Anonymisation des Données dans Vertica
L’anonymisation des données dans Vertica est une capacité critique pour les organisations qui s’appuient sur l’analyse à grande échelle tout en traitant des informations personnelles, financières ou réglementées. Vertica est conçu pour des charges de travail analytiques à haute performance, ce qui le rend idéal pour le reporting BI, l’analyse client et la science des données. En même temps, cette flexibilité analytique augmente le risque que des valeurs sensibles apparaissent dans les résultats des requêtes, les exportations ou les systèmes en aval si elles ne sont pas correctement protégées.
Dans les environnements Vertica modernes, plusieurs équipes et outils accèdent souvent aux mêmes jeux de données. Les analystes explorent les données de manière interactive, les tableaux de bord BI exécutent des requêtes planifiées, et les pipelines d’apprentissage automatique extraient de grands ensembles de données d’entraînement. Parce que ces charges de travail fonctionnent sur des tables partagées, les organisations doivent s’assurer que les attributs sensibles restent protégés sans interrompre les flux analytiques ni dupliquer les données.
Cet article explique comment l’anonymisation des données peut être mise en œuvre dans Vertica en utilisant une application centralisée, des techniques d’anonymisation dynamiques et un audit continu, avec DataSunrise Data Compliance agissant comme couche de protection.
Pourquoi l’Anonymisation des Données est Nécessaire dans Vertica
L’architecture de Vertica privilégie la performance analytique. Les données sont stockées dans des conteneurs ROS en colonnes, les mises à jour récentes résident dans le WOS, et les projections créent plusieurs dispositions physiques optimisées des mêmes tables logiques. Bien que cette conception accélère les requêtes, elle complique également la protection fine des données.
En pratique, plusieurs facteurs augmentent le besoin d’anonymisation :
- Les tables analytiques larges combinent souvent des métriques avec des données PII ou de paiement.
- Les projections répliquent des colonnes sensibles à travers plusieurs nœuds.
- Les clusters partagés supportent les outils BI, les tâches ETL, les notebooks et les pipelines ML.
- Les requêtes SQL ad-hoc contournent les couches de reporting contrôlées.
- Le contrôle natif RBAC gère l’accès mais pas la visibilité au niveau des valeurs.
Dès qu’un utilisateur dispose d’un accès SELECT, Vertica retourne toutes les valeurs sélectionnées en clair. Par conséquent, les organisations nécessitent des mécanismes d’anonymisation qui fonctionnent au moment de la requête plutôt que de se fier uniquement aux permissions statiques.
Pour un contexte supplémentaire, consultez la documentation officielle de l’architecture Vertica.
Architecture Centralisée d’Anonymisation pour Vertica
Une approche éprouvée pour l’anonymisation des données dans Vertica est de séparer l’application des règles du stockage. Dans ce modèle, les applications clientes se connectent via une passerelle centralisée au lieu de se connecter directement à Vertica. Chaque requête SQL est inspectée, les règles d’anonymisation sont évaluées, et les valeurs sensibles sont transformées avant que les résultats ne soient retournés.
Beaucoup d’organisations mettent en œuvre cette architecture en utilisant DataSunrise comme proxy transparent. Parce que l’application des règles se fait hors de Vertica, les schémas, projections et la logique applicative restent inchangés.
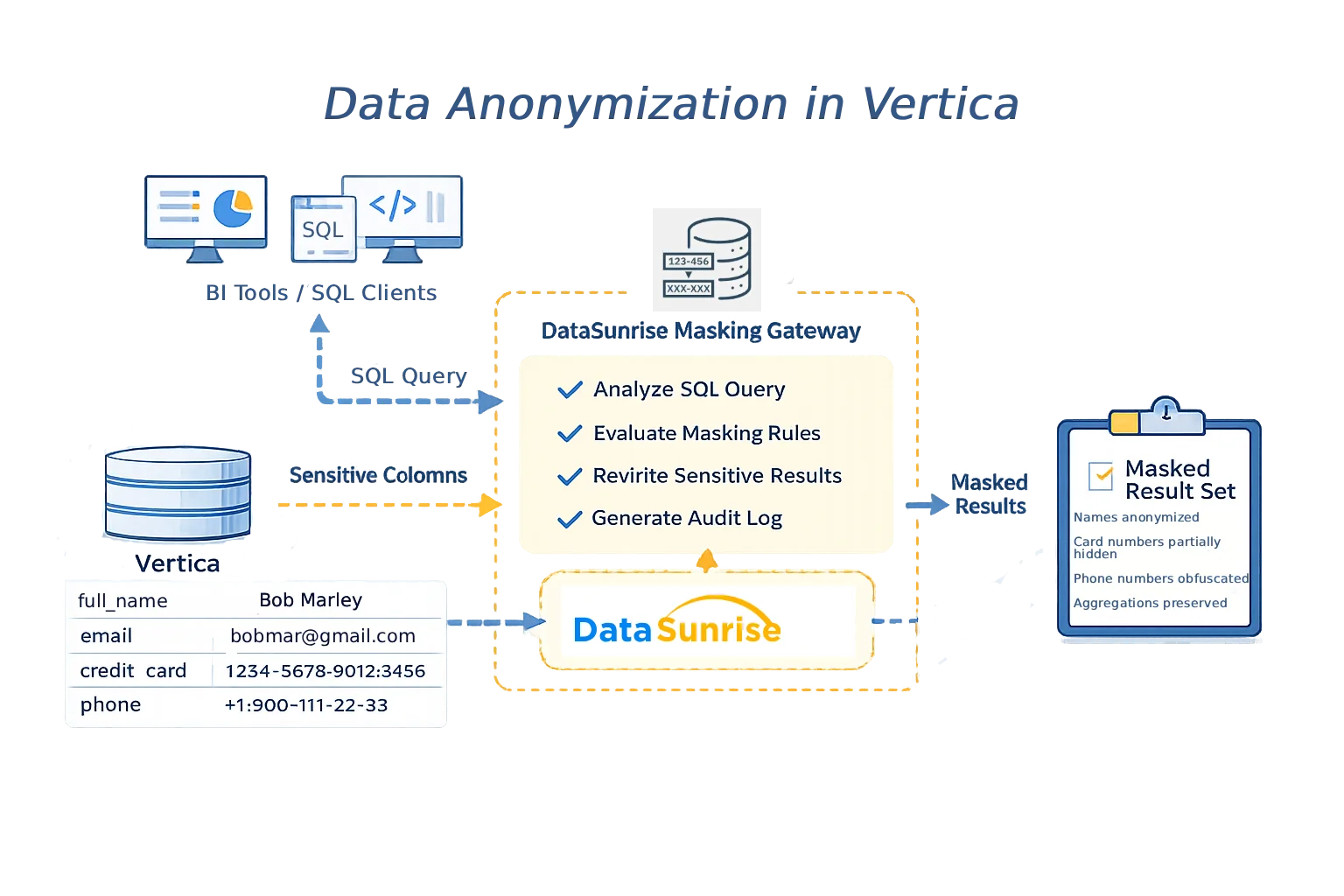
Architecture centralisée d’anonymisation des données pour Vertica avec DataSunrise comme couche d’application des règles.
Cette architecture garantit que les politiques d’anonymisation s’appliquent uniformément à tous les chemins d’accès, incluant les clients SQL, les outils BI et les pipelines automatisés.
L’Anonymisation Dynamique comme Technique Principale
L’anonymisation dynamique est la technique la plus efficace pour protéger les données sensibles dans les analyses Vertica. Au lieu de modifier définitivement les valeurs stockées, l’anonymisation se produit au moment de la requête. Lorsqu’une requête fait référence à des colonnes sensibles, les valeurs retournées sont remplacées par des représentations anonymisées.
DataSunrise fournit des mécanismes intégrés de masquage dynamique des données et d’anonymisation qui évaluent chaque requête selon les règles de politique. Ces règles peuvent prendre en compte :
- L’utilisateur ou rôle de base de données
- Le type d’application cliente
- L’environnement (production, staging, analytique)
- La classification de confidentialité de chaque colonne
Parce que l’anonymisation a lieu uniquement dans le jeu de résultats, Vertica continue à traiter les valeurs réelles en interne. En conséquence, les agrégations, jointures, filtres et calculs restent exacts.
Configuration des Règles d’Anonymisation dans Vertica
Pour appliquer l’anonymisation, les administrateurs définissent une règle ciblant une instance Vertica et spécifiant quelles colonnes nécessitent une protection. Les règles font généralement référence aux schémas ou tables identifiés grâce à une découverte automatisée.
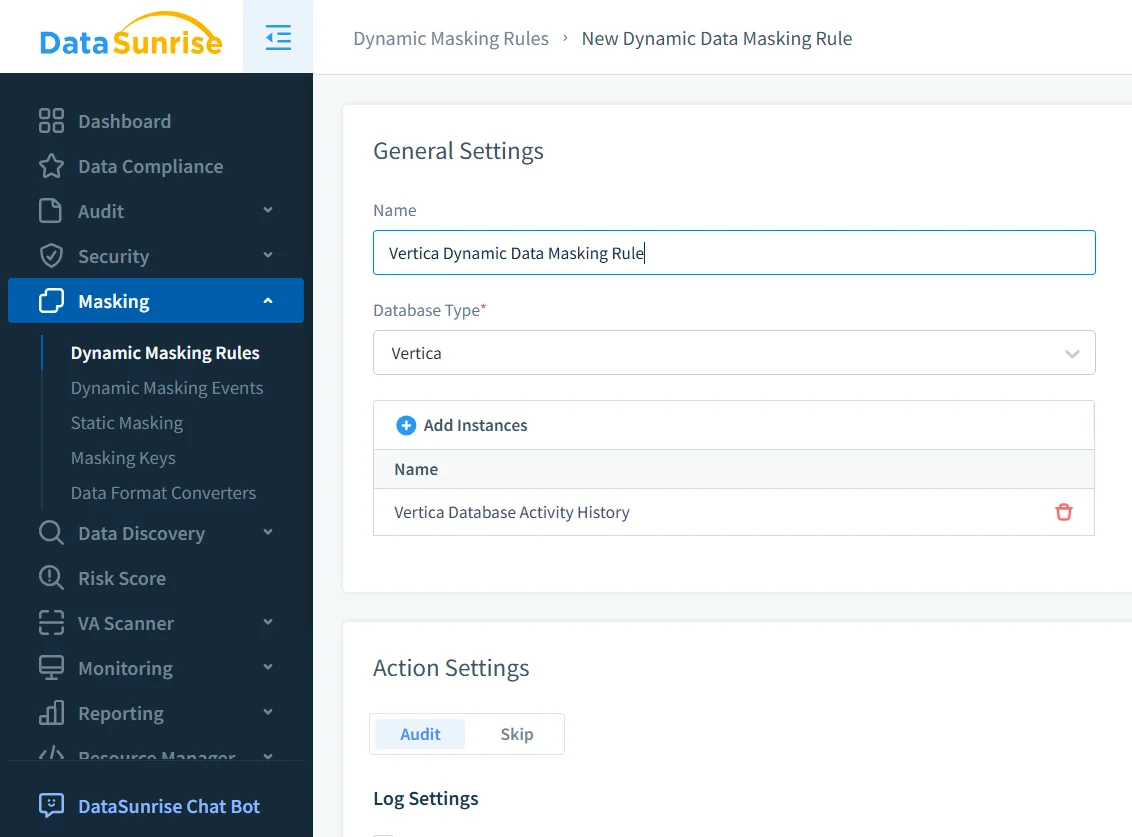
Configuration de règle d’anonymisation pour une instance de base de données Vertica.
À ce stade, les administrateurs activent l’audit des événements d’anonymisation et définissent la manière dont les valeurs sensibles doivent être transformées. Les formats peuvent inclure l’anonymisation complète, le masquage partiel ou la tokenisation selon les exigences politiques.
Résultats Anonymisés dans les Requêtes Analytiques
Du point de vue de l’utilisateur, l’anonymisation est transparente. Les requêtes utilisent du SQL standard, et Vertica les exécute normalement. Toutefois, les valeurs sensibles apparaissent anonymisées dans les résultats retournés.
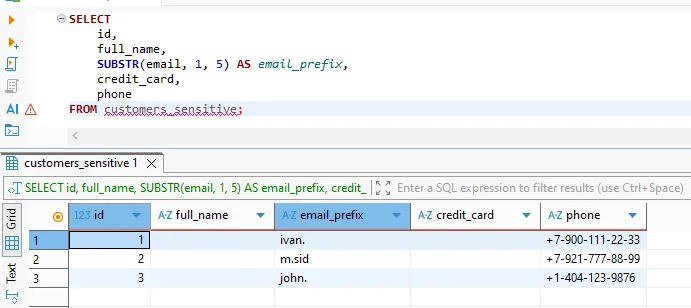
Jeu de résultats anonymisé renvoyé au client tout en préservant la structure analytique.
Ce comportement permet aux analystes de travailler avec des jeux de données réalistes tout en empêchant l’exposition des identités réelles. En même temps, les pipelines d’apprentissage automatique peuvent consommer des données d’entraînement anonymisées sans divulguer d’informations personnelles.
Audit et Visibilité de l’Accès Anonymisé
L’anonymisation doit rester auditée pour soutenir la conformité. Les organisations doivent pouvoir démontrer quand l’anonymisation a eu lieu, quelles règles ont été appliquées, et qui a accédé aux données.
DataSunrise enregistre automatiquement les événements d’audit pour chaque requête anonymisée. Ces enregistrements s’intègrent avec la surveillance des activités de base de données et peuvent être exportés vers des systèmes SIEM.
L’audit centralisé simplifie la conformité avec des réglementations telles que le RGPD, la HIPAA et la SOX, tout en soutenant les enquêtes internes.
Comparaison des Approches d’Anonymisation dans Vertica
| Approche | Description | Adaptabilité pour Vertica |
|---|---|---|
| Anonymisation statique | Créer des jeux de données anonymisés de manière permanente | Maintenance élevée, flexibilité limitée |
| Vues SQL | Anonymiser les données via des vues prédéfinies | Facilement contournées par des requêtes directes |
| Logique côté application | Anonymisation intégrée dans les applications BI ou autres | Couverture inconstante |
| Anonymisation dynamique | Anonymiser les résultats au moment de la requête | Centralisé et évolutif |
Bonnes Pratiques pour l’Anonymisation des Données dans Vertica
- Commencer par une découverte automatisée pour identifier les champs sensibles.
- Appliquer l’anonymisation au niveau des requêtes plutôt que de copier les données.
- Tester les politiques en utilisant de véritables charges BI et analytiques.
- Examiner régulièrement les journaux d’audit à la recherche de schémas d’accès inattendus.
- Aligner l’anonymisation avec des stratégies plus larges de sécurité des données.
Conclusion
L’anonymisation des données dans Vertica offre une méthode évolutive et adaptée à l’analyse pour protéger les informations sensibles. En anonymisant dynamiquement les valeurs au moment de la requête, les organisations réduisent les risques d’exposition tout en conservant la puissance et la flexibilité de Vertica.
Avec DataSunrise agissant comme couche centralisée d’application des règles, les équipes bénéficient d’une protection cohérente, d’une visibilité complète des audits, et d’une conformité réglementaire à travers les tableaux de bord, scripts et pipelines d’apprentissage automatique—sans sacrifier la performance.
