Wie man Data Governance für Vertica anwendet
Da moderne analytische Plattformen weiterhin an Umfang und Komplexität zunehmen, sehen sich Organisationen zunehmend mit Herausforderungen in Bezug auf Sichtbarkeit, Kontrolle und regulatorische Abstimmung konfrontiert. Da Vertica speziell für hochleistungsfähige analytische Workloads entwickelt wurde, wird die Frage, wie man Data Governance für Vertica anwendet, besonders wichtig. Seine Architektur ermöglicht massive parallele Datenaufnahme und Abfrageausführung. Diese Stärke bringt jedoch auch einzigartige Governance-Anforderungen mit sich, die Teams sowohl auf der Datenebene (Data Plane) als auch auf der Steuerungsebene (Control Plane) adressieren müssen.
In Vertica-Umgebungen ist Data Governance nicht einfach eine Checkliste von Richtlinien; es ist ein technisches Framework, das definiert, wie Daten klassifiziert, zugegriffen, maskiert, überwacht und verifiziert werden. Da Vertica unterschiedliche Datensätze speichert – von Finanzkennzahlen und operationeller Telemetrie bis hin zu kundenbezogenen Identifikatoren – müssen Governance-Schichten sicherstellen, dass sensible Daten den regulatorischen Vorgaben wie GDPR, HIPAA, PCI DSS und SOX entsprechend behandelt werden. Das Verständnis, wie man Data Governance für Vertica anwendet, erfordert daher eine Untersuchung, wie Vertica Daten intern strukturiert, verarbeitet und zugänglich macht. Zusätzlich erzwingt externe Governance-Software wie DataSunrise Klassifizierung, Maskierung, Auditing und Sicherheitskontrollen über verteilte Abfragepfade hinweg. Zur regulatorischen Orientierung können Organisationen die offizielle GDPR-Verordnung sowie die Vertica-Dokumentation konsultieren.
Vertica-Architektur und Überlegungen zur Data Governance
Bei der Bewertung, wie man Data Governance für Vertica anwendet, wird die Datenbankarchitektur selbst zu einem zentralen Faktor. Vertica arbeitet als verteilte, Shared-Nothing spaltenbasierte Engine, bei der Daten segmentiert, komprimiert und in optimierte physische Strukturen projiziert werden. Dieses Design beschleunigt analytische Workloads, bringt aber auch Governance-Komplexität mit sich. Sensible Attribute können in mehreren Projektionen, Replikaten oder Abfragepfaden vorkommen, was traditionelle Governance-Ansätze für zeilenbasierte Speicher nicht vollständig abdecken können.
Darüber hinaus unterstützt Vertica den gleichzeitigen Zugriff durch BI-Tools, ETL-Pipelines, Machine-Learning-Notebooks und Service-Konten. Deshalb muss die Governance sowohl statische Schema-Berechtigungen als auch dynamische Arbeitslastmuster berücksichtigen. Analysten können dieselbe Tabelle von Dashboards, Erkundungstools und Python-Skripten abfragen, und jedes Zugriffsmuster erzeugt eine eigene Risikosignatur. Folglich müssen Organisationen, die Data Governance für Vertica umsetzen, Kontext zur Arbeitslast, Identität, Maskierungsregeln und Verhaltensbaselines in Zugriffsbewertungen einbeziehen.
Datenklassifizierung und Sensitivitätszuordnung in Vertica
Bevor Data-Governance-Kontrollen greift, müssen Organisationen feststellen, wo sensible Daten innerhalb der Vertica-Schemata und Projektionen gespeichert sind. Vertica-Implementierungen sammeln häufig breite analytische Tabellen, stark denormalisierte Strukturen und Projektionsvarianten, in denen sensible Attribute wie PII, PHI, Authentifizierungstoken und Finanzkennzeichen an unerwarteten Stellen auftauchen. Zudem können Schema-Änderungen oder neu generierte Projektionen Informationen offenlegen, die vorher verborgen waren.
DataSunrise erweitert Vertica um die Sensitive Data Discovery und nutzt Mustererkennung, Wörterbücher sowie kontextbezogene Logik, um regulierte Felder automatisch zu klassifizieren. DataSunrise speichert die Entdeckungsergebnisse zentral, damit Governance-Teams eine kontinuierlich aktualisierte Karte sensibler Assets pflegen können. Dieser Klassifikationsdatensatz unterstützt direkt nachgelagerte Komponenten wie Maskierungsregeln, Rollendesign und Compliance-Validierung.
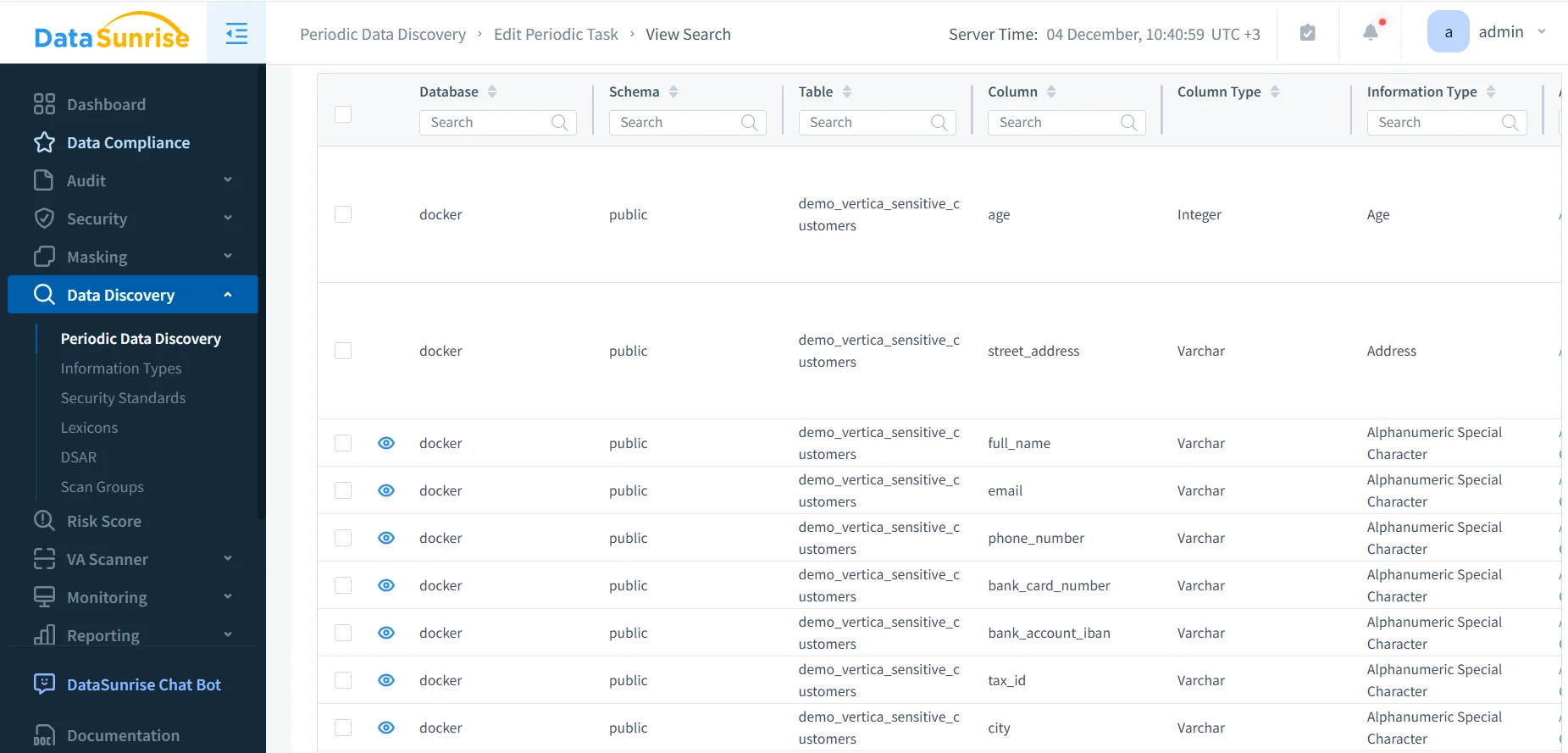
Darüber hinaus können Teams die Klassifikationsausgaben mit internen Richtlinien und weiteren DataSunrise-Ressourcen wie der PII-Klassifizierung und allgemeinen Datensicherheitsanforderungen korrelieren.
Zugriffskontrollverhalten und Durchsetzung von Richtlinien
Vertica bietet ein rollenbasiertes Zugriffskontrollsystem (RBAC). In der Praxis benötigt Governance jedoch granularere und kontextbezogene Richtlinien. Workloads können von Dashboards, ETL-Engines, JDBC-Integrationen oder ML-Pipelines stammen, und jedes kann sensible Daten unterschiedlich aussetzen. Governance muss somit nicht nur Objektberechtigungen, sondern auch Identität, Anfragemodus, Abfrageaufbau und Maskierungskontext bewerten.
DataSunrise fungiert als Richtliniendurchsetzungsebene, indem es den SQL-Verkehr inspiziert, bevor dieser Vertica erreicht. Dies ermöglicht Administratoren die Implementierung fortschrittlicher Kontrollen, die Vertica nativ nicht unterstützt, einschließlich:
- kontextbewusste Maskierung sensibler Felder,
- verhaltensgesteuerte Zugriffsentscheidungen,
- regelbasierte Abfrageblockierung durch Security Rules,
- Risiko-Bewertung für ungewöhnliche oder wirkungsvolle Aktionen.
Selbst wenn eine Vertica-Rolle SELECT-Zugriff auf eine Tabelle gewährt, kann DataSunrise weiterhin bestimmte Spalten maskieren, Abfragen einschränken oder Sichtbarkeiten gemäß den Data-Governance-Anforderungen überschreiben. Konzeptionell kann eine von DataSunrise erzwungene Governance-Richtlinie für Vertica-Workloads folgende Struktur haben:
{
"database_type": "Vertica",
"rule_name": "Maskiere PII in der Kundentabelle",
"match": {
"schema": "public",
"table": "customers",
"columns": ["email", "phone", "ssn"]
},
"actions": [
{
"type": "dynamic_masking",
"profile": "default_pii_mask"
}
],
"conditions": {
"roles_excluded": ["DS_ADMIN", "COMPLIANCE_OFFICER"]
}
}
Dieses Beispiel veranschaulicht, wie eine Governance-Richtlinie Vertica-Objekte beschreibt, auswählt, welche Spalten geschützt werden müssen, und definiert, welche Rollen von Maskierung ausgenommen sind – etwa für Untersuchungen oder Compliance-Zwecke. Das gleiche Muster kann außerdem auf andere Tabellen und Schemata ausgeweitet werden, ohne Anwendungscode oder Vertica-Strukturen ändern zu müssen.
Maskierung und Datenschutz für Vertica-Workloads
Die Anwendung von Data Governance für Vertica erfordert eine konsistente Maskierung über alle Zugriffspfade hinweg. Da Vertica keine eingebaute Maskierungsfunktion bietet, erzwingt DataSunrise Maskierungsregeln auf der Abfrageebene und schützt sensible Daten, unabhängig davon, ob Anfragen von BI-Dashboards, SQL-Tools, Notebooks, kundenspezifischen Anwendungen oder Automatisierungspipelines stammen.
- Dynamische Maskierung ersetzt sensible Werte in Echtzeit während der Abfrageausführung.
- Statische Maskierung erzeugt anonymisierte Vertica-Datensätze für Entwicklung und Tests.
- Kontextbewusste Maskierung passt das Verhalten basierend auf Identität, Quellanwendung oder Arbeitslastklassifikation an.
Da DataSunrise die Maskierung unabhängig von Verticas Speicherstrukturen und Projektionen anwendet, bleibt die Maskierungsebene vorhersagbar, prüfbar und compliant über verschiedenste Nutzungsabläufe hinweg. Verwandte Konzepte finden sich in den Themen Dynamische Datenmaskierung und Statische Maskierung, die Maskierungsmuster auch über Vertica hinaus beschreiben.
Prüfbarkeit und Überwachung von Vertica-Workloads
Vertica führt betriebliche Protokolle in mehreren Systemtabellen. Allerdings gestaltet sich die Zusammenführung dieser Protokolle zu einem einheitlichen Governance-Report schwierig, wenn verteilte Ausführung Abfrageverhalten fragmentiert. Eine einzelne Benutzeraktion kann mehrere interne Schritte über Nodes und Projektionen auslösen. Daher benötigen Governance-Teams normalisierte Audit-Trails, die den vollständigen Kontext jeder Aktion abbilden.
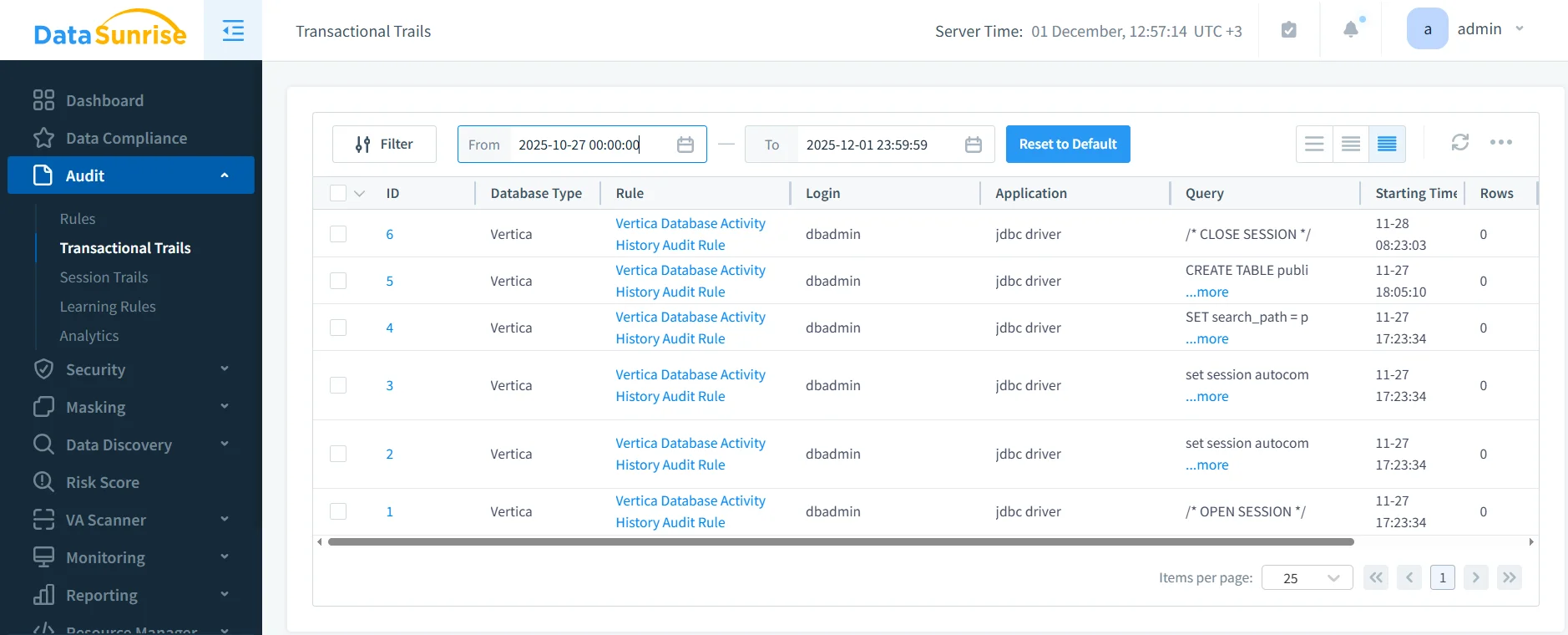
DataSunrise konsolidiert alle Vertica-Zugriffe in einheitliche Audit-Ströme. Es korreliert Sitzungsverhalten, abfragebezogene Aktionen, Maskierungsergebnisse und Auslöser von Sicherheitsregeln. Diese Korrelation ermöglicht eine zuverlässige forensische Rekonstruktion, Richtlinienvalidierung und Compliance-Dokumentation. Außerdem können Teams diese Informationen mit Datenbank-Aktivitätsüberwachung, detaillierten Audit-Logs und automatisierten Berichten über den Compliance Manager ergänzen.
Governance-Funktionalitäten: Vertica vs. DataSunrise
Die folgende Tabelle stellt die nativen Funktionen von Vertica den governance-fokussierten Erweiterungen durch DataSunrise gegenüber. Dieser Vergleich zeigt genau auf, wo ergänzende Kontrollen die Art und Weise verbessern, wie Organisationen Data Governance für Vertica und verwandte Plattformen umsetzen.
| Governance-Bereich | Native Fähigkeit von Vertica | DataSunrise-Erweiterung |
|---|---|---|
| Datenklassifizierung | Manuelle Prüfung; begrenzte Muster | Automatisierte Sensitive Data Discovery mit PII/PHI-Erkennung |
| Zugriffs-Governance | Basis RBAC | Kontextbewusste Zugriffsentscheidungen + Security Rules |
| Datenmaskierung | Keine Maskierungsfunktionalität | Dynamische Maskierung und statische Maskierung mit Richtlinienlogik |
| Audit und Überwachung | Fragmentierte Protokolle | Vereinheitlichte Audit-Trails und plattformübergreifende Korrelation |
| Compliance-Bereitschaft | Manuelle Zusammenstellung von Nachweisen | Automatisierte Berichte für GDPR, HIPAA, PCI DSS, SOX |
Fazit: Wie man Data Governance für Vertica erfolgreich anwendet
Das Verständnis, wie man Data Governance für Vertica anwendet, erfordert eine technische Sicht auf Klassifizierung, Zugriffsdurchsetzung, Maskierungsverhalten und Audit-Sichtbarkeit. Da Vertica als verteilte analytische Engine fungiert, gehen seine Governance-Bedürfnisse über natives RBAC und Logging hinaus. Externe Durchsetzungsebenen wie DataSunrise bieten konsistente Maskierung, zentralisierte Audits, automatisierte Entdeckung und Verhaltenskontrollen, die Vertica mit regulatorischen und internen Richtlinien in Einklang bringen. Mit dieser Governance-Architektur wird Vertica zu einer sicheren, konformen Basis für großskalige Analysen und Unternehmensintelligenz.
