
Zugriffskontrollstrategien in GenAI & LLM Systemen

Da generative KI und Large Language Models (LLMs) zu einem integralen Bestandteil von Unternehmensabläufen werden, ist es nicht länger optional, den Zugriff auf die zugrunde liegenden Daten zu sichern. Diese Systeme nehmen wertvolle Datensätze auf, verarbeiten sie und generieren auf deren Basis Erkenntnisse – oft einschließlich persönlicher, proprietärer oder regulierter Informationen. Ohne effektive Zugriffskontrolle riskieren Organisationen Datenlecks, Compliance-Verstöße und eine Verunreinigung nachgelagerter Modelle.
Herausforderungen der Zugriffskontrolle in GenAI
Im Gegensatz zu traditionellen Datenbanken arbeiten GenAI-Systeme mit unstrukturierten und semi-strukturierten Daten, wodurch perimeterbasierte Kontrollen unzureichend sind. Ein einzelner Prompt kann mehrere Ebenen von Vektorsuchen, Retrieval-Augmented Generation (RAG) und Zusammenfassungen auslösen. Der Zugriff muss in jeder Phase gesteuert werden: beim Einlesen des Prompts, der Abfrage des Vektorspeichers, der Modellverarbeitung und der Ergebnisausgabe. Diese Komplexität erfordert granulare und adaptive Sicherheitsstrategien.
Der Bedarf an mehrschichtigen Kontrollen in KI-Arbeitsprozessen wird unter anderem in Ressourcen wie Googles Secure AI Framework (SAIF) und NISTs AI Risk Management Framework widergespiegelt, die Transparenz, Governance und Rückverfolgbarkeit als Kernprinzipien empfehlen.
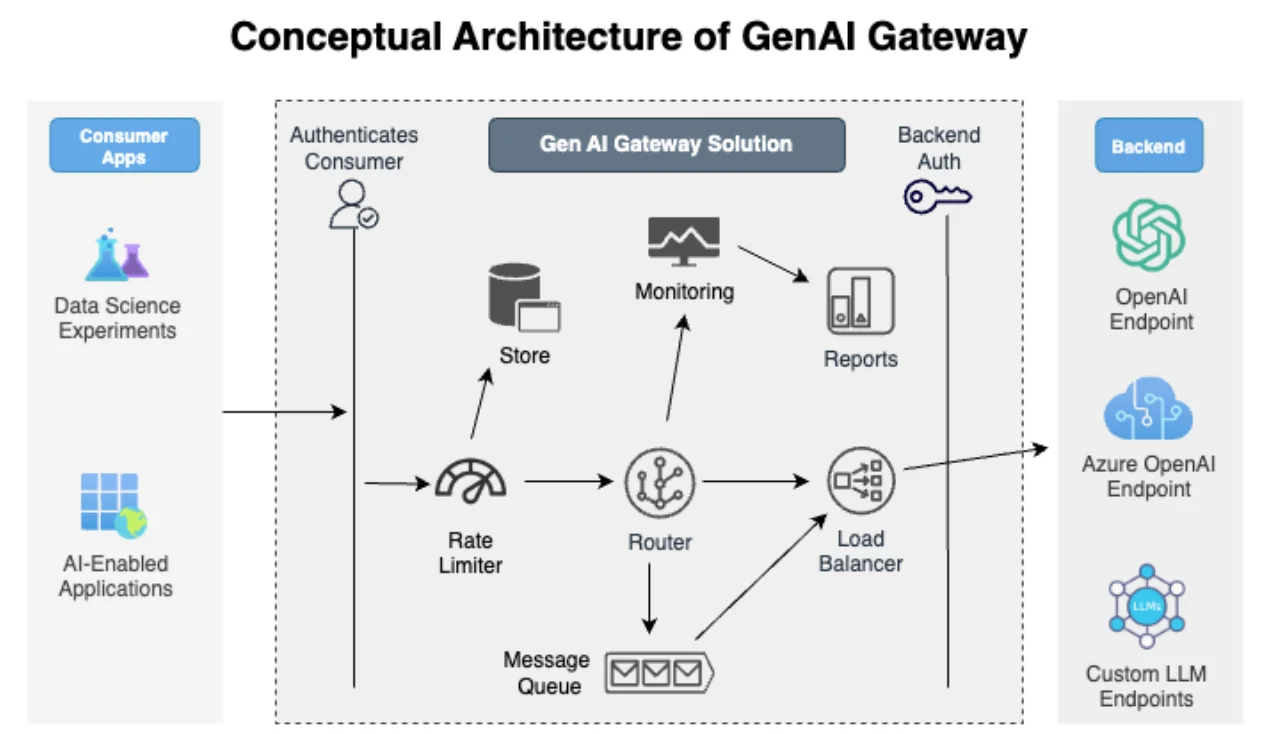
Dynamische Zugriffskontrollen mit Echtzeit-Auditing
Moderne KI-Systeme profitieren von Echtzeit-Datenbank-Aktivitätsüberwachung, die es Organisationen ermöglicht, unautorisierte Abfragen in dem Moment zu erkennen und zu blockieren, in dem sie auftreten. Das Echtzeit-Auditing protokolliert nicht nur jede Interaktion, sondern ermöglicht auch verhaltensbasierte Warnmeldungen und die Durchsetzung von Richtlinien. Beispielsweise kann das System, wenn ein Benutzer unerwartet hochsensible Datensätze abfragt oder eine ungewöhnliche Eingabestruktur verwendet, die Ausführung aussetzen oder Ausgaben automatisch maskieren.
-- Beispiel für eine richtlinienbasierte Audit-Regel in PostgreSQL mit pgAudit
ALTER SYSTEM SET pgaudit.log = 'all';
-- In Kombination mit der Vektorspeicher-Protokollierung:
INSERT INTO audit_logs (timestamp, user_id, action, query)
VALUES (NOW(), current_user, 'embedding_lookup', 'SELECT * FROM vector_index WHERE ...');
Audit-Protokolle können an SIEM-Systeme weitergeleitet oder in Lösungen wie DataSunrise’s Lernregeln und Alarmierungsfunktionen integriert werden, um proaktiv verteidigt zu werden. Für cloudnative LLM-Anwendungen unterstützen Plattformen wie Azure Monitor und Amazon CloudWatch ebenfalls die Echtzeit-Überwachung und -Behebung.
Dynamische Datenmaskierung für Prompt- und Ausgabe-Schutz
Eine effektive Methode zum Schutz sensibler Inhalte in sowohl Eingaben als auch Ausgaben ist die dynamische Datenmaskierung. Wenn beispielsweise ein Prompt persönliche Identifikatoren oder finanzielle Aufzeichnungen enthält, stellt die Maskierung sicher, dass LLMs relevante Aufgaben (wie Klassifizierung oder Zusammenfassung) ausführen können, ohne dass die Rohdaten den Benutzern oder sogar dem Modell im Klartext zugänglich gemacht werden.
-- Pseudo-Regel zur Maskierung der Kreditkartennummer vor der Einspeisung in das Modell
IF query CONTAINS 'credit_card_number' THEN
MASK 'credit_card_number' USING 'XXXX-XXXX-XXXX-####';
END IF;
Dieser Ansatz ermöglicht es LLMs, ihre Funktionalität beizubehalten, während gleichzeitig das Risiko einer Datenoffenlegung minimiert wird – besonders nützlich in Kundenservice-, Personal- und juristischen Dokumenten-Workflows. Open-Source-Projekte wie Presidio von Microsoft demonstrieren, wie Maskierung und Anonymisierung in NLP-Pipelines integriert werden können.
Datenentdeckung zur Klassifizierung und Steuerung von Eingabequellen
Zugriffskontrolle beginnt mit Sichtbarkeit. Datenentdeckungstools können automatisch Datenbanken, Objektspeicher und Dokumenten-Repositorien durchsuchen, um sensible Felder zu klassifizieren, bevor sie das Modell überhaupt erreichen. Dies umfasst PII, PHI, finanzielle Daten, Quellcodes oder geistiges Eigentum.
In Kombination mit KI-Pipelines können entdeckte Ressourcen getaggt, segmentiert oder je nach Klassifizierung durch unterschiedliche Verarbeitungsabläufe geleitet werden. Dies stellt sicher, dass nicht-sensible Dokumente freier behandelt werden, während Inhalte mit hohem Risiko strengeren Richtlinien unterliegen. Ähnliche Prinzipien werden im IBM AI Governance Playbook zur Verwaltung strukturierter und unstrukturierter Daten in regulierten Branchen erläutert.
Einhaltung von Regularien und Richtliniendurchsetzung
Regelwerke wie DSGVO, HIPAA und PCI DSS schreiben spezifische Vorgaben zum Datenzugriff, zur Datenspeicherung und zum Umgang mit Daten vor. Für KI-Systeme erstrecken sich diese Anforderungen auf Trainingsdatensätze, Modellinferenz und Audit-Protokolle. Compliance-Manager müssen diese Anforderungen direkt in die Zugriffskontrolllogik integrieren.
So könnte eine DSGVO-konforme LLM-Plattform beispielsweise:
- Benutzeridentifikatoren in Prompts unkenntlich machen, sofern keine ausdrückliche Einwilligung vorliegt
- Inferenzprotokolle nach 30 Tagen löschen
- Die Nutzung von Modellen nach Region oder Rechtsgebiet einschränken
Mithilfe von automatisierten Compliance-Tools können Organisationen diese Richtlinien im großen Maßstab durchsetzen, ohne zusätzlichen operativen Aufwand zu verursachen. Weitere Leitlinien finden sich zudem in den EDPB AI-Compliance-Empfehlungen und in den Richtlinien der ICO zu KI und Datenschutz.
Sicherheitsorientierte GenAI-Architektur
Effektive Zugriffskontrollstrategien werden nicht nachträglich hinzugefügt – sie sind in die Systemarchitektur integriert. Dies umfasst:
- Proxy-basierte Firewalls, die Prompt-Payloads inspizieren
- Rollbasierte Zugriffskontrolle (RBAC), die einschränkt, wer welche Modelle und Datensätze abfragen darf
- Das Prinzip der minimalen Rechtevergabe bei API-Schlüsseln, Modellzugriffsbereichen und Datensatznutzung
So können beispielsweise Entwickler, die an einem Chatbot-Modell arbeiten, nur auf synthetische oder maskierte Datenproben zugreifen, während Compliance-Beauftragte vollständige Audit-Protokolle einsehen können, ohne den Rohtext der Prompts zu sehen. Dies entspricht den in MITREs AI Security Framework beschriebenen Praktiken zum Schutz von Lernsystemen vor Prompt Injection und Modellmissbrauch.
Fazit
Die Implementierung robuster Zugriffskontrollstrategien in GenAI & LLM Systemen erfordert eine Kombination aus Datenentdeckung, Durchsetzung, Überwachung und Governance. Echtzeit-Auditprotokolle, dynamische Datenmaskierung und klassifizierungsbasierte Richtlinien müssen harmonisch zusammenwirken, um Daten im Transit und im Ruhezustand zu schützen.
Lösungen wie DataSunrise’s Audit- und Maskierungs-Engine bieten die nötige Flexibilität und Intelligenz, um GenAI-Ökosysteme zu schützen, ohne dabei Leistung oder Compliance zu beeinträchtigen. Da immer mehr Unternehmen LLMs in ihre Arbeitsabläufe integrieren, wird die Fähigkeit, Zugriffskontrollen dynamisch anzupassen, entscheidend für Innovation und Rechenschaftspflicht sein.
Weitere Einblicke finden Sie im LLM-Sicherheitsreferenzleitfaden, in den grundlegenden Datensicherheitsprinzipien sowie in Frameworks wie der OpenCRE Knowledge Map für KI-Bedrohungen.
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen