits-strategien.
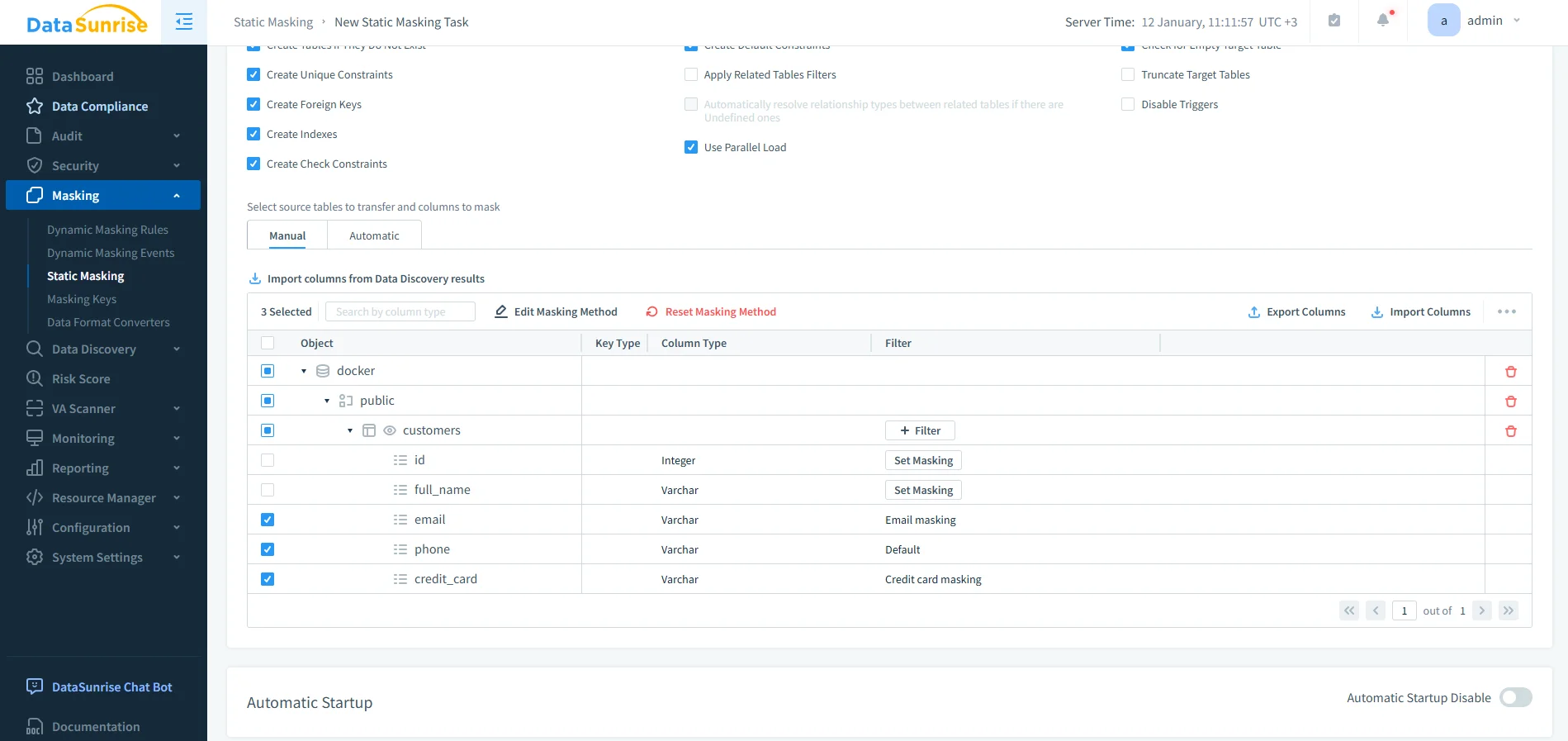
Richtlinienbasierte Spaltenidentifikation
Anstatt einzelne Felder manuell auszuwählen, integriert DataSunrise Data Discovery, um sensible Vertica-Spalten automatisch zu identifizieren. Nach der Klassifizierung werden Transformationsregeln konsistent über Schemas hinweg angewendet.
Dieser Ansatz beseitigt die Abhängigkeit von Benennungskonventionen und minimiert das Risiko, dass neu eingeführte Spalten ungeschützt bleiben.
Format-erhaltende und synthetische Transformationen
Permanente Transformationen unterstützen je nach Datentyp und analytischen Anforderungen mehrere Methoden:
- E-Mail-Ersetzung durch gültige synthetische Adressen
- Tokenisierung von Telefonnummern
- Irreversibles Hashing für Identifikatoren
- Maskierung von Kreditkartendaten bei Erhalt von Länge und Struktur
Diese Transformationen erhalten die analytische Nutzbarkeit, eliminieren jedoch die Exposition realer Daten.
Kontrollierte Ausführung und Performance-Sicherheit
Transformationsaufgaben werden als kontrollierte Operationen mit optionaler paralleler Verarbeitung ausgeführt. Dieses Design ermöglicht es Teams, große Vertica-Datensätze effizient zu verarbeiten, ohne Produktionsanalysen zu beeinträchtigen.
Validierte Ergebnisse nach der Daten-Transformation
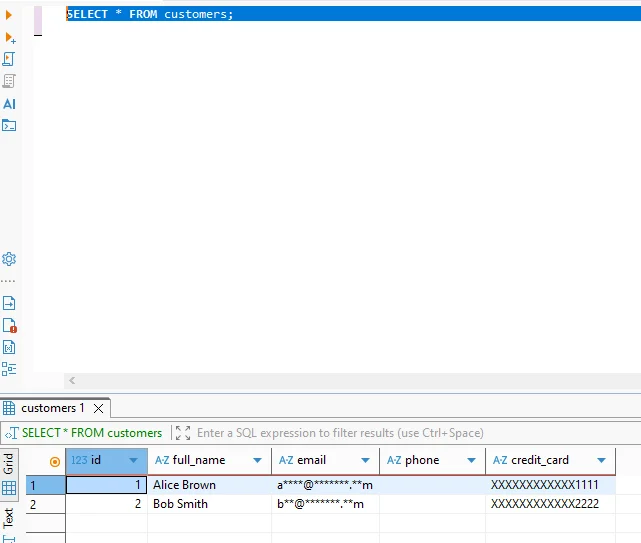
Nach Abschluss der Verarbeitung speichert Vertica alle sensiblen Felder in transformierter Form. Abfragen gegen den resultierenden Datensatz liefern keine Originalwerte zurück, selbst für privilegierte Benutzer nicht.
Die folgende Abfrage zeigt, wie maskierte Daten bei einer Abfrage einer Vertica-Tabelle nach irreversibler Transformation aussehen:
SELECT * FROM customers;
Da die Transformation unwiderruflich ist, bleiben diese Datensätze sicher für Analytics, QA-Umgebungen und externes Teilen.
Auditierung und operative Transparenz
Jede Transformationsoperation erzeugt Audit-Einträge. Diese erfassen:
- Welche Tabellen und Spalten verarbeitet wurden
- Welche Transformationsmethoden angewendet wurden
- Wann die Aufgabe ausgeführt wurde
- Wer die Operation initiiert hat
Diese Transparenz integriert sich direkt in Database Activity Monitoring und Audit Logs, was die Daten-Transformation auditfähig macht.
Dauerhafte Transformation vs. Laufzeit-Maskierung in Vertica
Teams verwechseln häufig irreversible Transformation mit Laufzeit-Maskierung, obwohl beide unterschiedliche Zwecke erfüllen.
Permanentes Maskieren verändert gespeicherte Werte, während Laufzeit-Maskierung Transformationen zur Abfragezeit anwendet.
Irreversible Techniken eignen sich am besten, wenn:
- Daten Produktionsumgebungen verlassen
- Compliance Anonymisierung vorschreibt
- Hochleistungsanalysen Laufzeit-Overhead vermeiden müssen
Compliance-Ausrichtung für Vertica-Umgebungen
| Regulierung | Anforderung | Transformationsrolle |
|---|---|---|
| DSGVO | Unwiderrufliche Anonymisierung personenbezogener Daten | Dauerhafte Entfernung von Identifikatoren |
| HIPAA | De-Identifikation von PHI (geschützten Gesundheitsinformationen) | Sichere Wiederverwendung von Gesundheitsdatensätzen |
| PCI DSS | Schutz von Karteninhaberdaten | Maskierte Analyse- und Testdaten |
| SOX | Kontrollierter Zugang zu Finanzdaten | Sichere Berichterstattung in Nicht-Produktionssystemen |
Diese Kontrollen integrieren sich nahtlos in Workflows, die vom DataSunrise Compliance Manager unterstützt werden.
Fazit: Irreversible Maskierung als Kernkontrolle behandeln
Irreversibles Data Masking in Vertica ist keine optionale Ergänzung. Es ist eine grundlegende Kontrolle für sichere Analysevorgänge. Manuelle SQL-Skripte funktionieren möglicherweise vorübergehend, scheitern jedoch bei Skalierung, Audits und sich wandelnden Compliance-Anforderungen.
Durch die Zentralisierung von Transformations-Workflows mit DataSunrise erreichen Organisationen konsistente Durchsetzung, klare Auditierbarkeit und Übereinstimmung mit modernen Daten-Compliance-Vorschriften. Maskierung wird zu einem regulierten Prozess statt einer fragilen Sammlung von Skripten.
Wenn Ihre Vertica-Umgebung mehrere nachgelagerte Verbraucher unterstützt, sollte permanentes Masking bereits Teil Ihrer Architektur sein. Wenn nicht, ist das kein Zeichen von Mut – es ist ein unkontrolliertes Risiko.
